Блеск и нищета машинного перевода
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2020-02-11 13:45

«Одним из главных факторов, влияющих на становление «университета будущего», является внедрение в образовательный процесс технологий искусственного интеллекта и, прежде всего, машинного перевода. Он сравняется, да уже сравнялся с переводом, выполненным человеком».
Ректор РАНХиГС Владимир Мау
«Цифровизация очень скоро освободит нас от переводов. Благодаря использованию нейронно-сетевых технологий, качество переводов буквально от месяца к месяцу существенно улучшается. Функция запоминания позволяет машине выбрать из большого числа вариантов тот перевод, который наиболее близок к правильному. Сейчас это становится реальным. Естественно-научные статьи уже можно не переводить. Нажали кнопку — автомат выдает перевод».
Академик, вице-президент РАН Алексей Хохлов
И это еще не самое интересное, что можно услышать про машинный перевод (machine translation, MT) – особенно от тех, кто, как вышеназванные лица, ничего не смыслит в этом вопросе. На Западе так и вообще почти всех уже убедили, что МТ – это «стильно, модно, молодежно», и не пользоваться им – признак отсталости. Но как обстоят дела на самом деле?
Над машинным переводом ученые и программисты бьются лет семьдесят. При этом, особенно в последние годы, направляемые на решение этой задачи ресурсы чудовищно превышают ее объективную важность. От оплаты труда «белковых» переводчиков еще ни одна фирма не разорилась, более того – за исключением контор типа AliExpress такие затраты редко превышают доли процента в общих расходах предприятия. Но по-прежнему как грибы после дождя растут новые движки машинного перевода. Пришло время задать простой вопрос – «зачем?»
Разумеется, есть ряд (довольно ограниченный) областей применения, в которых МТ вполне справляется. Скажем, можно настроить систему на основе правил, и она будет практически безошибочно переводить стандартные тексты типа сертификатов, личных документов, типовых договоров и пр. Аналогично можно натренировать нейронную сеть на корпусе исходных и переведенных текстов и получать вполне приличные результаты при переводе аналогичных текстов. Это – вполне оправданные области применения МТ. Однако зверь зачем-то вырвался из клетки и полез решать несвойственные ему задачи – МТ сегодня пихают везде. Качество, разумеется получается катастрофическим. Понимая это, апологеты МТ на пару с дефективными эффективными менеджерами выдвинули концепцию постредактирования машинного перевода (РМЕТ). Мол, МТ уже все сделал на 90%, а живому переводчику там «только чуть подправить». Ну и платить такому пока еще живому переводчику (долго с таким заработком он точно не протянет), соответственно, надо процентов 10…15 от ставки за перевод.
Укрупненные этапы перевода:
Укрупненные этапы РЕМТ:
Число действий увеличивается практически вдвое. Соответственно, никакого прироста производительности РЕМТ, если делать его качественно, дать не может. Перевод «с нуля» человеком оказывается быстрее и эффективнее. Об этом же свидетельствуют и отзывы коллег: на РЕМТ уходит на 20…60 % времени больше, чем на «просто перевод». То есть с точки зрения переводчика овчинка совершенно не стоит выделки. Однако вот с точки зрения менеджера БП или заказчика ситуация получается просто шикарная: человек работает в 1,5 раза интенсивнее при снижении оплаты на 60…80%! Рабовладельческий строй отдыхает J Ну и простой вопрос: а насколько качественно бедный переводчик будет делать РЕМТ на таких условиях? Ответ очевиден.
А теперь самое главное. Готовы? Провозглашаю новый принцип: «МТ по любой технологии НИКОГДА не сможет правильно переводить специализированные тексты». И это не вопрос алгоритмов, Big Data, обучения нейронных сетей… Это принципиальная невозможность – такая же, как невозможность постройки вечного двигателя. Доказательство принципа:
Специализированный перевод не может быть текстоцентричным. Для правильного понимания смысла текста необходимо привлекать огромные объемы дополнительной информации, причем чаще всего представленной в графическом виде, вообще не поддающемся машинному анализу. В самом исходном тексте, как правило, содержится не более 20…30% всей требуемой для перевода информации. Кроме того, исходный текст очень часто содержит грубые ошибки, исправлять которые – прямая обязанность переводчика. На это МТ, разумеется, также не способен.
И это принципиально и никак не изменится от совершенствования технологий МТ. Любая такая технология работает только с исходным текстом. МТ не может заглянуть в иллюстрацию к научной статье по теме, чтобы понять, как надо переводить. Ничего понять он, кстати, тоже не может.
Рассмотрим пример. Вроде бы элементарный исходник, речь о колесном погрузчике:
Less fuel is consumed in the use of V shape loading.
Как справились движки машинного перевода?
DeepL:
При использовании нагрузки V-образной формы расходуется меньше топлива.
GT:
Меньше топлива расходуется при использовании V-образной загрузки.
Яндекс.Переводчик:
Меньше топлива потребляется при использовании V-образной загрузки.
Все три варианта — гладкие, грамматически верные... и абсолютно бессмысленные. Потому как из текста (спасибо, дорогой автор!) совершенно невозможно понять, что имеется ввиду под «V shape loading». А вот если погуглить статьи на эту тему и посмотреть иллюстрации, то все становится на свои места. И правильный перевод будет «загрузка самосвала с движением колесного погрузчика по V-образной траектории». И никакой нейронной сетью его выловить невозможно в принципе - он не в тексте, он в картинках (рис. 1), а картинка к тому же не в этом тексте, а совсем в другом. И это очень частое явление в техническом переводе, кстати, уже не говоря про аудиовизуальный, где видеоряд имеет абсолютный приоритет.
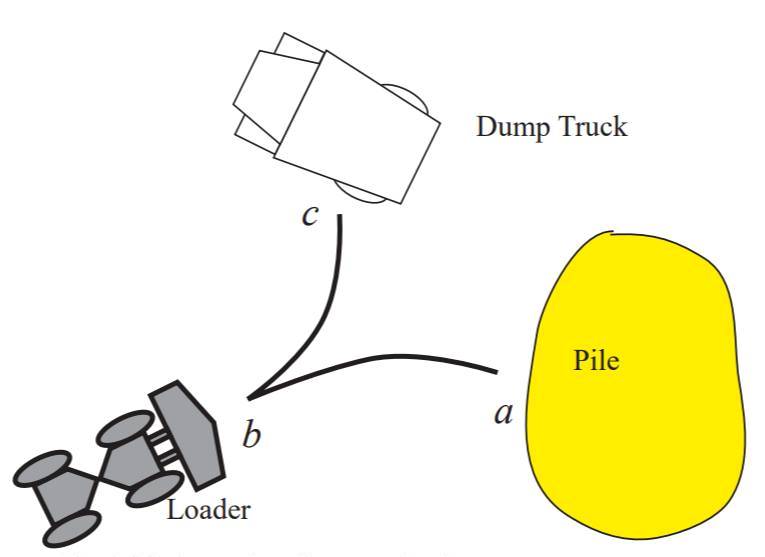
Рис. 1 – Решение загадки про V-образную траекторию.
Поэтому применение МТ в специализированных видах перевода (технический, юридический, аудиовизуальный и не дай бог медицинский) – опасная глупость. На выходе будет красивая, гладкая, складная ахинея.

Троицкий Дмитрий Игоревич - руководитель и владелец агентства переводов и разработки программного обеспечения TTS, работал в АО «Атомэнергопроект». В настоящее время также ведет курсы перевода («Машиностроительный перевод», «Перевод в науке и образовании», «Борьба с Runglish», «Автоматизация труда письменного переводчика» и др.) в школе переводчиков и в университетах страны.
Телеграм: t.me/ainewsline
Источник: www.toptr.ru