15 вещей, которые нужно знать о словарях Python
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2020-03-07 06:35

1. Что такое словарь в Python?
Словари в Python – это изменяемые отображения ссылок на объекты, доступные по ключу. Словари представляют собой структуры данных, в которых уникальные ключи отображают значения. Ключ и значение разделяются двоеточием, пары ключ-значения отделяются запятыми, а словарь целиком ограничивается фигурными скобками {}. Ниже приведены три словаря, содержащие сведения о населении пяти крупнейших городов Германии, список покупок и оценки студентов.
>>> population = {'Berlin': 3748148, 'Hamburg': 1822445, 'Munich': 1471508, 'Cologne': 1085664, 'Frankfurt': 753056 } >>> products = {'table': 120, 'chair': 40, 'lamp': 14, 'bed': 250, 'mattress': 100} >>> grades = {'Alba': 9.5, 'Eduardo': 10, 'Normando': 3.5, 'Helena': 6.5, 'Claudia': 7.5} Три этих словаря будут использоваться далее в руководстве. Чтобы лучше разобраться в теме словарей, советуем проходить этот текст вместе с интерпретатором Python.
2. Создание словаря при помощи dict()
Кроме прямого описания, словари также можно создавать с помощью встроенной функции dict(). Эта функция принимает любое количество именованных аргументов.
>>> students_ages = dict(Amanda=27, Teresa=38, Paula=17, Mario=40) >>> print(students_ages) {'Amanda': 27, 'Teresa': 38, 'Paula': 17, 'Mario': 40} Методы можно комбинировать:
>>> students_ages = dict({'Amanda': 27, 'Teresa': 38}, Paula=17, Mario=40) >>> print(students_ages) {'Amanda': 27, 'Teresa': 38, 'Paula': 17, 'Mario': 40} Другой вариант – использовать список кортежей. Каждый кортеж должен содержать два объекта: ключ и значение.
>>> students_ages = dict([('Amanda', 27), ('Teresa', 38), ('Paula', 17), ('Mario', 40)]) >>> print(students_ages) {'Amanda': 27, 'Teresa': 38, 'Paula': 17, 'Mario': 40} Наконец, можно создать словарь, используя два списка. Вначале строим итератор кортежей с помощью функции zip(). Затем используем ту же функцию dict() для построения словаря.
>>> students = ['Amanda', 'Teresa', 'Paula', 'Mario'] >>> ages = [27, 38, 17, 40] >>> students_ages = dict(zip(students, ages)) >>> print(students_ages) {'Amanda': 27, 'Teresa': 38, 'Paula': 17, 'Mario': 40} 3. Получение значений из словаря
Для доступа к значениям словаря мы не можем использовать числовой индекс (как в случае со списками или кортежами). Однако схема извлечения значения похожа на индексацию: вместо числа в квадратные скобки подставляется ключ. При попытке получить доступ к значению с помощью несуществующего ключа будет вызвана ошибка KeyError.
Чтобы избежать получения исключения с несуществующими ключами, можно воспользоваться методом dict.get(key[, default]). Этот метод возвращает значение для ключа, если ключ находится в словаре, иначе возвращает значение по умолчанию default. Если значение по умолчанию не задано, метод возвращает None (но никогда не возвращает исключение).
>>> print(population['Munich']) 1471508 >>> print(population[1]) Traceback (most recent call last): File "<stdin>", line 1, in <module> KeyError: 1 >>> print(population['Stuttgart']) Traceback (most recent call last): File "<stdin>", line 1, in <module> KeyError: 'Stuttgart' >>> print(population.get('Munich')) 1471508 >>> print(population.get('Stuttgart')) None >>> print(population.get('Stuttgart', 'Not found')) Not found 4. Добавление элементов в словарь
Добавить одиночный элемент в словарь можно следующим образом:
>>> products['pillow'] = 10 >>> print(products) {'table': 120, 'chair': 40, 'lamp': 14, 'bed': 250, 'mattress': 100, 'pillow': 10} Для добавления нескольких элементов одновременно можно применять метод dict.update([other]). Он обновляет словарь парами ключ-значение из other, перезаписывая существующие ключи.
>>> products.update({'shelf': 70, 'sofa': 300}) >>> print(products) {'table': 120, 'chair': 40, 'lamp': 14, 'bed': 250, 'mattress': 100, 'pillow': 10, 'shelf': 70, 'sofa': 300} >>> grades.update(Violeta=5.5, Marco=6.5, Paola=8) >>> print(grades) {'Alba': 9.5, 'Eduardo': 10, 'Normando': 3.5, 'Helena': 6.5, 'Claudia': 7.5, 'Violeta': 5.5, 'Marco': 6.5, 'Paola': 8} >>> population.update([('Stuttgart', 632743), ('Dusseldorf', 617280)]) >>> print(population) {'Berlin': 3748148, 'Hamburg': 1822445, 'Munich': 1471508, 'Cologne': 1085664, 'Frankfurt': 753056, 'Stuttgart': 632743, 'Dusseldorf': 617280} Как показано выше, метод update() может принимать в качестве аргумента не только словарь, но и список кортежей или именованные аргументы.
5. Изменение элементов словаря
Изменим значение элемента, обратившись к ключу с помощью квадратных скобок ([]). Для изменения нескольких значений сразу есть метод .update(). Он перезаписывает существующие ключи.
Увеличим цену дивана на 100 единиц и изменим оценки двух студентов.
>>> print(products) {'table': 120, 'chair': 40, 'lamp': 14, 'bed': 250, 'mattress': 100, 'pillow': 10, 'shelf': 70, 'sofa': 300} >>> products['sofa'] = 400 >>> print(products) {'table': 120, 'chair': 40, 'lamp': 14, 'bed': 250, 'mattress': 100, 'pillow': 10, 'shelf': 70, 'sofa': 400} >>> print(grades) {'Alba': 9.5, 'Eduardo': 10, 'Normando': 3.5, 'Helena': 6.5, 'Claudia': 7.5, 'Violeta': 5.5, 'Marco': 6.5, 'Paola': 8} >>> grades.update({'Normando': 2.5, 'Violeta': 6}) >>> print(grades) {'Alba': 9.5, 'Eduardo': 10, 'Normando': 2.5, 'Helena': 6.5, 'Claudia': 7.5, 'Violeta': 6, 'Marco': 6.5, 'Paola': 8} 6. Удаление элементов словаря
Для удаления элемента из словаря можно использовать либо del dict[key], либо dict.pop(key[, default]). В первом случае из словаря удаляется соответствующая пара. Или, если такого ключа нет, возвращается KeyError.
>>> print(population) {'Berlin': 3748148, 'Hamburg': 1822445, 'Munich': 1471508, 'Cologne': 1085664, 'Frankfurt': 753056, 'Stuttgart': 632743, 'Dusseldorf': 617280} >>> del population['Ingolstadt'] Traceback (most recent call last): File "<stdin>", line 1, in <module> KeyError: 'Ingolstadt' >>> del population['Dusseldorf'] >>> print(population) {'Berlin': 3748148, 'Hamburg': 1822445, 'Munich': 1471508, 'Cologne': 1085664, 'Frankfurt': 753056, 'Stuttgart': 632743} Метод dict.pop(key[, default]) удаляет из словаря элемент с заданным ключом и возвращает его значение. Если ключ отсутствует, метод возвращает значение default . Если значение default не задано и ключа не существует, метод pop() вызовет исключение KeyError.
>>> print(population) {'Berlin': 3748148, 'Hamburg': 1822445, 'Munich': 1471508, 'Cologne': 1085664, 'Frankfurt': 753056, 'Stuttgart': 632743} >>> population.pop('Stuttgart') 632743 >>> print(population) {'Berlin': 3748148, 'Hamburg': 1822445, 'Munich': 1471508, 'Cologne': 1085664, 'Frankfurt': 753056} >>> print(population.pop('Ingolstadt', 'Value not found')) Value not found >>> population.pop('Garching') Traceback (most recent call last): File "<stdin>", line 1, in <module> KeyError: 'Garching' 7. Проверка наличия ключа
Чтобы проверить, существует ли ключ в словаре, достаточно воспользоваться операторами принадлежности:
>>> print(population) {'Berlin': 3748148, 'Hamburg': 1822445, 'Munich': 1471508, 'Cologne': 1085664, 'Frankfurt': 753056} >>> print('Ingolstadt' in population) False >>> print('Munich' in population) True >>> print('Ingolstadt' not in population) True >>> print('Munich' not in population) False 8. Копирование словаря
Чтобы скопировать словарь, можно использовать метод словаря copy(). Этот метод возвращает поверхностную копию словаря. Мы должны быть осторожны с такими копиями: если словарь содержит списки, кортежи или множества, то в созданной копии будут только ссылки на объекты из оригинала.
>>> students = {'Marco': 173, 'Luis': 184, 'Andrea': 168} >>> students_2 = students.copy() # поверхностная копия >>> students_2['Luis'] = 180 >>> print(students) {'Marco': 173, 'Luis': 184, 'Andrea': 168} >>> print(students_2) {'Marco': 173, 'Luis': 180, 'Andrea': 168} >>> students_weights = {'Marco': [173, 70], 'Luis': [184, 80], 'Andrea': [168, 57]} >>> students_weights_2 = students_weights.copy() >>> students_weights_2['Luis'][0] = 180 >>> print(students_weights) {'Marco': [173, 70], 'Luis': [180, 80], 'Andrea': [168, 57]} Изменение в списке students_2 затронуло список students, так как список, содержащий вес и рост, содержит ссылки, а не дубликаты. Чтобы избежать этой проблемы, создадим глубокую копию, используя функцию copy.deepcopy(x):
>>> import copy >>> students_weights = {'Marco': [173, 70], 'Luis': [184, 80], 'Andrea': [168, 57]} >>> students_weights_2 = copy.deepcopy(students_weights) >>> students_weights_2['Luis'][0] = 180 >>> print(students_weights) {'Marco': [173, 70], 'Luis': [184, 80], 'Andrea': [168, 57]} >>> print(students_weights_2) {'Marco': [173, 70], 'Luis': [180, 80], 'Andrea': [168, 57]} При использовании глубокого копирования создается полностью независимая копия.
Важно помнить, что оператор = не создаёт копию словаря. Он присваивает другое имя, но относящееся к тому же словарю, т. е. любое изменение нового словаря отражается на исходном.
>>> fruits = {'Orange': 50, 'Apple': 65, 'Avocado': 160, 'Pear': 75} >>> fruits_2 = fruits >>> fruits_2.pop('Orange') 50 >>> print(fruits) {'Apple': 65, 'Avocado': 160, 'Pear': 75} 9. Определение длины словаря
Чтобы выяснить сколько пар ключ-значение содержится в словаре, достаточно воспользоваться функцией len():
>>> print(population) {'Berlin': 3748148, 'Hamburg': 1822445, 'Munich': 1471508, 'Cologne': 1085664, 'Frankfurt': 753056} >>> print(len(population)) 5 10. Итерация словаря
10.1 Итерация ключей
Чтобы перебрать все ключи, достаточно провести итерацию по элементам объекта словаря:
>>> for city in population: ... print(city) ... Berlin Hamburg Munich Cologne Frankfurt 10.2 Итерация значений
Вычислим сколько людей проживает в пяти крупнейших городах Германии. Применим метод dict.values(), возвращающий список значений словаря:
>>> print(population) {'Berlin': 3748148, 'Hamburg': 1822445, 'Munich': 1471508, 'Cologne': 1085664, 'Frankfurt': 753056} >>> inhabitants = 0 >>> for number in population.values(): ... inhabitants += number ... >>> print(inhabitants) 8880821 В пяти крупнейших городах Германии живут почти 9 миллионов человек.
10.3 Итерация ключей и значений
В случае, если нужно работать с ключами и значениями одновременно, обратимся к методу dict.items(), возвращающему пары ключ-значение в виде списка кортежей.
>>> min_grade = 10 >>> min_student = '' >>> for student, grade in grades.items(): ... if grade < min_grade: ... min_student = student ... min_grade = grade ... >>> print(min_student) Normando 11. Генераторы словарей
Цикл for удобен, но сейчас попробуем более эффективный и быстрый способ – генератор словарей. Синтаксис выглядит так: {key: value for vars in iterable}
Отфильтруем товары из словаря products по цене ниже 100 евро, используя как цикл for, так и генератор словарей.
>>> print(products) {'table': 120, 'chair': 40, 'lamp': 14, 'bed': 250, 'mattress': 100, 'pillow': 10, 'shelf': 70, 'sofa': 400} >>> products_low = {} >>> for product, value in products.items(): ... if value < 100: ... products_low.update({product: value}) ... >>> print(products_low) {'chair': 40, 'lamp': 14, 'pillow': 10, 'shelf': 70} >>> products_low = {product: value for product, value in products.items() if value < 100} >>> print(products_low) {'chair': 40, 'lamp': 14, 'pillow': 10, 'shelf': 70} Результаты идентичны, при этом генератор словарей записан компактнее.
12. Вложенные словари
Вложенные словари – это словари, содержащие другие словари. Мы можем создать вложенный словарь так же, как мы создаем обычный словарь, используя фигурные скобки.
Следующий вложенный словарь содержит информацию о пяти известных произведениях искусства. Как можно заметить, значениями словаря являются другие словари.
# вложенный словарь, содержащий информацию об известных произведениях искусства works_of_art = {'The_Starry_Night': {'author': 'Van Gogh', 'year': 1889, 'style': 'post-impressionist'}, 'The_Birth_of_Venus': {'author': 'Sandro Botticelli', 'year': 1480, 'style': 'renaissance'}, 'Guernica': {'author': 'Pablo Picasso', 'year': 1937, 'style': 'cubist'}, 'American_Gothic': {'author': 'Grant Wood', 'year': 1930, 'style': 'regionalism'}, 'The_Kiss': {'author': 'Gustav Klimt', 'year': 1908, 'style': 'art nouveau'}} Создадим вложенный словарь, используя dict(), передавая пары ключ-значение в качестве именованных аргументов.
# вложенный словарь, созданный при помощи dict() works_of_art = dict(The_Starry_Night={'author': 'Van Gogh', 'year': 1889, 'style': 'post-impressionist'}, The_Birth_of_Venus={'author': 'Sandro Botticelli', 'year': 1480, 'style': 'renaissance'}, Guernica={'author': 'Pablo Picasso', 'year': 1937, 'style': 'cubist'}, American_Gothic={'author': 'Grant Wood', 'year': 1930, 'style': 'regionalism'}, The_Kiss={'author': 'Gustav Klimt', 'year': 1908, 'style': 'art nouveau'}) Для доступа к элементам во вложенном словаре указываем ключи, используя несколько квадратных скобок ([ ][ ]).
>>> print(works_of_art['Guernica']['author']) Pablo Picasso >>> print(works_of_art['American_Gothic']['style']) regionalism 13. Альтернативные типы данных
Модуль collections предоставляет альтернативные типы данных: OrderedDict, defaultdict и Counter, расширяющие возможности обычных словарей. У нас есть подробная статья о модуле collections, которая помогает не изобретать уже известные структуры данных Python. Здесь мы остановимся на трех типах данных, наиболее близких к словарям.
13.1. OrderedDict
OrderedDict содержит словарь, хранящий порядок добавления ключей. В Python 3.6+ словари запоминают порядок, а для предыдущих версий Python можно использовать OrderedDict.
>>> import collections >>> dictionary = collections.OrderedDict({'hydrogen': 1, 'helium': 2, 'carbon': 6, 'oxygen': 8}) >>> print(type(dictionary)) <class 'collections.OrderedDict'> С OrderedDict можно использовать операции с элементами, методы и функции, как при работе с обычным словарем.
13.2. defaultdict
defaultdict – подкласс словаря, присваивающий значение по умолчанию при отсутствии ключа. Он никогда не выдаст KeyError, если мы попробуем получить доступ к элементу, который отсутствует в словаре. Будет создана новая запись. В приведенном ниже примере ключи создаются с различными значениями в зависимости от функции, используемой в качестве первого аргумента.
>>> default_1 = collections.defaultdict(int) >>> default_1['missing_entry'] 0 >>> print(default_1) defaultdict(<class 'int'>, {'missing_entry': 0}) >>> default_2 = collections.defaultdict(list, {'a': 1, 'b': 2}) >>> default_2['missing_entry'] [] >>> print(default_2) defaultdict(<class 'list'>, {'a': 1, 'b': 2, 'missing_entry': []}) >>> default_3 = collections.defaultdict(lambda : 'Not given', a=1, b=2) >>> default_3['missing_entry'] 'Not given' >>> print(default_3) defaultdict(<function <lambda> at 0x7f75d97d6840>, {'a': 1, 'b': 2, 'missing_entry': 'Not given'}) >>> import numpy as np >>> default_4 = collections.defaultdict(lambda: np.zeros(2)) >>> default_4['missing_entry'] array([0., 0.]) >>> print(default_4) defaultdict(<function <lambda> at 0x7f75bf7198c8>, {'missing_entry': array([0., 0.])}) 13.3. Counter
Counter – подкласс словаря, подсчитывающий объекты хеш-таблицы. Функция возвращает объект Counter, в котором элементы хранятся как ключи, а их количество в виде значений. Эта функция позволяет подсчитать элементы списка:
>>> letters = ['a', 'a', 'c', 'a', 'a', 'b', 'c', 'a'] >>> counter = collections.Counter(letters) >>> print(counter) Counter({'a': 5, 'c': 2, 'b': 1}) >>> print(counter.most_common(2)) [('a', 5), ('c', 2)] Как показано выше, мы можем легко получить наиболее часто используемые элементы с помощью метода most_common([n]). Этот метод возвращает список n наиболее часто встречающихся элементов и их количество.
14. Создание Pandas DataFrame из словаря
Pandas DataFrame – это двумерная таблица со строками и столбцами, создаваемая в библиотеке анализа данных pandas. Это очень мощная библиотека для работы с данными. Ранее мы рассказывали как можно анализируовать данные с помощью одной строки на Python в pandas (да и вообще о разных трюках работы с библиотекой).
Объект DataFrame создается с помощью функции pandas.DataFrame(), принимающей различные типы данных (списки, словари, массивы numpy). В этой статье разберем только те способы создания датафрейма, которые предполагают использование словарей.
14.1. Создание DataFrame из словаря
Создадим DataFrame из словаря, где ключами будут имена столбцов, а значениями – данные столбцов:
import pandas as pd # создать Pandas DataFrame из словаря - ключ (название столбца) - значение (информация в столбце) df = pd.DataFrame({'name': ['Mario', 'Violeta', 'Paula'], 'age': [22, 27, 19], 'grades': [9, 8.5, 7]}) print(df) 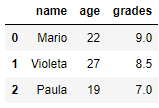
По умолчанию индексом является номер строки (целое число, начинающееся с 0). Изменим индексы, передав список индексов в DataFrame.
# создать Pandas DataFrame из словаря - ключ (название столбца) - значение (информация в столбце) - с собственными индексами import pandas as pd df_index = pd.DataFrame({'name': ['Mario', 'Violeta', 'Paula'], 'age': [22, 27, 19], 'grades': [9, 8.5, 7]}, index=['student_1', 'student_2', 'student_3']) print(df_index) 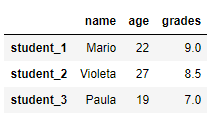
14.2. Создание DataFrame из списка словарей
Список словарей также может быть использован для создания DataFrame, где ключи – имена столбцов. Как и раньше, мы можем изменять индексы, передавая список индексов в функцию DataFrame.
# создать Pandas DataFrame из списка словарей - ключи (названия столбцов) с собственными индексами import pandas as pd df_2 = pd.DataFrame([{'name': 'Mario', 'age': 22, 'grades':9}, {'name': 'Violeta', 'age': 27, 'grades':8.5}, {'name': 'Paula', 'age': 19, 'grades':7}], index=['student_1', 'student_2', 'student_3']) print(df_2) 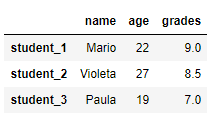
15. Функции в Pandas, использующие словари
В Pandas есть несколько функций, использующих словари в качестве входных значений, например, pandas.DataFrame.rename и pandas.DataFrame.replace.
15.1. pandas.DataFrame.rename
Эта функция возвращает DataFrame с переименованными метками осей. На вход можно подать словарь, в котором ключи – старые имена, а значения – новые. Метки, не содержащиеся в словаре, остаются неизменными.
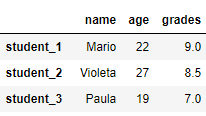
# изменить метки индекса в df_2 import pandas as pd df_2 = pd.DataFrame([{'name': 'Mario', 'age': 22, 'grades':9}, {'name': 'Violeta', 'age': 27, 'grades':8.5}, {'name': 'Paula', 'age': 19, 'grades':7}], index=['student_1', 'student_2', 'student_3']) df_2.rename(index={'student_1': 'new_label_1', 'student_2': 'new_label_2'}, inplace=True) print(df_2) 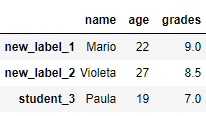
15.2. pandas.DataFrame.replace
Эта функция меняет значения DataFrame на другие значения. Мы можем использовать словарь с функцией замены для изменения DataFrame, где ключи представляют собой существующие записи, а значения – новые.
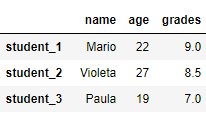
# заменить Mario --> Maria и Paula --> Paola import pandas as pd df_2 = pd.DataFrame([{'name': 'Mario', 'age': 22, 'grades':9}, {'name': 'Violeta', 'age': 27, 'grades':8.5}, {'name': 'Paula', 'age': 19, 'grades':7}], index=['student_1', 'student_2', 'student_3']) df_2.replace({'Mario': 'Maria', 'Paula': 'Paola'}, inplace=True) print(df_2) 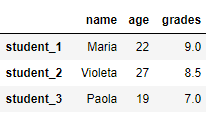
***
Итак, мы рассмотрели разные способы создания словаря, базовые операции (добавление, изменение, удаление элементов). Также мы узнали когда стоит использовать глубокую копию словаря вместо поверхностной. Научились строить матрёшки – вложенные словари. Такие конструкции встретятся, когда вы будете качать, например, с ВКонтакте через его API разнообразную информацию.
Если вы любите Python, Библиотека программиста подготовила ещё много интересных материалов об этом замечательном языке:
- Программирование на Python: от новичка до профессионала
- Самые эффективные ресурсы и материалы для изучения Python
- Инструменты Python: лучшая шпаргалка для начинающих
Свежие материалы доступны по тегу Python.
Источники
Телеграм: t.me/ainewsline
Источник: proglib.io