WebAssembly Powered Дополненная Реальность Судоку Решатель
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2020-01-08 10:21
системы технического зрения, дополненная реальность, примеры ии

Рождественские праздники-это прекрасное время для проведения "домашних" проектов и опробования новых вещей. В прошлом году я наблюдал за развитием WebAssembly и хотел создать интересный проект, который позволил мне использовать его с пользой. За последние пару недель я создал дополненную реальность Suduko solver:

В этом проекте используется сборка WebAssembly из OpenCV (библиотека компьютерного зрения C++), Tensorflow (библиотека машинного обучения) и решателя, написанного в Rust. Он четко демонстрирует, как WebAssembly позволяет писать критически важные для производительности веб-приложения на широком диапазоне языков.
Это сообщение в блоге дает краткий обзор кода для этого приложения, который можно найти на GitHub . Если вы новичок в WebAssembly и хотите узнать больше о проблеме, которую он решает, как он работает или что это такое, я бы тщательно рекомендовал руководство мультфильма Лина Кларка .
Решатель Судоко
На приведенной ниже диаграмме четко показаны шаги, связанные с определением местоположения головоломки судоку в изображении, решением головоломки, а затем отображением решения обратно на исходное изображение:
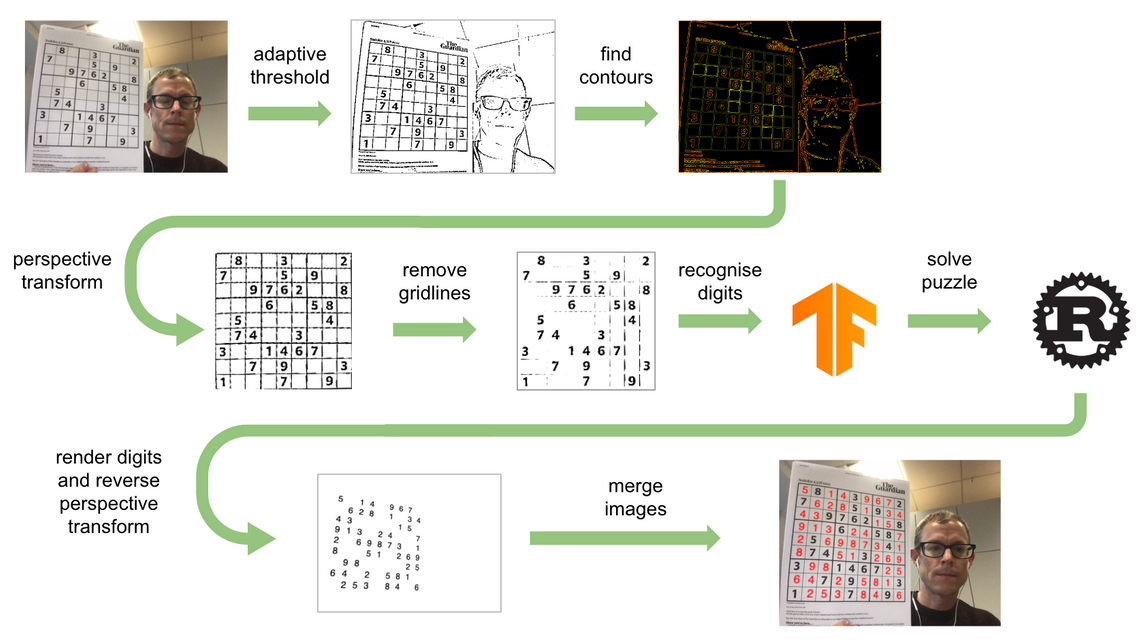
Вкратце, шаги, применяемые к каждому видеокадру, выглядят следующим образом:
- Адаптивное пороговое значение используется для поиска ребер, что приводит к черно-белому изображению
- Ребра аппроксимируются контурами; сетка судоку должна быть самой большой четырехгранной контуром
- Для визуализации сетки в виде квадратного изображения применяется (обратное) преобразование перспективы
- Линии сетки стираются
- Сверточная нейронная сеть используется для идентификации цифр в сетке 9x9
- Заполненная сетка решается с помощью модуля на основе ржавчины
- Преобразование перспективы из (3) применяется для проецирования решения обратно на изображение
- Решение сливается обратно в исходное изображение
Мы рассмотрим каждый из этих шагов по очереди.
Адаптивное обмолачивание
Этот решатель судоку использует различные методы компьютерного зрения, все из которых полагаются на библиотеку OpenCV.
OpenCV был запущен в 1999 году и вырос, чтобы стать популярным инструментарием компьютерного зрения благодаря своему обширному набору функций. Он также имеет различные дополнительные модули для ряда методов машинного обучения, включая нейронные сети. OpenCV написан на языке C++, с привязками для Python и Java. В 2018 году компилятор Emscripten был использован для добавления поддержки JavaScript.
Несмотря на наличие "официальной" поддержки JavaScript / WebAssembly, OpenCV не так просто работать. Существует ограниченный набор OpenCV.JS учебники на веб-сайте, и один из первых шагов включает в себя создание библиотеки из исходного кода, а не задачу для слабонервных ?. Есть открытая проблема, требующая, чтобы они выпустили OpenCV.js через npm, который должен сделать жизнь намного проще-но пока не имеет большой тяги. На данный момент я просто открыл одну из своих демо-версий и скопировал необходимые файлы JS / wasm!
Общая цель первых нескольких шагов обработки состоит в том, чтобы найти сетку судоку в изображении, первый из которых состоит в том, чтобы найти контур для различных форм в изображении.
OpenCV поддерживает различные подходы к удержанию изображений, в этом случае мы не можем гарантировать даже освещение через сетку судоку, поэтому адаптивный пороговый подход является наиболее подходящим.
В следующем коде показано, как создать буфер изображений OpenCV с помощью matFromImageData(буфер является экземпляром Matкласса) и применить адаптивный порог:
const imgRead = (canvas)=> { const ctx = canvas.getContext("2d"); const imgData = ctx.getImageData(0, 0, canvas.width, canvas.height); return cv.matFromImageData(imgData) } const threshold = (src) => { // convert to grayscale cv.cvtColor(src, src, cv.COLOR_RGBA2GRAY, 0); // apply a threshold cv.adaptiveThreshold(src, src, 255, cv.ADAPTIVE_THRESH_GAUSSIAN_C, cv.THRESH_BINARY, 11, 10) }; const sourceImage = imgRead(canvasElement); threshold(sourceImage); Вы можете увидеть влияние этого преобразования на исходное изображение:

Стоит отметить, что эти OpenCV.все операции js реализованы в C++ и скомпилированы в WebAssembly, различные cv.*вызовы функций в коде, показанном выше, являются очень тонкими оболочками вокруг их соответствующих функций WebAssembly.
Вы можете фактически увидеть, сколько времени тратится в коде OpenCV WebAssembly, записав профиль производительности:

Код WebAssembly ясно виден в нижней части диаграммы пламени.
Аппроксимация контуров
Следующий шаг немного сложнее, нам нужно найти самый большой квадрат в изображении - который должен быть сеткой судоку.
OpenCV имеет ряд методов для определения местоположения, аппроксимации и визуализации "контуров". Контур-это замкнутый контур, который описывает границу фигуры внутри изображения. Вы можете получить контуры из двоичного изображения с помощью findContoursфункции:
const contours = new cv.MatVector(); const hierarchy = new cv.Mat(); cv.findContours( src, contours, hierarchy, cv.RETR_CCOMP, cv.CHAIN_APPROX_SIMPLE ); ... hierarchy.delete(); contours.delete(); В OpenCV.js, конечно, чувствует себя довольно C-like, вы сначала должны создать матрицу иерархии и вектор-матрицу контуров перед вызовом findContours- вы также должны гарантировать, что эти объекты освобождаются, когда они больше не нужны с помощью их deleteметода.
Иерархия позволяет определить, какие контуры содержат другие, хотя здесь это не нужно - мы просто ищем самую большую четырехстороннюю форму. Однако это не так просто, как итерация по контурам, ищущим одну с четырьмя вершинами (т. е. углы). Контуры, возвращаемые findContoursдовольно подробно, отображая каждый пиксель на границе каждой фигуры.
Следующим шагом является аппроксимация каждого контура, уменьшение общего количества вершин и, как следствие, удаление некоторых деталей на уровне пикселей. Это достигается с помощью approxPolyDP:
const EPSILON = 10; const rectangles = []; for (let i = 0; i < contours.size(); ++i) { const approximatedContour = new cv.Mat(); cv.approxPolyDP(contour, approximatedContour, EPSILON, true); // is it a rectangle contour? if (approximatedContour.size().height === 4) { rectangles.push({ coord: Array.from(approximatedContour.data32S), area: cv.contourArea(approximatedContour) }); } approximatedContour.delete(); } Вышеописанное повторяется над каждой из контуров, получает аппроксимацию, затем определяет, имеет ли она четыре вершины, и если это так, координаты сохраняются. cv.MatКласс имеет различные свойства для получения базового буфера - в этом случае мы знаем, что контуры хранятся в виде 32-битных целых чисел со знаком, поэтому используйте data32Sметод доступа. OpenCV также имеет различные утилитарные методы для характеристики контуров, в этом случае contourAreaметод используется для получения области. Самым большим четырехгранным контуром считается сетка судоку.
Передаваемое EPSILONзначение approxPolyDPявляется довольно важным, оно детализирует точность аппроксимации, причем более высокие значения допускают большее отклонение между аппроксимируемым контуром и оригиналом. Поиск подходящего значения для этого параметра включает в себя довольно много экспериментов - что является повторяющейся темой при работе с компьютерным зрением и машинным обучением!
На следующем рисунке показаны приближенные контуры, цвет которых определяется числом вершин:

На приведенном выше изображении контуры с темно-зеленоватым цветом имеют четыре вершины - вы можете видеть, что некоторые квадраты в сетке судоку были аппроксимированы более чем четырьмя вершинами, и в результате более высокое значение Эпсилона может быть уместным.
Обратное Преобразование Перспективы
Следующим шагом является использование геометрического преобразования для того, чтобы создать изображение только с сеткой судоку, преобразованной таким образом, что это квадрат. Еще раз, OpenCV имеет необходимые инструменты!
Следующий код используется getPerspectiveTransformдля создания подходящего преобразования с учетом 4 вершин сетки судоку и желаемого местоположения для каждого в целевом изображении te. В этом случае местом назначения является квадратный буфер с размерами 180 х 180. warpPerspectiveМетод выполняет преобразование исходного изображения.
const srcCoords = ... // the vertices from the contour detection step // destination vertices const dstCoords = [0, 180, 0, 0, 180, 0, 180, 180]; // the destination buffer const dst = cv.Mat.zeros(180, 180, cv.CV_8UC3); // create the perspective transform const srcVertices = cv.matFromArray(4, 1, cv.CV_32FC2, srcCoords); const dstVertices = cv.matFromArray(4, 1, cv.CV_32FC2, dstCoords); const perspectiveTransform = cv.getPerspectiveTransform(srcVertices, dstVertices); // apply to the image cv.warpPerspective( src, dst, perspectiveTransform, new cv.Size(180, 180), cv.INTER_LINEAR, cv.BORDER_CONSTANT, new cv.Scalar() ); Вот результат применения этого преобразования:
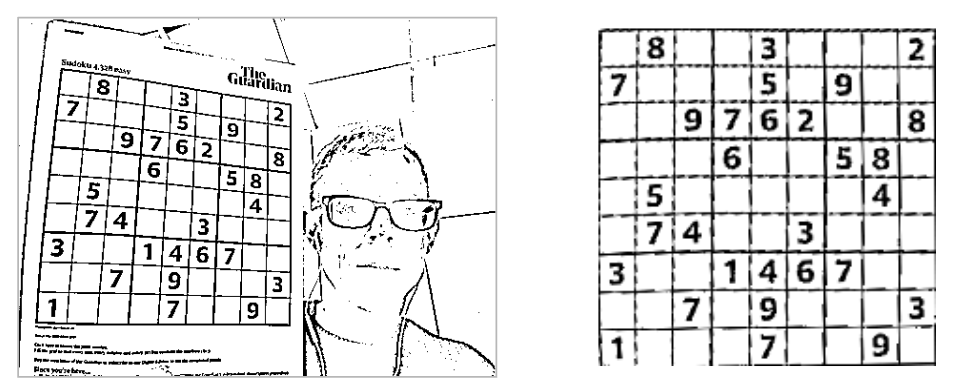
Заключительным этапом обработки является удаление линий сетки, довольно простая задача, использующая функцию Region of Interest (ROI), которая позволяет применять операции к определенным областям буферов изображений. Я не буду вдаваться в подробности здесь.
Распознавание чисел
Следующий шаг-это весело один-идентификация чисел в сетке судоку. Я изначально спустился в кроличью нору здесь ... OpenCV имеет различные примеры, которые используют каскады Хаара для распознавания лиц, и мой первоначальный подход состоял в том, чтобы обучить каскад распознавать цифры. Однако, похоже, что этот метод больше не поддерживается в OpenCV 4.x, причем предпочтительным подходом является использование сверточных нейронных сетей. Тем не менее, OpenCV.JS build, который я использую, не включает модули машинного обучения, поэтому я решил посмотреть в другом месте, остановившись на TensorFlow (который, я думаю, является гораздо лучшим вариантом!).
TensorFlow-это библиотека математики с фокусом машинного обучения,которая разрабатывается командой Google Brain. Они объявили о поддержке JavaScript в 2018 году, а поддержка WebAssembly всего несколько недель назад !
В отличие от OpenCV документация TensorFlow прекрасна-ясна, проста в использовании и актуальна ?
Тензорный поток.js имеет всесторонний проработанный пример, который охватывает процесс обучения сверточной нейронной сети (CNN) для распознавания рукописных цифр , что было отличной отправной точкой для моего решателя судоку. Однако в моем случае мне нужно обучить свою сеть распознавать печатные цифры, а не рукописные.
Если вы раньше не слышали о CNNs, я бы рекомендовал эту статью от Towards Data Science , которая включает в себя изображение ниже:
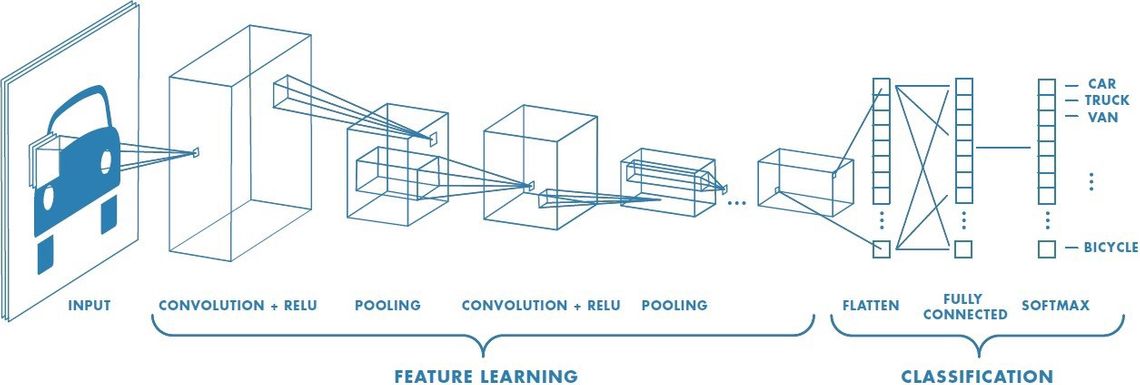
Короче говоря, CNN-это метод глубокого обучения, при котором сложная многослойная нейронная сеть изучает различные операции свертки, применяемые к изображению для распознавания объектов из заданного обучающего набора. После того, как сеть была достаточно обучена, она может распознавать объекты в новых изображениях, т. е. те, с которыми она не была обучена.
Я изменил пример из документации TensorFlow, в которой используется база данных рукописных цифр, заменив обучающие данные случайно сгенерированными цифрами. Они были представлены на холсте 20 x 20 с использованием различных шрифтов, веса шрифта и применения незначительных (рандомизированных) изменений размера шрифта, расположения и поворота.
Вот несколько примеров::

процесс обучения включает в себя представление 1000s этих цифр в CNN, наряду с ожидаемым выходом, который представляет собой набор из десяти Весов, которые указывают на вероятность того, что изображение содержит конкретную цифру. Процесс обучения вносит небольшие коррективы в различные взвешивания глубоко внутри сети, при этом весь процесс повторяется 1000 раз, пока сеть не обеспечит достаточную точность распознавания.
Один важный аспект, который я изучил методом проб и ошибок, заключается в том, что наряду с обучением сети распознавать каждую из десяти цифр, я должен также обучать ее распознавать пустые квадраты. Следовательно, мой CNN обеспечивает 11 выходных вероятностей.
После обучения сеть, включая полученные весовые коэффициенты, можно сохранить. Весь процесс был действительно довольно быстрым-около одной минуты на моей машине.
API TensorFlow позволяет выполнять несколько прогнозов за один раз. Процесс создания модели и подачи ее с данными theimage в подходящем формате действительно прост:
const model = await tf.loadLayersModel("./training/my-model-3.json"); const TOTAL_CELLS = 81; // extract the image data for each cell const testDataArray = new Float32Array(src.cols * src.rows); for (let i = 0; i < TOTAL_CELLS; i++) { // a bit of buffer mangling to obtain the image data for each cell // [ ... ] } // create a tensor that contains the data for all our cells const testTensor = tf.tensor2d(testDataArray, [TOTAL_CELLS, cellSize]); const reshaped = testTensor.reshape([TOTAL_CELLS, cellWidth, cellWidth, 1]); // make our prediction const prediction = model.predict(reshaped).dataSync(); Прогнозирование для каждой ячейки представляет собой массив из 11 значений, дающий вероятность каждой цифры, или пустую ячейку.
Следующий код создает строковое представление сетки судоку на основе прогноза для каждой ячейки:
let result = ""; for (let i = 0; i < TOTAL_CELLS; i++) { // obtain the 11 predicted states of this cell const cellPrediction = Array.from(prediction).slice(i * 11, i * 11 + 11); // what is the most likely digit for this cell? const digit = indexOfMaxValue(cellPrediction); result += digit < 10 ? digit : "."; } return result; Типичный вывод выглядит следующим образом (я вручную завернул toi в строку, чтобы было понятно, что это сетка):
...2...63 3....54.1 ..1..398. .......9. ...538... .3....... .263..5.. 5.37....8 47...1... Я надеялся использовать WebAssembly build of TensorFlow, однако я наткнулся на загвоздку. Текущий релиз находится в alpha и не поддерживает все функции TensorFlow - при использовании alpha build он жаловался, что fusedBatchMatMulоперация отсутствовала в ядре. Похоже, мне придется подождать еще немного, прежде чем я смогу использовать его!
Решение головоломки
Поскольку и OpenCV, и TensorFlow являются библиотеками C++, я подумал, что было бы интересно немного перепутать вещи и использовать Rust для следующего шага.
Sudoko Solvers похожи на игру жизни, оба являются популярными проблемами программирования, и это не заняло много времени, чтобы найти приличный выглядящий решатель, написанный в ржавчине .
RUST tooling для WebAssembly действительно первоклассный, учитывая, что мои знания о ржавчине (очень) ограничены, я смог встать и с помощью полнофункционального решателя менее чем за час. Я использовал шаблон wasm-pack, следуя инструкциям в книге Rust ? и WebAssembly?, чтобы создать свой скелетный проект. Затем я добавил ящик судоку и обновил созданный код следующим образом:
mod utils; use sudoku::Sudoku; use wasm_bindgen::prelude::*; // When the `wee_alloc` feature is enabled, use `wee_alloc` as the global // allocator. #[cfg(feature = "wee_alloc")] #[global_allocator] static ALLOC: wee_alloc::WeeAlloc = wee_alloc::WeeAlloc::INIT; #[wasm_bindgen] pub fn solve(sudoku_line: String) -> String { let sudoku = Sudoku::from_str_line(&sudoku_line).unwrap(); if let Some(solution) = sudoku.solve_unique() { let line = solution.to_str_line(); let line_str: &str = &line; return line_str.to_string(); } else { return String::from(""); } } #[wasm_bindgen]Директива (если это то, что они называются в ржавчине!) указывает, что эта функция выставляется модулем, в этом случае это solveфункция, которая принимает сетку судоку в качестве строки, а затем возвращает решение (также в виде строки).
Следующая команда строит проект, с webцелью, указывающей, что этот модуль будет использоваться браузером (т. е. модуль wasm должен быть получен через HTTP, а не API файловой системы узла):
$ wasm-pack build --target web Результатом этой сборки является небольшой (70 КБ) модуль wasm и сопутствующий файл JavaScript, который извлекает модуль wasm и адаптирует функции, выполняя различные преобразования типов. Здесь добавляется большая часть значения, WebAassembly поддерживает только числовые типы, однако приведенный выше код экспортирует функцию со строковым аргументом и возвращаемым значением. Wasm-bindgen проект, автоматически генерирующий привязки для упрощения связи между JavaScript и Rust (компилируется в WebAassembly), в этом случае он обрабатывает кодирование и декодирование строк в линейную память, что значительно снижает усилия, связанные с использованием кода Rust в интернете.
Использование этого модуля WebAssembly не может быть проще:
import initWasmModule, { solve } from "../../rust-solver/pkg/sudoku_wasm.js"; await initWasmModule(); const puzzle = "...2...63....." // etc ... const solution = solve(puzzle); Рендеринг решения и слияние
Последние несколько шагов действительно довольно просты, я не буду углубляться в детали, вы уже видели методы на практике.
Решение выводится на новое изображение 180 x 180, используя API Canvas для вывода каждой цифры. OpenCV getPerspectiveTransformи warpPerspectiveметод используются для проецирования этого обратно на исходное изображение, только на этот раз координаты источника и назначения меняются местами. Наконец, это изображение сливается с оригиналом, чтобы дать решение.
Вот окончательное объединенное изображение:

Я уверен, что должен выглядеть счастливее с конечным результатом!
Если вы хотите попробовать его для себя , проект размещается на страницах GitHub, и исходный код также доступен . Пожалуйста, обратите внимание, поскольку это был забавный проект, я не хотел тратить время (и угнетать себя), свернув, транспонировав или полифудируя. Если Ваш браузер не поддерживает модули ES, async / await и различные другие современные функции, он не будет работать для вас!
Выводы
Это был забавный хобби-проект и аккуратная демонстрация того, как WebAssembly позволяет использовать целый ряд различных библиотек, написанных на разных языках (даже если я не мог фактически использовать сборку wasm TensorFlow).
Конечные приложения работают довольно хорошо, распознавая сетки судоку в различных различных ориентациях с множеством различных шрифтов и стилей визуализации. Одна вещь, с которой он борется,-это размытие движения, я обнаружил, что если я перемещаю сетку довольно быстро, размытие изображения препятствует первоначальному адаптивному пороговому обнаружению края.
Что касается скорости обработки, то на моем компьютере требуется около 70 мс для выполнения полного конвейера (порог, контур, решатель, слияние,...), которого достаточно. На моем iPhone он заметно медленнее, и частота кадров на самом деле недостаточно хороша для достижения иллюзии, которую пытается представить AR. Я уверен, что есть место для улучшения, например, я не тратил много времени на эксперименты с размером изображения, уменьшение разрешения сетки (которое в настоящее время составляет 180 x 180) значительно улучшило бы производительность. Кроме того, пул веб-работников может использоваться для параллельной обработки этого конвейера.
Более радикальные изменения могут быть сделаны, складывая некоторые из этапов обработки в CNN, возможно, можно будет обучить сеть распознавать сетку в немодифицированном исходном изображении. Однако это потребует значительных инвестиций в сбор учебных данных и может не дать более высокой точности.
Последнее замечание, в то время как основная часть работы в настоящее время выполняется в различных модулях WebAssembly, написанных на C++ и Rust, все еще существует довольно много JavaScript-кода клея, необходимого для координации приложения. Недавно объявленные предложения типов интерфейсов должны в конечном итоге устранить необходимость написания кода JavaScript для связи между модулями wasm, написанными на разных языках. Через несколько лет я мог бы, возможно, написать свой конвейер решателя в Go, напрямую связываясь с моей библиотекой машинного зрения C++ и моим решателем ржавчины!
Телеграм: t.me/ainewsline
Источник: blog.scottlogic.com