Сжатие изображений с помощью нейросетей
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2020-01-23 02:50

Исследователи из Tel-Aviv University предложили нейросетевую архитектуру для сжатия изображений. Нейросеть использует стороннюю информацию (Side Information) при генерации сжатого изображения. Исследователи протестировали нейросеть на датасете KITTI. Модель позволяет сжимать изображения сильнее с меньшим искажением, чем альтернативные подходы.
Описание проблемы
Задача Deep Image Compression предполагает использование нейросети для сжатия изображения. Нейросеть выучивает представления изображений из данных, вместо того чтобы опираться на вручную составленные, как это происходит в стандартных подходах. Для всех методов сжатия изображений существует ограничение на допустимый уровень сжатия. Допустимая граница определяется в соответствии с соотношением уровня сжатия и уровня искажения оригинального изображения. Это соотношение описывается кривой rate-distortion. Кривая показывает, какой минимальный уровень искажения будет у изображения при определенном уровне сжатия. Это ограничение можно обойти, если ввести стороннюю информацию (side information), которая помогает нейросети сильнее сжать изображение.
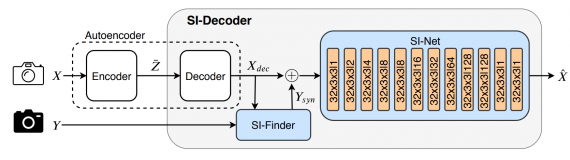
Что внутри модели
Энкодер имеет доступ к входному изображению, а декодер имеет доступ к
изображению, которое скоррелировано с входным. Сторонняя информация о входном изображении получается с помощью упомянутого скоррелированного изображения.
Архитектура состоит из двух подсетей:
- Автоэнкодер, который сжимает входное изображение и основывается на модели Mentzer et al.;
- Декодер принимает на вход сгенерированное сжатое изображение и скоррелированное с входным изображение и использует их, чтобы сгенерировать изображение с использованием сторонней информации. Затем изображение, которое сгенерировал автоэнкодер, и изображение, которое сгенерировал декодер объединяются в итоговое изображение
Вся нейросеть из двух подсетей обучается совместно. На инференсе энкодер использует часть энкодера в автоэнкодере, а декодер использует остальную часть нейросети.
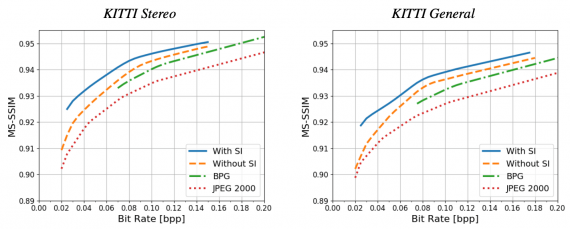
Тестирование работы алгоритма
Исследователи тестировали систему на двух версиях KITTI датасета. В первой версии исследователи использовали KITTI Stereo, чтобы симулировать сценарий стереокамеры. Во втором кейсе были использованы пары изображений из KITTI Stereo, которые были сделаны за несколько кадров друг от друга. Последний случай описывает сценарий, когда изображение загрузили в облако, а другое изображение той же локации используется как сторонняя информация.
В качестве метрики исследователи использовали среднюю rate-distortion кривую с MS-SSIM. Вариации предложенной модели сравнили с подходами JPEG 2000 и BPG.
Телеграм: t.me/ainewsline
Источник: neurohive.io