Наша Data Science команда в НОРБИТ около полугода экспериментировала с использованием различных моделей машинного обучения для решения задач по классификации и регрессии, и по оптимизации бизнес-процессов в сфере b2b. Но когда появилась задача по предсказанию временных рядов, оказалось, что доступных материалов на эту тема в сети недостаточно для разработки быстрого решения.

Достижению высокой точности прогнозирования мешают много факторов, например, при внезапном повышении температуры люди сразу тянутся за пультами от кондиционеров, при понижении — достают с антресолей обогреватели; во время праздников или больших футбольных матчей включают телевизоры и т.д. Если некоторые события цикличны и потенциально предсказуемы, то другие — совершенно нет. Допустим, внезапно по причине аварии перестал работать сталелитейный цех и все прогнозы превратились в тыкву (в нашем целевом городе обошлось без крупных производственных предприятий). Был довольно интересный пример проблемы при построении прогнозов в энергетике, когда один из всплесков изменений в объеме вырабатываемой электроэнергии был вызван тем, что корабль сел на мель на озере, и капитан договорился с владельцами гидроэлектростанций, чтобы они уменьшили сброс воды. Естественно, что модель машинного обучения не смогла предугадать это событие на основании накопленных исторических данных.
Хорошая новость для нас, что заказчик предусмотрел в техническом задании такие «особенные дни», в которые была допустима средняя ошибка прогноза в 8%.
Все, что предоставил заказчик, — это исторические данные почасового потребления электроэнергии за 3 года и название города.

import pandas as pd import seaborn as sns import matplotlib.pyplot as plt # df - pandas DataFrame с признаками sns.heatmap(df.corr());

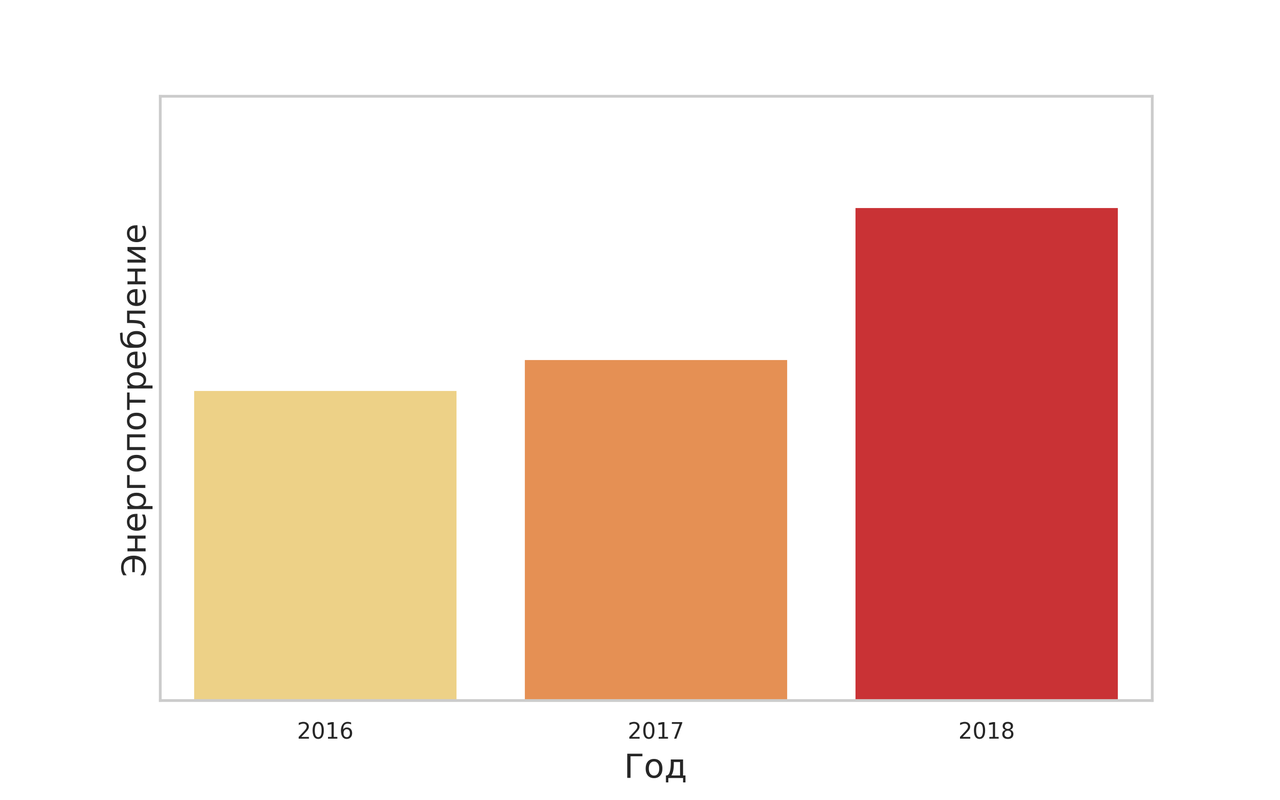

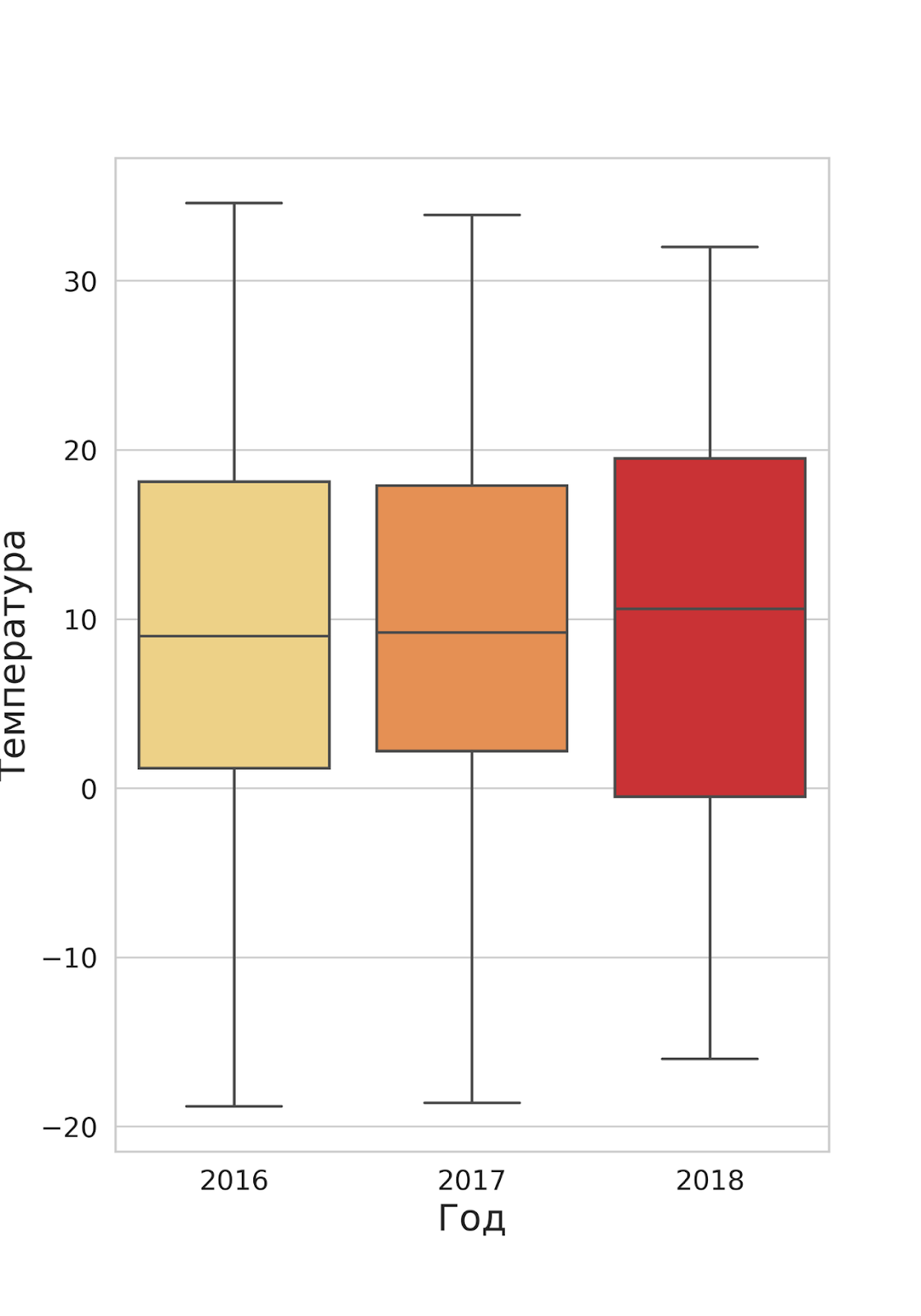
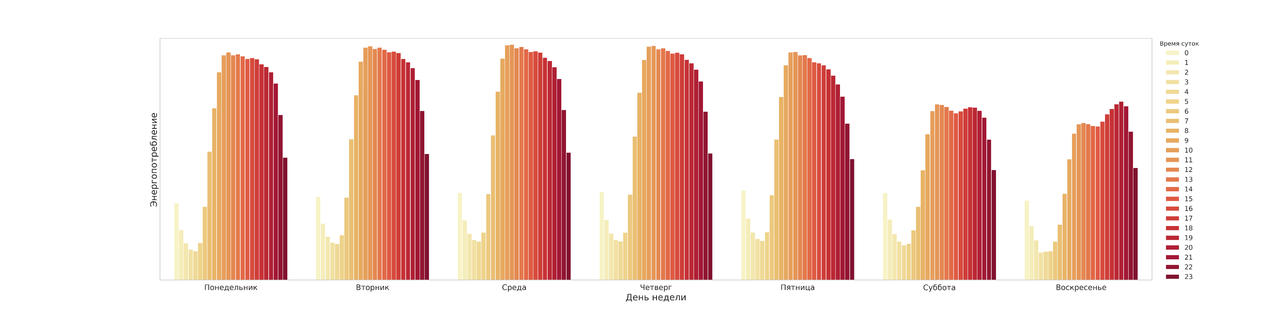

Моделирование
Prophet
Первая идея, как сделать задачу максимально быстро — это взять Prophet от Facebook. У меня уже был опыт его использования, и я его запомнил как «штука, которая просто и быстро работает из коробки». Prophet для работы хочет видеть в pandas-датафрейме колонки «ds» и «y», т.е. дату в формате YYYY-MM-DD HH:MM:SS, и таргет — потребление в час, соответственно (примеры работы есть в документации).
df = pd.read_pickle('full.pkl') pjme = df.loc[:'2018-06-01 23:00'].rename(columns={'hour_value': 'y'}) pjme['ds'] = pjme.index split_date = '2018-03-01 23:00' pjme_train = pjme.loc[pjme.index <= split_date] pjme_test = pjme.loc[pjme.index > split_date] playoffs = pd.DataFrame({ 'holiday': 'playoff', 'ds': df[(df.rest_day == 1)|(df.is_weekend == 1)].index, 'lower_window': 0, 'upper_window': 1, }) model = Prophet(holidays=playoffs) model.fit(pjme_train.reset_index()) forecast = model.predict(df=pjme_test.reset_index())
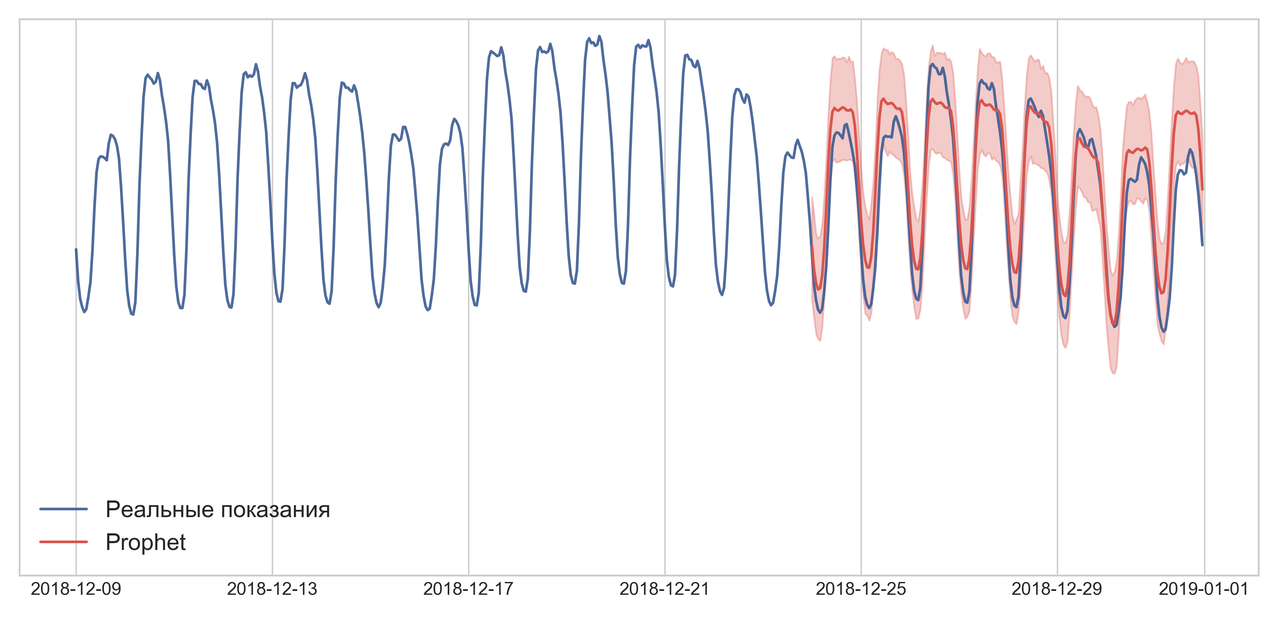
SARIMAX
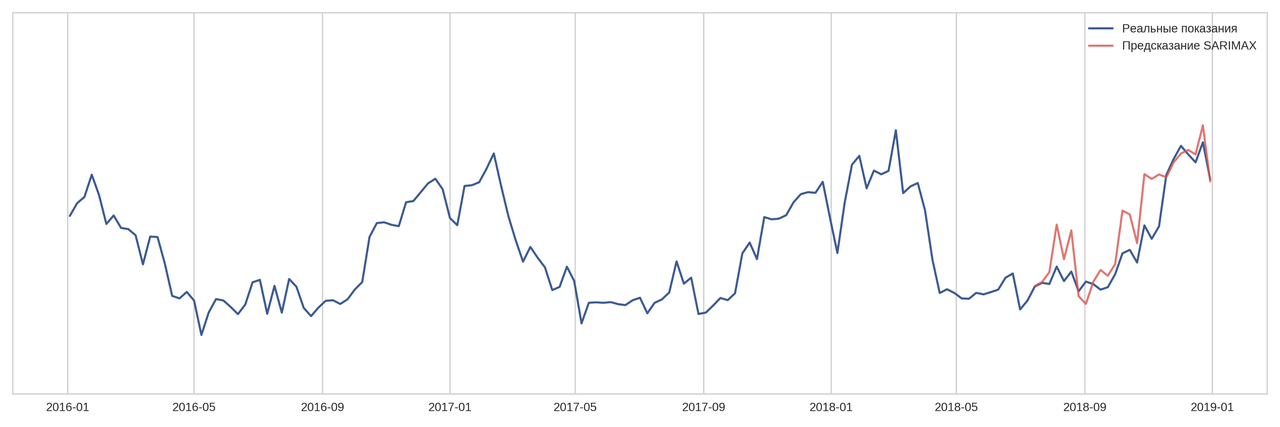
Вторая попытка решения этой задачи была с помощью SARIMAX. Метод довольно затратный по времени подбора коэффициентов, но зато удалось снизить ошибку прогноза по сравнению с Prophet до 6-11%.
К сожалению, остался только результат для недельных предсказаний, но именно эти прогнозные данные я использовал в качестве дополнительных фич в бустинг-моделях.
Для прогноза нужно подобрать параметры SARIMA(p,d,q)(P,D,Q,s):
- p — порядок авторегрессии (AR), который позволяет добавить прошлые значения временного ряда (можно выразить как «завтра, возможно, пойдет снег, если в последние несколько дней шел снег»);
- d — порядок интегрирования исходных данных (он определяет число предыдущих временных точек, которые нужно вычесть из текущего значения);
- q — порядок скользящего среднего (MA), который позволяет установить погрешность модели в виде линейной комбинации наблюдавшихся ранее значений ошибок;
- P — p, но сезонное;
- D — d, но сезонное;
- Q — q, но сезонное;
- s — размерность сезонности (месяц, квартал и т.д.).
На сезонном разложении по недельной истории можно увидеть тренд и сезонности, которые позволяет отобразить seasonal_decompose:
import statsmodels.api as sm sm.tsa.seasonal_decompose(df_week).plot()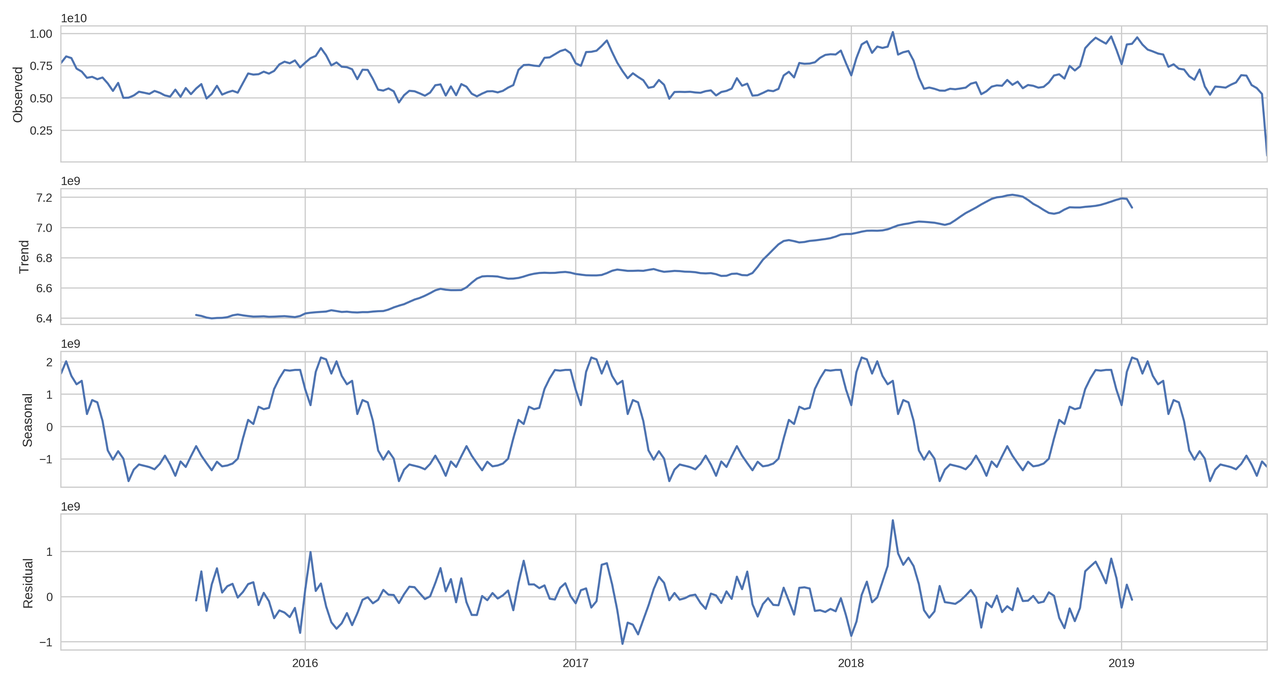
sm.graphics.tsa.plot_acf(df_week.diff_week[52:].values.squeeze(), lags=60, ax=ax) sm.graphics.tsa.plot_pacf(df_week.diff_week[52:].values.squeeze(), lags=60, ax=ax)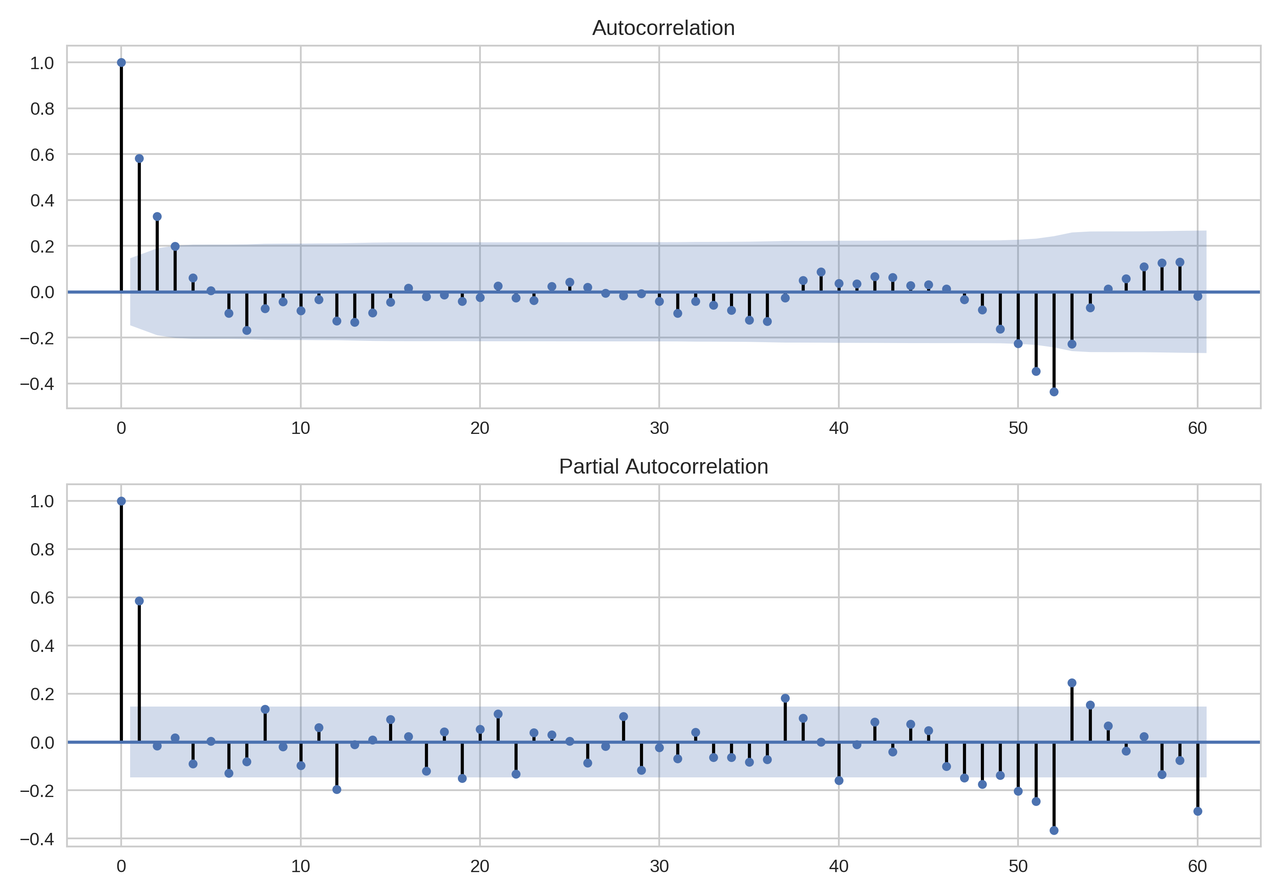
Бустинг
В этот момент стало очевидно, что без использования дополнительных внешних факторов не удастся достичь необходимой точности. В первую очередь, это погодные факторы: температура, давление, влажность, сила и направление ветра, осадки.
Первой попыткой была попытка купить архив с погодой в Яндекс. У ребят отличное API и техподдержка, но конкретно по нашему городу в данных было довольно много пропусков. В итоге я купил архив в сервисе openweathermap.org за 10$. Важно отметить, что, несмотря на то, что погода — очень полезный фактор, ошибки в прогнозе очевидно будут сильно портить итоговую MAPE модели. Я встречал информацию, что правильным решением этой проблемы было бы в обучении использовать не фактические исторические значения погоды, а прогнозы погоды за трое суток, но у меня, к сожалению, такой возможности не было. Также я добавил признаки времени суток, дня недели, праздники, порядковый номер дня в году, а также большое количество временных лагов и средних значений за предыдущие периоды.
Все эти данные после масштабирования (MinMaxScale) и One Hot Encoding (значения каждого категориального признака становятся отдельными столбцами с 0 и 1, таким образом, признак с тремя значениями становится тремя разными столбцами, и единица будет лишь в одном из них) я использовал в небольшом соревновании трех популярных моделей бустинга XGBoost, LightGBM и CatBoost.
XGBoost
Об XGBoost’е написано много хорошего. Представленный на конференции SIGKDD в 2016 году, он произвел настоящий фурор и до сих пор держится на лидирующих позициях. Интересный материал для тех, кто про него не слышал. Подготовим данные для модели:
from sklearn.preprocessing import MinMaxScaler, StandardScaler from sklearn.model_selection import train_test_split def gen_data( stop_day = '2018-06-01 23:00', drop_columns = [], test_size=0.15, is_dummies=True, is_target_scale=False): df = pd.read_pickle('full.pkl') df = df.loc[:stop_day] scaler = MinMaxScaler() target_scaler = StandardScaler() y = df.hour_total if is_target_scale: y = target_scaler.fit_transform(y.values.reshape(-1, 1)).reshape(1,-1)[0] X = df.drop(['hour_value', *drop_columns], axis=1) num_columns = X.select_dtypes(include=['float64']).columns X[num_columns] = scaler.fit_transform(X[num_columns]) if is_dummies: X = pd.get_dummies(X) train_count_hours = len(X) - 72 valid_count_hours = len(X) - int(len(X) * 0.2) X_test = X[train_count_hours:] y_test = y[train_count_hours:] X = X[:train_count_hours] y = y[:train_count_hours] # Тут можно пробовать разные варианты разбиения на обучающую и тестовую выборки, от этого сильно зависит итоговая точность модели X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=test_size, random_state=42) train_dates = X_train.index val_dates = X_test.index return X, y, X_train, X_val, y_train, y_val, X_test, y_test, target_scalerУчу модель, используя лучшие подобранные ранее гиперпараметры:
X, y, X_train, X_val, y_train, y_val, X_test, y_test, _ = gen_data( stop_day = stop_day, drop_columns = drop_columns, test_size=0.1, is_dump=True, is_target_scale=False) params_last = { 'base_score': 0.5, 'booster': 'gbtree', 'colsample_bylevel': 1, 'colsample_bynode': 1, 'colsample_bytree': 0.4, 'gamma': 0, 'max_depth': 2, 'min_child_weight': 5, 'reg_alpha': 0, 'reg_lambda': 1, 'seed': 38, 'subsample': 0.7, 'verbosity': 1, 'learning_rate':0.01 } reg = xgb.XGBRegressor(**params_last, n_estimators=2000) print(X_train.columns) reg.fit(X_train, y_train, eval_set=[(X_val, y_val)], early_stopping_rounds=20, verbose=False) y_pred = reg.predict(X_test)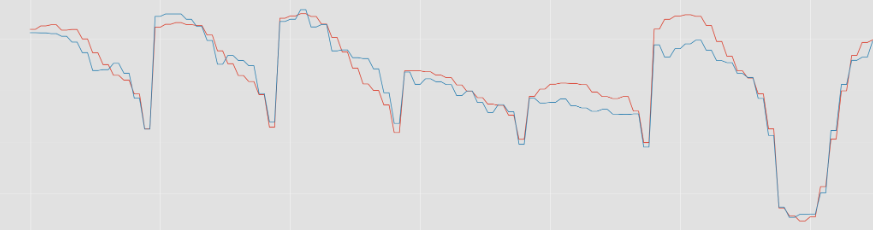
LightGBM
LightGBM — фреймворк от Microsoft, основное преимущество которого состоит в скорости обучения на действительно больших массивах данных. А также в отличие от XGBoost’а LightGBM умеет работать с категориями, использует меньше памяти. Вот тут есть подробнее.
import lightgbm as lgb from lightgbm import LGBMRegressor from sklearn.metrics import mean_squared_error stop_day = '2018-06-01 23:00' start_day_for_iterate = datetime.strptime(stop_day, '%Y-%m-%d %H:%M') test_size = 0.2 X, y, X_train, X_val, y_train, y_val, X_test, y_test, _ = gen_data( stop_day = stop_day, drop_columns = drop_columns, test_size=test_size, is_dump=True, drop_weekend=False, is_target_scale=False) model = LGBMRegressor(boosting_type='gbdt', num_leaves=83, max_depth=-1, learning_rate=0.008, n_estimators=15000, max_bin=255, subsample_for_bin=50000, min_split_gain=0, min_child_weight=3, min_child_samples=10, subsample=0.3, subsample_freq=1, colsample_bytree=0.5, reg_alpha=0.1, reg_lambda=0, seed=38, silent=False, nthread=-1) history = model.fit(X_train, y_train, eval_metric='rmse', eval_set=[(X_val, y_val)], early_stopping_rounds=40, verbose = 0) y_pred = model.predict(X_test, num_iteration=model.best_iteration_)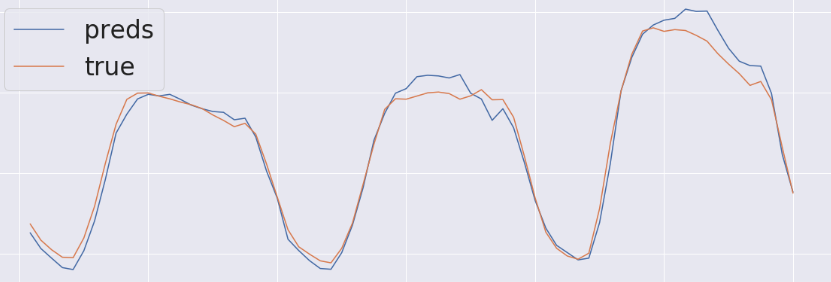
CatBoost
CatBoost — продвинутая библиотека градиентного бустинга на деревьях решений с открытым исходным кодом" от Яндекса. Выгодное отличие модели состоит в удобстве работы с датасетами, содержащими категориальные признаки — передавать в модель содержащие категории данные можно без преобразования в числа, причем она выявляет закономерности самостоятельно, руками ничего подкручивать не требуется, и качество предсказания остается на высоте.
cat_features=np.where(X.dtypes == 'category')[0] eval_dataset = Pool(X_test, y_test) model = CatBoostRegressor(learning_rate=0.5, eval_metric='RMSE', leaf_estimation_iterations=3, depth=3) model.fit(X_train, y_train, eval_set=(X_val, y_val), cat_features=cat_features, plot=True, verbose=True) y_pred = model.predict(X_test)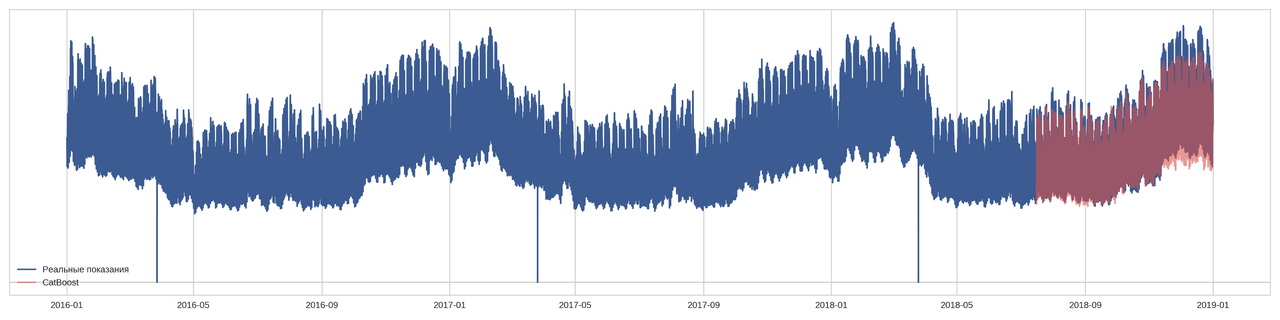
XGBoost vs. LightGBM vs. CatBoost
Чтобы не повторять многочисленные статьи, приведу сравнительную таблицу отсюда.
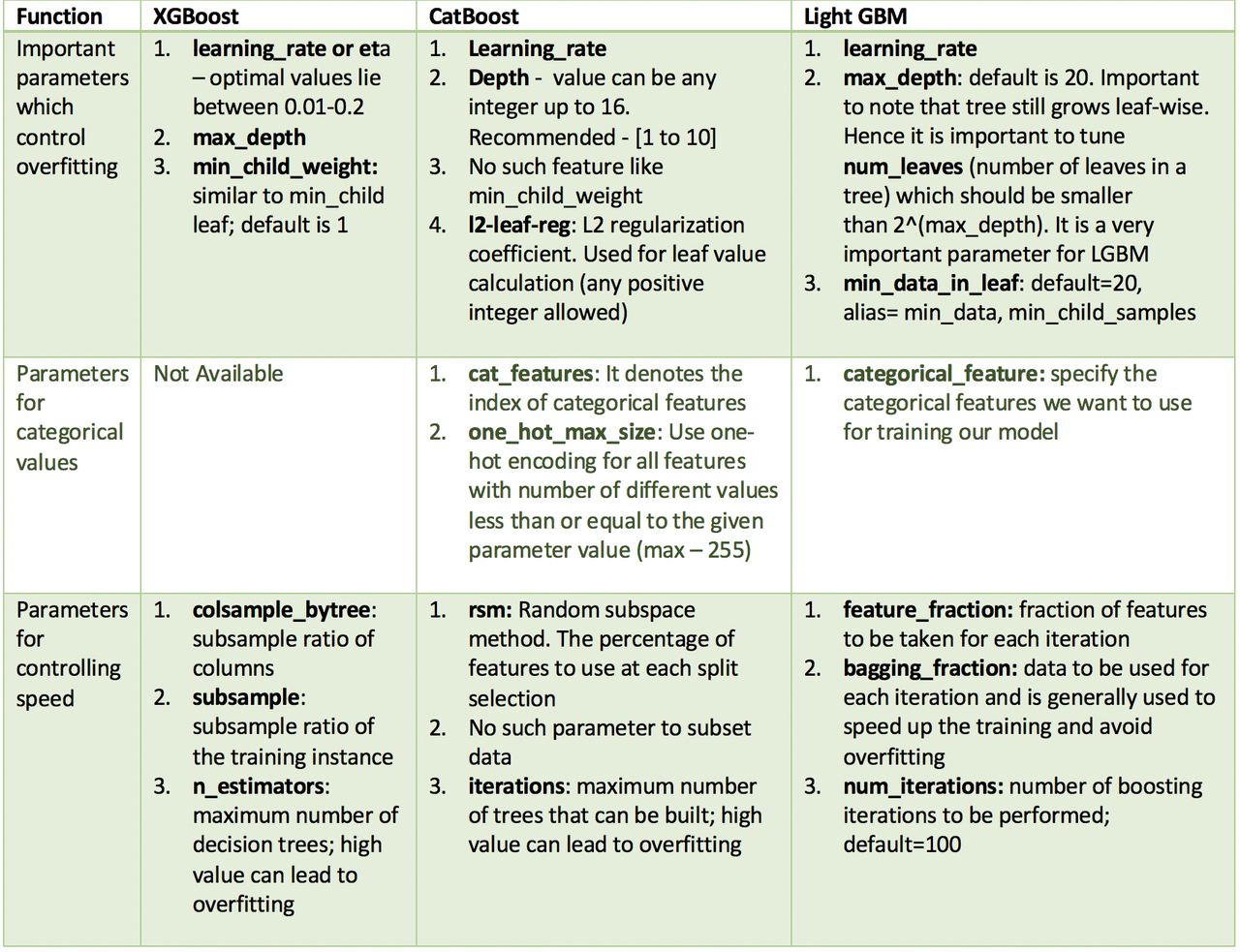
3-е место: мой любимчик — XGBoost — с самым низким качеством прогноза;
2-е место: CatBoost как самый удобный и «все из коробки»;
1-е место: LightGBM как самый быстрый и точный.
Для более точного сравнения моделей я использовал R2 (R-квадрат или коэффициент детерминации, показывающий, как сильно условная дисперсия модели отличается от дисперсии реальных значений) и RMSLE (Root Mean Squared Logarithmic Error, или среднеквадратичная логарифмическая ошибка, которая является, по сути, расстоянием между двумя точками на плоскости — реальным значением и предсказанным).
| Метрика | LightGBM | Catboost | XGBoost | Prophet | SARIMAX |
| r2 | 0.94137 | 0.93984 | 0.92909 | 0.81435 | 0.73778 |
| MSLE | 0.02468 | 0.02477 | 0.01219 | 0.00829 | 0.00658 |