ОБРАБОТКА ТЕКСТОВЫХ ДАННЫХ МЕТОДАМИ NLP
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2020-02-27 09:01

Время прочтения: 4 мин.
Сегодня активно развиваются методы машинного обучения, которые в качестве входных данных используют различные тексты – от комментариев в социальных сетях до официальных документов. Для использования алгоритмов машинного обучения для текста используются алгоритмы NLP (Natural Language Processing).
В данной статье хотелось бы поделиться основными принципами и методами NLP, применяемыми для подготовки текста перед использованием в машинном обучении.
Для начала импортируем все необходимые библиотеки:
import re import nltk from nltk.corpus import stopwords import pandas as pd import pymorphy2 from sklearn.feature_extraction.text import CountVectorizer from sklearn.feature_extraction.text import TfidfVectorizerВ качестве примера будем использовать отрывок из произведения М.Ю. Лермонтова – «Бородино».

Считаем эти данные из текстового файла:
file = open('test.txt','r',encoding='utf-8') text = file.readlines() print(text)
Первым шагом в обработке данных является приведение всех символов текста к нижнему регистру:
text = [line.lower() for line in text] print(text)
Далее из текста удаляются знаки пунктуации, различные небуквенные символы и цифры. Сделать это можно, применив функцию re.sub и указав в качестве параметра шаблон для поиска всех небуквенных символов:
text = [re.sub(r'[^ws]',' ',line,flags=re.UNICODE) for line in text] print(text)
Для применения последующих методов имеет смысл разбить каждую строку на список составляющих её слов. Для этого можно воспользоваться возможностями библиотеки nltk:
tokenizedText = [nltk.word_tokenize(line) for line in text] print(tokenizedText)
Существуют слова, которые в процессе применения алгоритмов машинного обучения добавляют шум и влияют на качество модели (стоп-слова). Список стоп-слов можно увидеть, воспользовавшись командой:
from nltk.corpus import stopwords stopWords = stopwords.words("russian") print(stopWords)
Теперь удалим стоп-слова из наших данных:
def lineWithoutStopWords(line): return [word for word in line if word not in stopWords] withoutStopWords = [lineWithoutStopWords(line) for line in tokenizedText] print(withoutStopWords)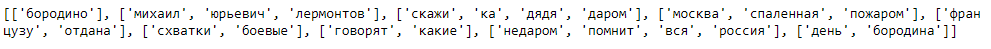
Обычно тексты содержат различные грамматические формы одного и того же слова либо однокоренные слова. Для приведения встречающихся словоформ к одной (нормальной форме) используется лемматизация.
Лемматизация – процесс, который использует морфологический анализ и словарь, для приведения слова к его канонической форме – лемме.
Для этой задачи будем применять библиотеку pymorphy2:
def normalForm(line): return [morph.parse(word)[0].normal_form for word in line if len(word)>2] normalForm = [normalForm(line) for line in withoutStopWords] print(normalForm)После всех преобразований, можно оценить слова в полученном документе. Для этого необходимо преобразовать обработанный текст в набор цифр. Именно эти данные можно использовать как входные данные для модели машинного обучения.
count_vectorizer = CountVectorizer() string = [''.join(line) for line in normalForm] bag_of_words = count_vectorizer.fit_transform(string) feature_names = count_vectorizer.get_feature_names() pd.DataFrame(bag_of_words.toarray(),columns=feature_names[:9])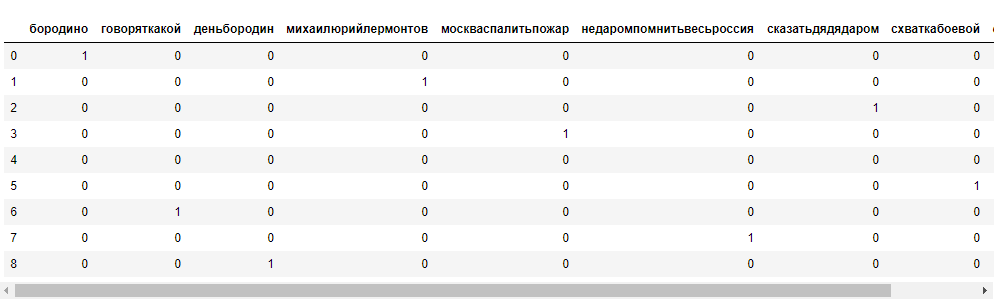
Сформированная последовательность (вектор) из нулей и единиц может использоваться в качестве набора фичей при обучении моделей.
Телеграм: t.me/ainewsline
Источник: newtechaudit.ru