
Одной из таких новых идей является применение компанией Vicarious рекурсивных кортикальных сетей (Recursive Cortical Network, RCN), которые черпают вдохновение в нейробиологии. Эта модель претендовала на то, чтобы чрезвычайно эффективно ломать текстовую капчу, тем самым вызвав вокруг себя много разговоров. Поэтому я решил написать несколько статей, каждая из которых объясняет определенный аспект этой модели. В этой статье мы поговорим о ее структуре и о том, каким образом происходит генерация изображений, представленных в материалах основной статьи о RCN [5]. Эта статья предполагает, что вы уже знакомы со сверточными нейронными сетями, поэтому я буду проводить множество аналогий с ними.
Чтобы подготовиться к осознанию RCN, нужно понять, что RCN основаны на идее отделения формы (эскиза объекта) от внешнего вида (его текстуры) и что это генеративная модель, а не дискриминативная, поэтому мы можем генерировать изображения с помощью нее, как в генеративно-состязательных сетях. Кроме того, используется параллельная иерархическая структура, подобная архитектуре сверточных нейронных сетей, которая начинается с этапа определения формы целевого объекта на в нижних слоях, а затем уже на верхнем слое добавляется его внешний вид. В отличие от сверточных нейронных сетей, рассматриваемая нами модель опирается на богатую теоретическую базу графических моделей, вместо взвешенных сумм и градиентного спуска. А сейчас давайте углубимся в особенности структуры RCN.
Слои признаков
Первый тип слоев в RCN называется слоем признаков. Мы будем рассматривать модель постепенно, поэтому давайте пока предположим, что вся иерархия модели состоит только из слоев этого типа, уложенных друг на друга. Будем двигаться от абстрактных понятий высокого уровня к более конкретным особенностям нижних слоев, как показано на Рисунке 1. Слой такого типа состоит из нескольких узлов, расположенных в двумерном пространстве, аналогично картам признаков в сверточных нейронных сетях.

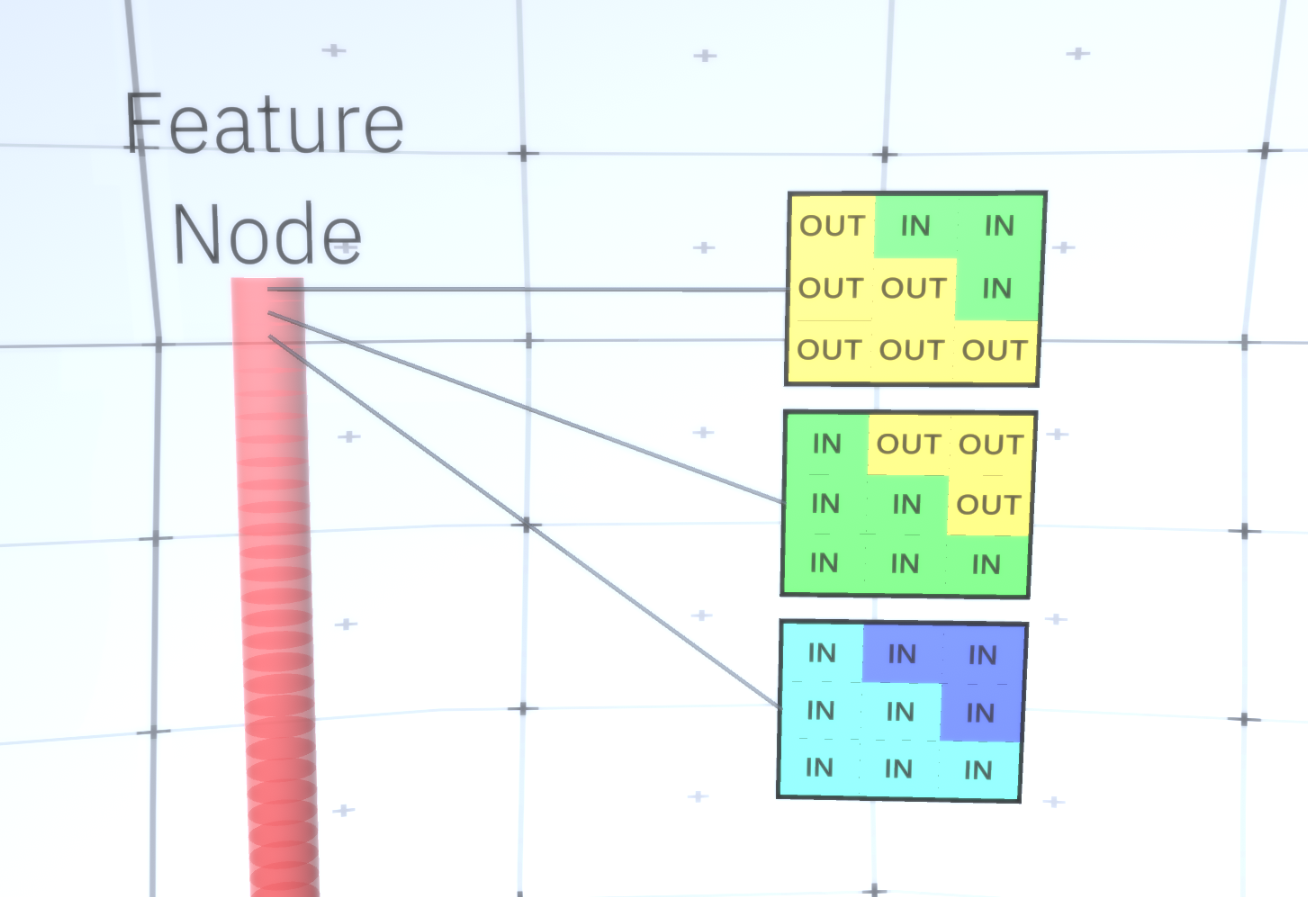
Каждый узел состоит из нескольких каналов, каждый из которых представляет отдельный признак. Каналы – это бинарные переменные, которые принимают значение True или False, указывая, существует ли объект, соответствующий этому каналу, в конечном сгенерированном изображении в координате (x,y) узла. На любом уровне узлы имеют однотипные каналы.
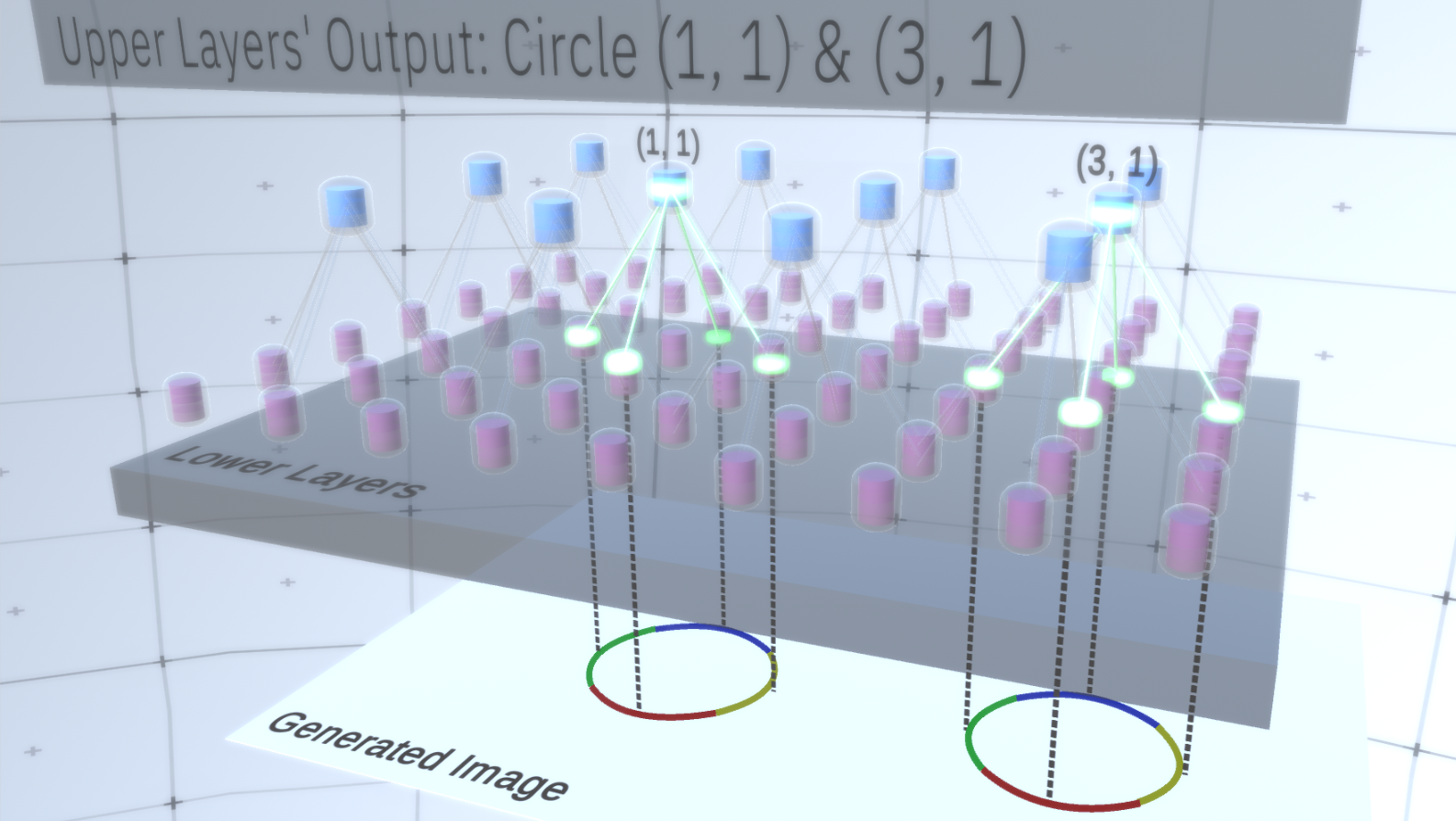
В качестве примера давайте возьмем промежуточный слой и поговорим о его каналах и слоях выше, чтобы упростить объяснение. Список каналов на этом слое будет представлять собой гиперболу, окружность и параболу. На определенном прогоне при генерации картинки, вычислениям вышележащих слоев потребовалась окружность в координате (1,1). Таким образом узел (1, 1) будет иметь канал, соответствующий объекту «окружность» в значении True. Это окажет непосредственное влияние на некоторые узлы в слое, лежащем ниже, то есть признаки нижнего уровня, которые ассоциируются с окружностью в окрестности (1,1), будут установлены в True. Эти объекты нижнего уровня могут быть, например, четырьмя дугами с различной ориентацией. Когда признаки нижнего слоя активируются, они активируют каналы на слоях еще ниже, пока не будет достигнут последний слой, генерирующий изображение. Визуализация активации показана на Рисунке 2.
Вы можете спросить, каким образом станет ясно, что представление окружности – это 4 дуги? И как RCN узнает, что ей нужен канал для представления окружности? Каналы и их привязки к другим слоям будут сформированы на этапе обучения RCN.
Возможно, вы укажете на весьма жесткий и детерминированный метод генерации принятой модели, однако для людей малые возмущения кривизны окружности все еще считаются окружностью, как вы можете видеть на Рисунке 3.
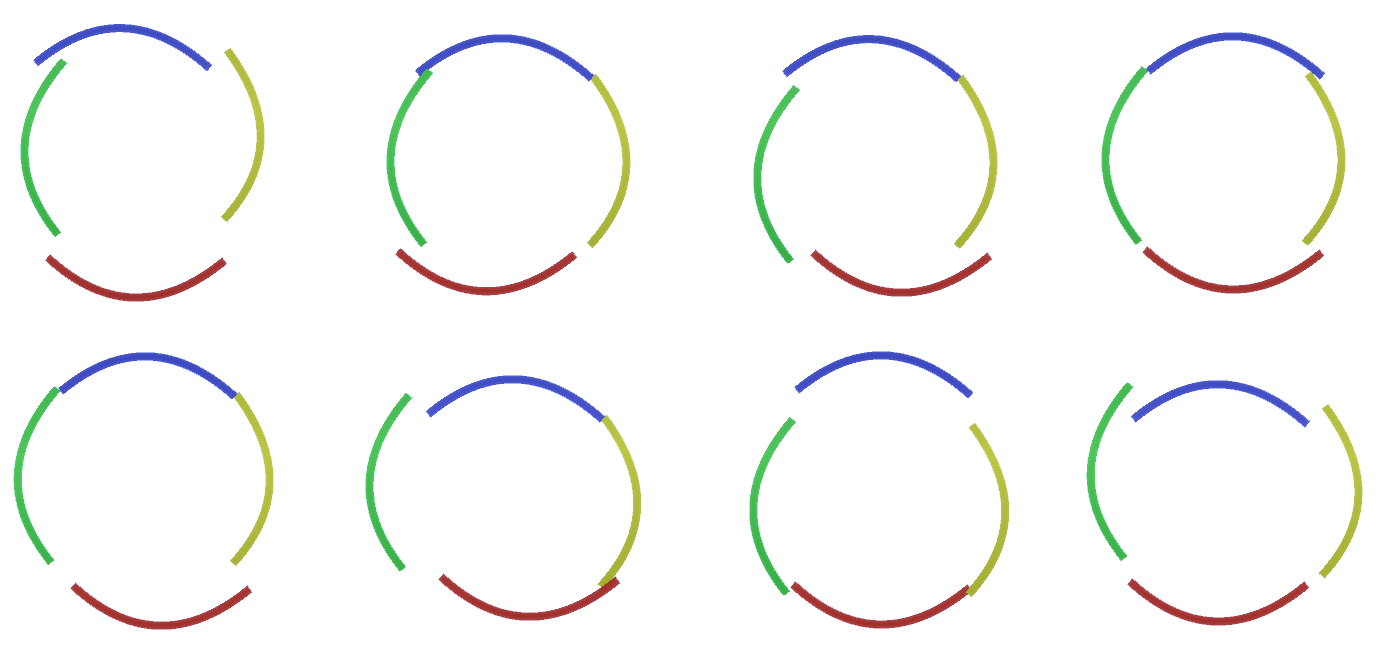
Было бы трудно рассматривать каждую из этих вариаций как отдельный новый канал в слое. Аналогичным образом группировка вариаций в одну и ту же сущность очень поспособствует обобщению в новые вариации, когда мы чуть позже будем адаптировать RCN к классификации вместо генерации. Но как же нам изменить RCN, чтобы получить такую возможность?
Слои подвыборки
Для этого понадобится новый тип слоя – слой подвыборки (pooling layer). Он располагается между любыми двумя слоями признаков и действует в качестве посредника между ними. Он также состоит из каналов, однако они имеют целочисленные значения, а не двоичные.
Чтобы проиллюстрировать работу этих слоев, давайте вернемся к примеру с окружностью. Вместо того, чтобы требовать 4 дуги с фиксированными координатами из слоя признаков над ним в качестве признака окружности, поиск будет вестись на слое подвыборки. Затем каждый активированный канал в слое подвыборки выберет узел на нижележащем слое в своей окрестности, чтобы учесть небольшое искажение признака. Таким образом, если мы установим связь с 9 узлами непосредственно под узлом подвыборки, то канал подвыборки, когда бы он ни был активирован, будет равномерно выбирать один из этих 9 узлов и активировать его, а индекс выбранного узла будет состоянием канала подвыборки – целым числом. На Рисунке 4 вы можете увидеть несколько прогонов, где при каждом запуске используется разный набор узлов нижнего уровня, соответственно, позволяя создавать окружность различными способами.

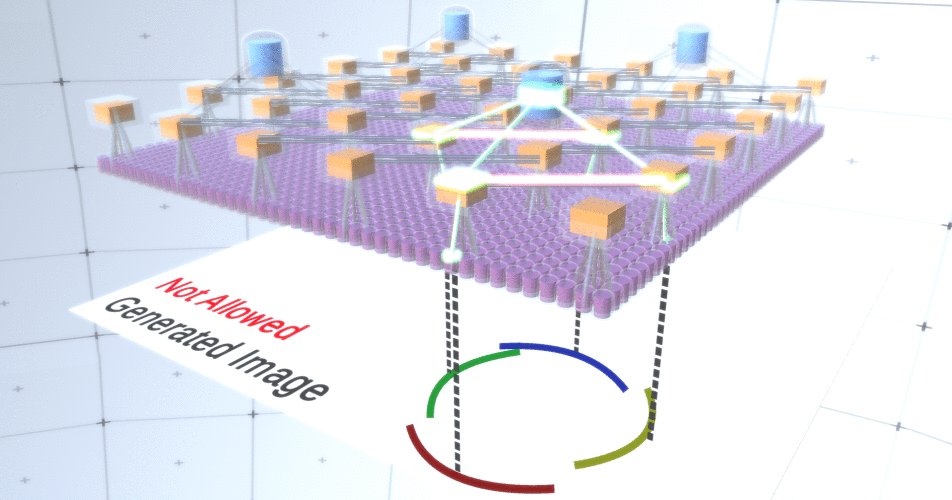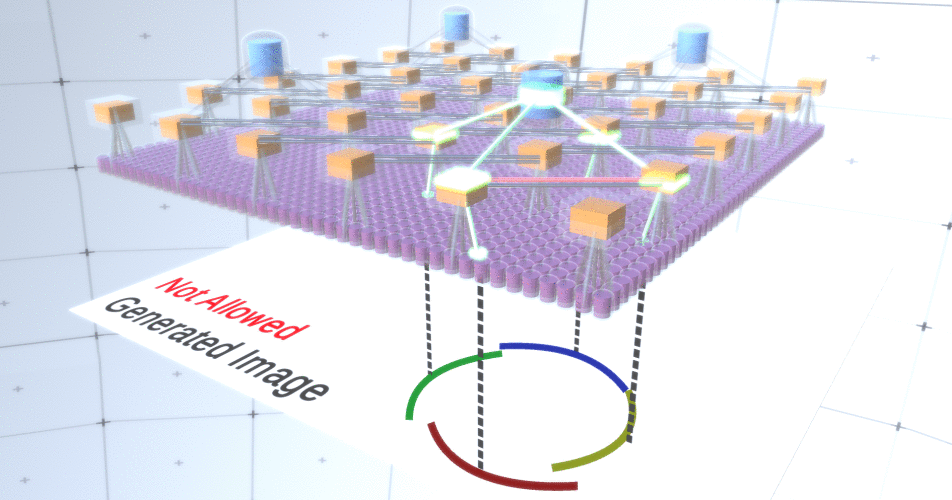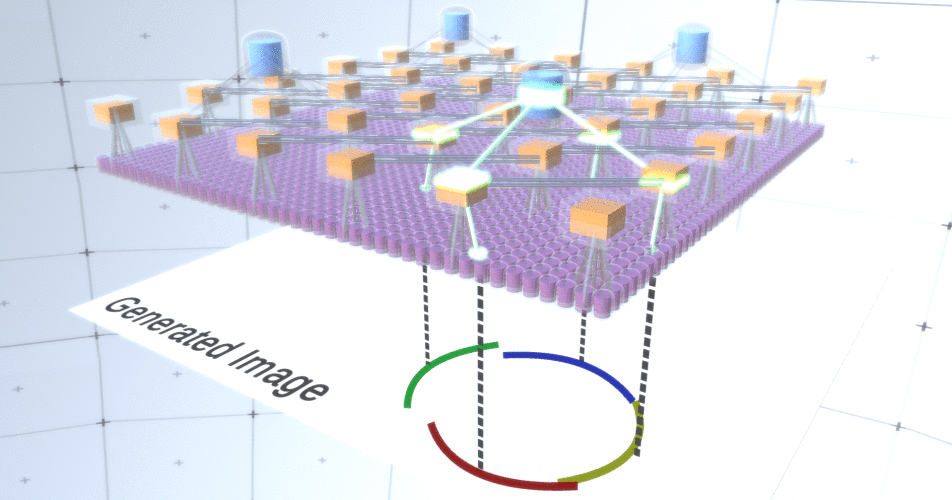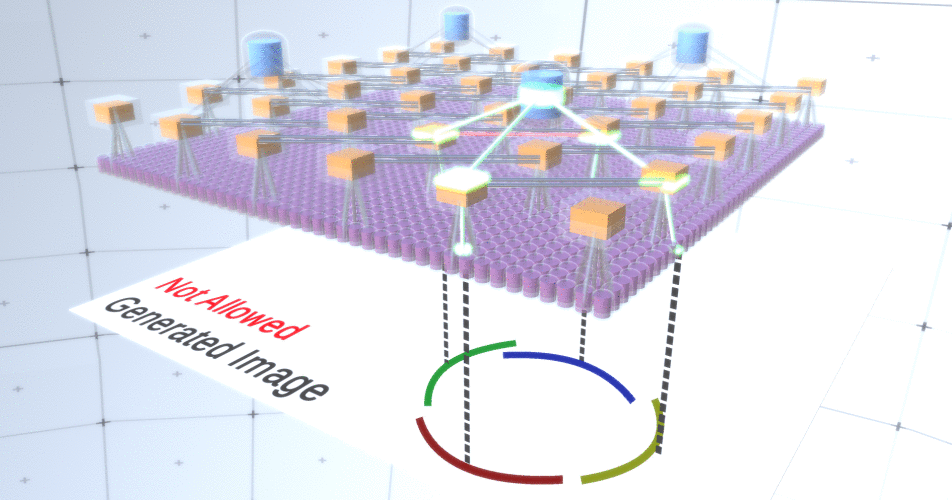
Несмотря на то, что мы нуждались в вариативности нашей модели, было бы лучше, если бы она оставалась более сдержанной и сосредоточенной. На предыдущих двух рисунках некоторые окружности выглядят слишком странно, чтобы действительно интерпретировать их как окружности из-за того, что дуги не соединены между собой, как видно из Рисунка 5. Нам хотелось бы избежать их генерации. Таким образом, если бы мы могли добавить механизм для каналов подвыборки, чтобы координировать выборку узлов признаков и сосредоточиться на непрерывных формах, наша модель была бы более точной.

Авторы RCN использовали боковые соединения (lateral connection) в слоях подвыборки для этой цели. По существу, каналы подвыборки будут иметь связи с другими каналами подвыборки из ближайшего окружения, и эти связи не позволят некоторым парам состояний сосуществовать в двух каналах одновременно. По сути, просто будет ограничена область выборки этих двух каналов. В различных вариантах окружности эти связи, например, не позволят двум соседним дугам отдаляться друг от друга. Этот механизм изображен на Рисунке 6. Опять же, эти связи устанавливаются на этапе обучения. Следует отметить, что современные ванильные искусственные нейронные сети не имеют в своих слоях никаких боковых соединений, хотя в биологических нейронных сетях они есть и, предполагается, что они играют определенную роль в контурной интеграции в зрительной коре (но, честно говоря, зрительная кора имеет куда более сложное устройство, чем может показаться из предыдущего утверждения).
До сих пор мы говорили о промежуточных слоях RCN, у нас остался лишь самый верхний слой и самый нижний, который взаимодействует с пикселями сгенерированного изображения. Самый верхний слой – это обычный слой признаков, где каналы каждого узла будут классами нашего размеченного датасета. При генерации мы просто выбираем местоположение и класс, который мы хотим создать, идем к узлу с заданным местоположением и говорим, чтобы он активировал канал выбранного нами класса. Это активирует некоторые каналы в слое подвыборки под ним, затем слой признаков ниже и так далее, пока мы не достигнем последнего слоя признаков. Опираясь на свои знания о сверточных нейронных сетях, вы должно быть думаете, что самый верхний слой будет иметь единственный узел, однако это не так, и в этом заключается один их плюсов RCN, но обсуждение этой темы выходит за рамки данной статьи.
Последний слой признаков будет уникальным. Помните, я говорил о том, что RCN отделяют форму от внешнего вида? Именно этот слой будет отвечать за получение формы генерируемого объекта. Таким образом, этот слой должен работать с очень низкоуровневыми признаками, самыми базовыми строительными блоками любой формы, которые помогут нам сгенерировать любую желаемую форму. Маленькие границы, вращающиеся под разными углами, вполне подойдут, и именно их используют авторы технологии.
Авторы выбрали признаки последнего уровня для представления окна размером 3х3, которое имеет границу с определенным углом вращения, которую они называют дескриптором патчей (patch descriptor). Число углов поворота, которое они выбрали, равно 16. Кроме того, чтобы иметь возможность позже добавить внешний вид, нужно две ориентации для каждого поворота, чтобы иметь возможность сказать, находится ли фон на левой или на правой границе, в случае если это внешние границы, и дополнительная ориентация в случае внутренних границ (т.е. внутри объекта). На Рисунке 7 показан узел последнего слоя признаков, а на Рисунке 8 показано, как дескрипторы патчей могут генерировать определенную форму.

Теперь, когда мы достигли последнего слоя признаков, у нас есть схема, на которой определены границы объекта и понимание того, является ли область за границей внутренней или внешней. Остается добавить внешний вид, обозначив каждую оставшуюся область на изображении как IN или OUT и закрасить области. Здесь может помочь условное случайное поле. Не вдаваясь в математические детали, мы просто назначим каждому пикселю в конечном изображение распределение вероятностей по цветам и состояниям (IN или OUT). Это распределение будет отражать информацию, полученную с границы карты. Например, если есть два соседних пикселя, один из которых IN, а другой OUT, вероятность того, что они будут иметь разный цвет, сильно возрастает. Если два соседних пикселя находятся на противоположных сторонах внутренней границы, вероятность того, что будут иметь разный цвет также возрастет. Если пиксели лежат внутри границы и ничем не отделены друг от друга, то вероятность того, что они имеют одинаковый цвет, увеличивается, но внешние пиксели могут иметь небольшое отклонение друг от друга и так далее. Чтобы получить окончательное изображение, вы просто делаете выборку из совместного распределения вероятностей, которое мы только что установили. Чтобы сделать сгенерированные изображение интереснее, мы можем заменить цвета текстурой. Мы не будем обсуждать этот слой, поскольку RCN может выполнять классификацию, не основываясь на внешнем виде.
Что ж, на этом мы на сегодня закончим. Если вы хотите узнать больше о RCN, прочтите эту статью [5] и приложение с дополнительными материалами, или же вы можете прочесть другие мои статьи о логических выводах, обучении и результатах применения RCN на различных датасетах.
Источники:
- [1] R.Perrault, Y. Shoham, E. Brynjolfsson, et al., The AI Index 2019 Annual Report (2019), Human-Centered AI Institute — Stanford University.
- [2] D. Hendrycks, K. Zhao, S. Basart, et al., Natural Adversarial Examples (2019), arXiv:1907.07174.
- [3] J.Su, D. Vasconcellos Vargas, and S. Kouichi, One Pixel Attack for Fooling Deep Neural Networks (2017), arXiv:1710.08864.
- [4] M. Sharif, S. Bhagavatula, L. Bauer, A General Framework for Adversarial Examples with Objectives (2017), arXiv:1801.00349.
- [5] D. George, W. Lehrach, K. Kansky, et al., A Generative Vision Model that Trains with High Data Efficiency and Break Text-based CAPTCHAs (2017), Science Mag (Vol 358 — Issue 6368).
- [6] H. Liang, X. Gong, M. Chen, et al., Interactions Between Feedback and Lateral Connections in the Primary Visual Cortex (2017), Proceedings of the National Academy of Sciences of the United States of America.
Ждем ваши комментарии и приглашаем всех желающих на бесплатный вебинар по теме: «Анализ текстовых данных: тематическое моделирование комментариев Вконтакте».