Давно собирался написать статью о numba и о сравнении её быстродействия с си. Статья про хаскелл «Быстрее, чем C++; медленнее, чем PHP» подтолкнула к действию. В комментариях к этой статье упомянули о библиотеке numba и о том, что она магическим образом может приблизить скорость выполнения кода на питоне к скорости на си. В данной статье после небольшого обзора по numba (часть 1) чуть более подробный разбор этой ситуации (часть 2).

Главным недостатком питона принято считать его скорость. Разгонять python с переменным успехом стали чуть ли не с первых дней его существования: shedskin, psyco, unladen shallow, parakeet, theano, nuitka, pythran, cython, pypy, numba.
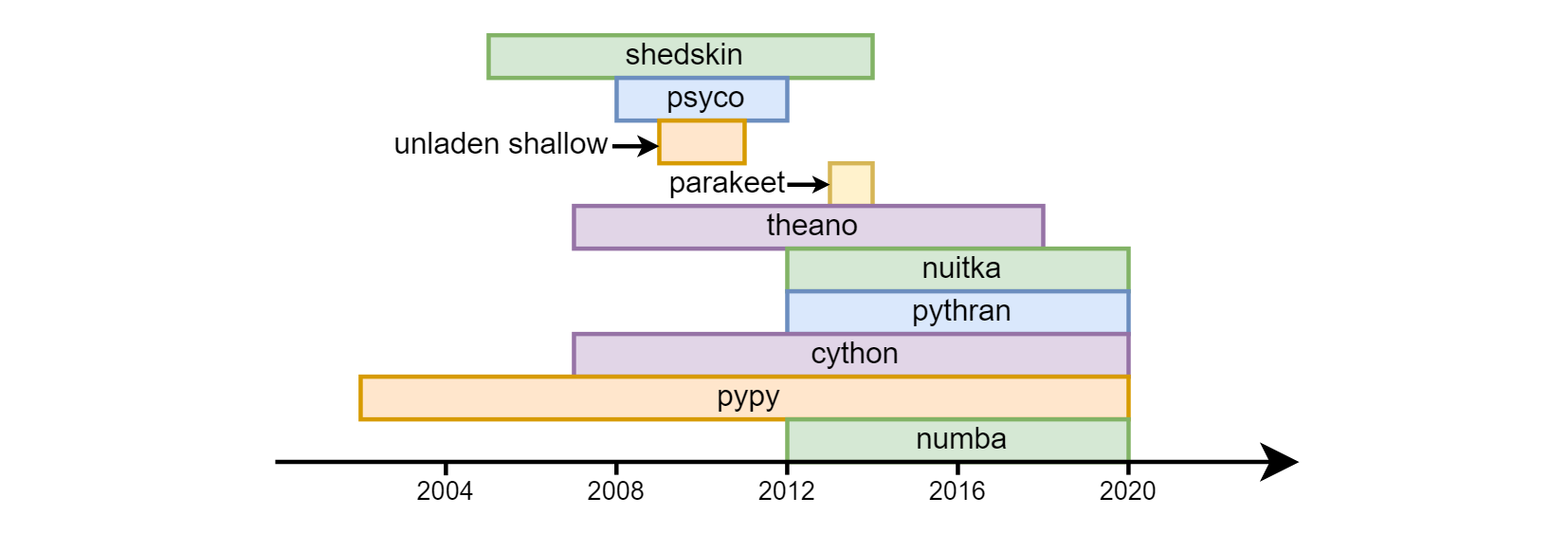
Cython (не путать с cpython) — довольно сильно отличается семантически от обычного питона. Фактически это отдельный язык — некий гибрид си и python. Что касается pypy (альтернативная реализация транслятора python с использованием jit-компиляции) и numba (библиотека для транскомпиляции кода в llvm) – они пошли разными путями. В pypy изначально была заявлена поддержка всех конструкций python. В numba же исходили из того, что чаще всего требует ускорения (cpu bound) — математические вычисления, соответственно, они выделили часть языка, связанную с вычислениями и начали разгонять её, постепенно увеличивая «охват» (например, до недавнего времени не было поддержки строк, сейчас она появилась). Соответственно, в numba разгоняется не вся программа, а отдельные функции, это позволяет совместить высокую скорость и обратную совместимость с библиотеками, которые numba (пока) не поддерживает. Numpy поддерживается (с незначительными ограничениями) и в pypy, и в numba. 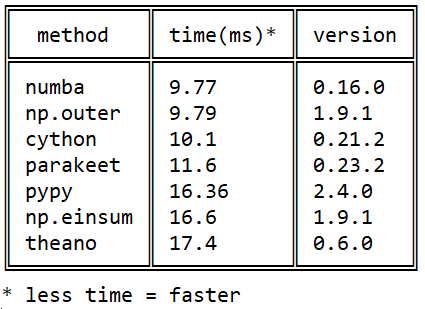 Моё знакомство с Numba началось в 2015 году вот с этого вопроса на stackoverflow про скорость умножения матриц на питоне: Efficient outer product in python
Моё знакомство с Numba началось в 2015 году вот с этого вопроса на stackoverflow про скорость умножения матриц на питоне: Efficient outer product in python
С тех пор произошло много событий в каждой из библиотек, но качественно картина в отношении numba/cython/pypy не изменилась: numba обгоняет cython за счёт использования нативных процессорных инструкций (cython не умеет jit), а pypy – за счёт более эффективного выполнения байткода llvm.
Мне numba пригождается по работе (обработка гиперспектральных изображений) и в преподавании (численное интегрирование, решение дифф.уравнений).
как установить
Еще пару лет назад были проблемы с установкой, сейчас всё разрешилось: одинаково хорошо устанавливается и через pip install numba, и через conda install numba. llvm подтягивается и устанавливается при этом автоматически.
как ускорять
Чтобы ускорить функцию, надо перед её определением вписать декоратор njit:
from numba import njit @njit def f(n): s = 0. for i in range(n): s += sqrt(i) return sУскорение в 40 раз.
Корень нужен, потому что иначе numba распознает сумму арифметической прогрессии(!) и вычислит её за константное время.
jit vs njit
Раньше был актуален режим просто @jit (а не @njit). Смысл в том, что в этом режиме можно использовать неподдерживаемые нумбой операции: нумба на большой скорости доходит до первой такой операции, затем замедляется, и до конца функции исполнение продолжается с обычной питоновской скоростью, даже если больше в функции ничего «запретного» не встречается (т.н. object mode), что, очевидно, нерационально. Сейчас от @jit постепенно отказываются, рекомендуется всегда пользоватся @njit (или в полной форме @jit(nopython=True)): в этом режиме нумба ругается исключениями на такие места – всё равно лучше их переписать, чтобы не потерять в скорости.
что умеет разгонять
В разогнанных функциях можно использовать только часть функционала питона и нумбы. Все операторы, функции и классы делятся в отношении нумбы на две части: те, которые нумба «понимает» и те, которые она «не понимает».
В документации по numba есть два таких списка (с примерами):
Из примечательного в этих списках:
- нумба «понимает» питоновские списки с быстрым (амортизированное O(1)) добавлением в конец, которые «не понимает» numpy (правда, только однородные – из элементов одного типа),
- numpy'евские массивы, которые отсутствуют в базовом питоне. Понимает также
- кортежи (tuples): они могут, как и в обычном питоне, содержать элементы разных типов.
- словари (dict): в numba своя реализация типизированного словаря. Все ключи должны быть одного типа, ровно как и значения. Питоновский dict нельзя передать в numba, зато нумбовский
numba.typed.Dictможно создавать в питоне и передавать в/из нумбы (при этом в питоне он работает чуть медленнее питоновского). - с недавних пор str и bytes, правда, только в качестве входных параметров, создавать их (пока?) нельзя.
Никакие другие библиотеки (в частности, scipy и pandas) она не понимает совсем.
Но даже того подмножества языка, которое она понимает, достаточно, чтобы разогнать большую часть кода для научных приложений, на которые numba в первую очередь и ориентирована.
важно!
Из разогнанных функций можно вызывать только разогнанные, не разогнанные нельзя.
(хотя разогнанные функции можно вызывать и из разогнанных и из не разогнанных).
globals
В разогнанных функциях глобальные переменные становятся константами: их значение фиксируется на момент компиляции функции (пример). => Не используйте глобальные переменные в разогнанных функциях (кроме констант).
сигнатуры
В нумбе каждой функции сопоставляется один или несколько типов входных и выходных аргументов, т.н. сигнатуры. При первом вызове функции сигнатура формируется и автоматически компилируется соответствующий бинарный код функции. При запуске с другими типами аргументов будут создаваться новые сигнатуры и новые бинарники (старые при этом сохраняются). Таким образом, «выход на режим» по скорости исполнения для каждой сигнатуры наступает, начиная со второго запуска с этими типами аргументов. Так что надо либо
- «прогревать кэш», запуская с небольшими размерами входных массивов, либо
- указывать аргумент
@jit(cache=True)для сохранения скомпилированного кода на диск с автоматической его загрузкой при последующих запусках программы (правда на практике на сегодняшний день этот первый запуск всё равно немного медленнее, чем последующие, но быстрее, чем безcache=True).
Есть ещё третий способ. Сигнатуры можно задавать вручную:
from numba import int16, int32 @njit(int32(int16, int16)) def f(x, y): return x + y >>> f.signatures [(int16, int16)]При запуске функции с сигнатурой, указанной в декораторе, уже первый запуск будет быстрым: компиляция произойдёт в тот момент, когда питон увидит определение функции, а не при первом запуске. Сигнатур может быть несколько, порядок их следования имеет значение.
Предупреждение: этот последний способ не future-safe. Авторы numba предупреждают о том, что синтаксис указания типов может измениться в будущем, @jit/@njit без сигнатур – более безопасный в этом плане вариант.
f.signatures начинают показывать сигнатуры только тогда, когда питон о них узнает, то есть после первого вызова функции, либо если они заданы вручную.
Кроме f.signatures сигнатуры можно посмотреть через f.inspect_types() – кроме типов входных параметров эта функция покажет типы выходных параметров, а также типы всех локальных переменных.
Кроме типов входных и выходных параметров, есть возможность вручную указать типы локальных переменных:
from numba import int16, int32 @njit(int32(int16, int16), locals={'z': int32}) def f(x, y): z = y + 10 return x + zint
В нумбе у целых чисел нет длинной арифметики как в «просто» питоне, но есть стандартные типы различной ширины от int8 до int64 (таблица типов в документации). Есть ещё типы int_ (а также float_), используя которые вы предоставляете нумбе возможность выбрать оптимальную (с её точки зрения) ширину поля.
классы
Поддержка классов (@jitclass) вообще есть, но пока она экспериментальная, так что лучше пока избегать их использования (на текущий момент, по моему опыту, с ними сильно медленнее, чем без них).
custom dtypes
В numba поддерживается некая альтернатива классам из numpy – структурные массивы (structured array), или, иначе говоря, пользовательские dtype'ы. Они работают с той же скоростью, что и обычные массивы numpy, их чуть удобнее индексировать (например, a['y2'] более читаемо, чем a[3]). Интересно, что в numba, в отличие от numpy, наряду с обычным синтаксисом a['y2'] допускается более лаконичный a.y2. Но в целом их поддержка в numba оставляет желать лучшего, и некоторые очевидные даже в numpy операции с ними в нумбе записываются достаточно нетривиально.
GPU
Умеет выполнять разогнанный код на GPU, причём в отличие от того же, например, pycuda или pytorch, не только на nvidia, но и на amd'шных карточках. С этим пока разбирался мало. Вот статья на хабре 2016 года Сравнение производительности GPU-расчетов на Python и C. Там получилась сопоставимая с С скорость.
ahead-of-time компиляция
В нумбе есть режим обычной (то есть не jit) компиляции (документация), но этот режим является не основным, я с ним не разбирался.
автоматическое распараллеливание
Некоторые задачи (например, умножение матрицы на число) распараллеливаются естественным образом. Но есть такие задачи, выполнение которых распараллелить не получается. С декоратором @njit(parallel=True) нумба анализирует код разгоняемой функции, находит такие участки, каждый из которых самого по себе распараллелить невозможно, и выполняет их одновременно на разных ядрах CPU (документация). Раньше распараллеливать функции можно было только вручную при помощи @vectorize (документация), что требовало изменения кода.
На практике это выглядит так: добавляем parallel=True, замеряем скорость, если повезло и получилось быстрее – оставляем, медленнее – убираем. (**Update Как отметили в комментарии ко второй части статьи, по этому флагу много открытых багов)
освобождение GIL
Функции, декорированные @jit(nogil=True) и запущенные в разных потоках, могут исполняться параллельно. Для избежания race conditions необходимо использовать синхронизацию потоков.
документация
Нумбе до сих пор не хватает толковой документации. Она есть, но в ней есть не всё.
оптимизация
Есть некоторая непредсказуемость при оптимизации кода вручную: unpythonic код зачастую работает быстрее, чем pythonic.
Заинтересовавшимся темой могу порекомендовать видео мастер-класса по numba с конференции scipy 2017 (есть исходники на гитхабе). Оно правда длинновато и частично устарело (например, строки уже поддерживаются), но общее представление получить помогает: там есть, в частности, про pythonic/unpythonic, jit(parallel=True) и пр.
Во второй части рассмотрим применение numba на примере кода из упомянутой в начале статьи.