Обучение модели обнаружения объектов YOLO на пользовательском наборе данных
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2020-01-22 12:10

Нейросетевые модели обнаружения объектов делают много полезного. Классифицируют автомобили, определяют злокачественные образования на медицинских изображениях, сегментируют объекты со спутниковых снимков. Тем не менее, одно из серьёзных препятствий, мешающих новым применениям – проблема адаптации доступных ресурсов и моделей к нестандартным задачам.
В этой публикации мы расскажем, как подготовить собственный набор данных для обнаружения необходимых объектов и провести обучение на модели распознавания YOLO.
Наш план. Работа с проблемой машинного обучения начинается с правильно сформулированной задачи. Далее вы собираете и подготавливаете данные, обучаете и корректируете модель, пока, наконец, не получите результат – распознавание необходимых объектов. Процесс может и не быть таким линейным. Например, вы можете обнаружить, что модель работает плохо на одном типе меток изображения. Тогда нужно вернуться к сбору большего количества данных для этой категории.
Постановка задачи
Конкретный пример. В качестве примера возьмём игру в шахматы. Чтобы совершенствовать навык игры, необходимо фиксировать и понимать ошибки. Определять, какие ходы идеальный игрок мог сделать в той же ситуации. Играть вживую интереснее и приятнее, чем на компьютере или телефоне. Поставим задачу создать систему, которая в реальном времени распознаёт состояние живой игры и записывает каждый ход.
Постановка задачи. Описанный пример потребует не только определения того, что собой представляет шахматная фигура, но и положения фигуры на доске. Нужно совершить скачок от простого распознавания объекта к одновременному обнаружению и фиксации положения объектов. Чтобы пока не усложнять задачу, в этой публикации мы сосредоточимся на обнаружении объектов. Мы должны обучить модель определять тип шахматной фигуры и её цвет (чёрный или белый), то есть принадлежность игроку.
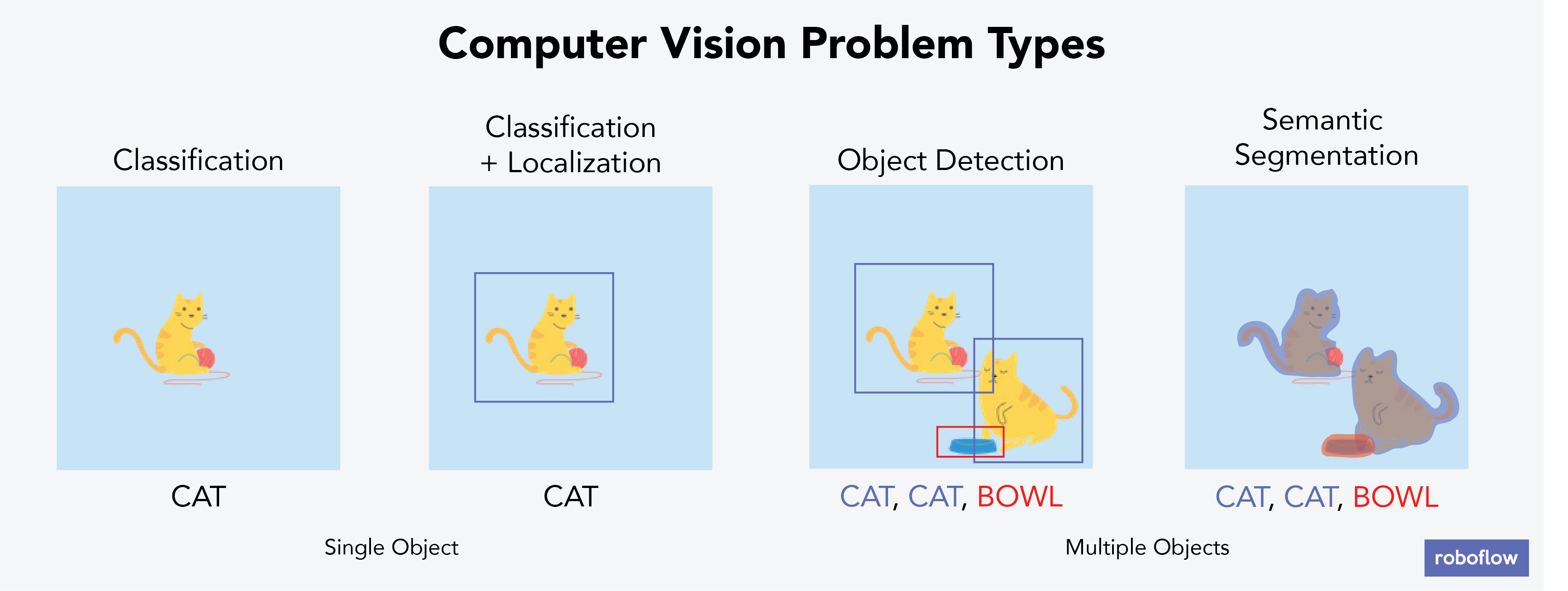
В общем случае для постановки задачи, не связанной с шахматами, нужно заранее подумать об ограничении пространства задачи конкретными элементами. Также рассмотрите минимально приемлемые критерии производительности модели. Например, какая вероятность распознавания объекта вас устроит.
Сбор данных
Чтобы идентифицировать шахматные фигуры, нужно собрать и проаннотировать изображения шахмат. Как было пояснено выше, нам интересны не шахматные фигуры сами по себе, а шахматы внутри партии. Поэтому пришлось сделать пару упрощений.
- Все изображения были сняты под одним углом. Штатив был поставлен на стол возле шахматной доски. Для работы модели на практике это требует, чтобы камера находилась под тем же углом, что и данные для обучения.
- Было создано всего 12 классов: по одному на каждую из шести фигур для двух цветов. Каждому классу соответствовали только фигуры из конкретного набора шахмат

Обучающие данные. Было собрано 292 изображения с различными положениями фигур на шахматной доске. Все фигуры были помечены, вышло 2894 аннотации. Получился общедоступный набор данных. Для маркировки существует множество качественных бесплатных инструментов с открытым исходным кодом, таких как LabelImg. Но в примере использовался RectLabel, который стоит 3 доллара в месяц.
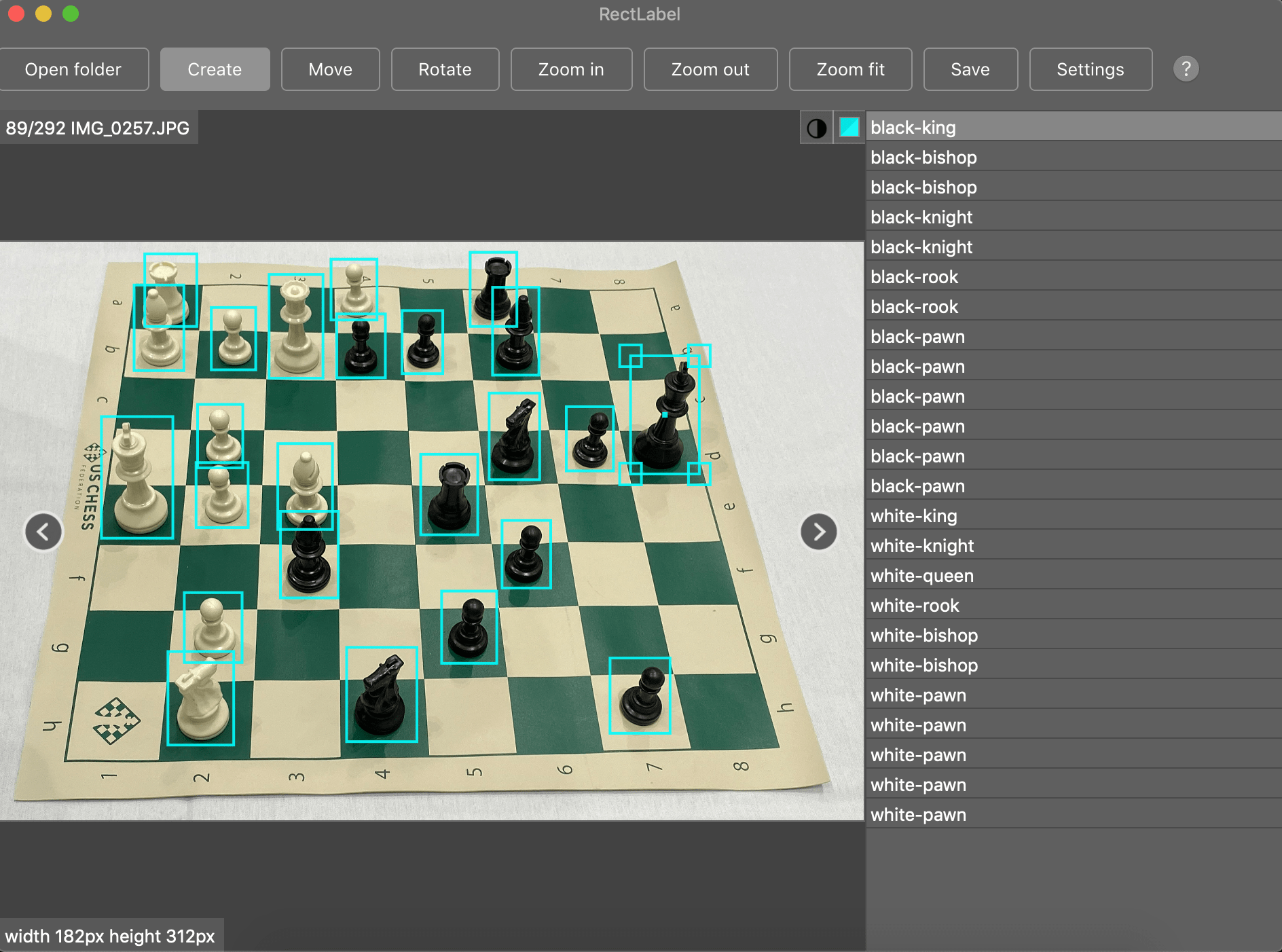
В общем случае. Для решения проблемы, не связанной с шахматами, рассмотрите возможность сбора изображений в контексте того, где ваша модель будет работать в производстве. Очень часто камеры находятся только в одной конкретной позиции. В этом случае у вас будут одни и те же углы наблюдения и, возможно, условия освещения. Но чем больше ситуаций учитывает обучающая выборка, тем производительнее будет модель.
Будьте внимательны с рамками. При маркировке лучше рисовать ограничивающие рамки, включающие объект целиком, не обрезая его. Если один объект перекрывает другой, пометьте перекрываемый так, как если бы вы могли его видеть. Посмотрите, как это сделано на рисунке выше для белого слона и белой ладьи в левом верхнем углу.
Если вы ищете уже аннотированные изображения, рассмотрите наборы данных на Kaggle.
Подготовка данных
Переход напрямую от сбора данных к обучению модели обычно приводит к неоптимальным результатам. Подготавливая изображения для детектирования, выполните следующие действия:
- Проверьте корректность аннотаций. Например, аннотации не должна выходить за рамки изображения.
- Обеспечьте правильную ориентацию в EXIF. Это одна из распространённых ошибок – изображения на диске хранятся обычно не так, как вы видите их в приложениях. Подробно об этом писал Адам Гейтджи.
- Измените размер изображений и обновите аннотации для соответствия новым размерам.
- Проведите цветовую коррекцию.
- Отформатируйте аннотации в соответствии с требованиями входных данных модели (например, нужно создать TFRecords для TensorFlow или простой текстовый файл для некоторых реализаций YOLO).
Подобно табличным данным, очистка и аугментация данных могут повысить производительность конечной модели больше, чем вариация архитектуры модели.
Предобработанные данные по нашей задаче тоже размещены в общем доступе.
В рассматриваемом случае вместо исходных изображений размером 2284?1529 использовались уменьшенные изображения 416x416.
- Изображения меньшего размера позволяют быстрее обучаться.
- Архитектура YOLOv3 более эффективно работает с изображениями, размеры которых кратны 32x32.
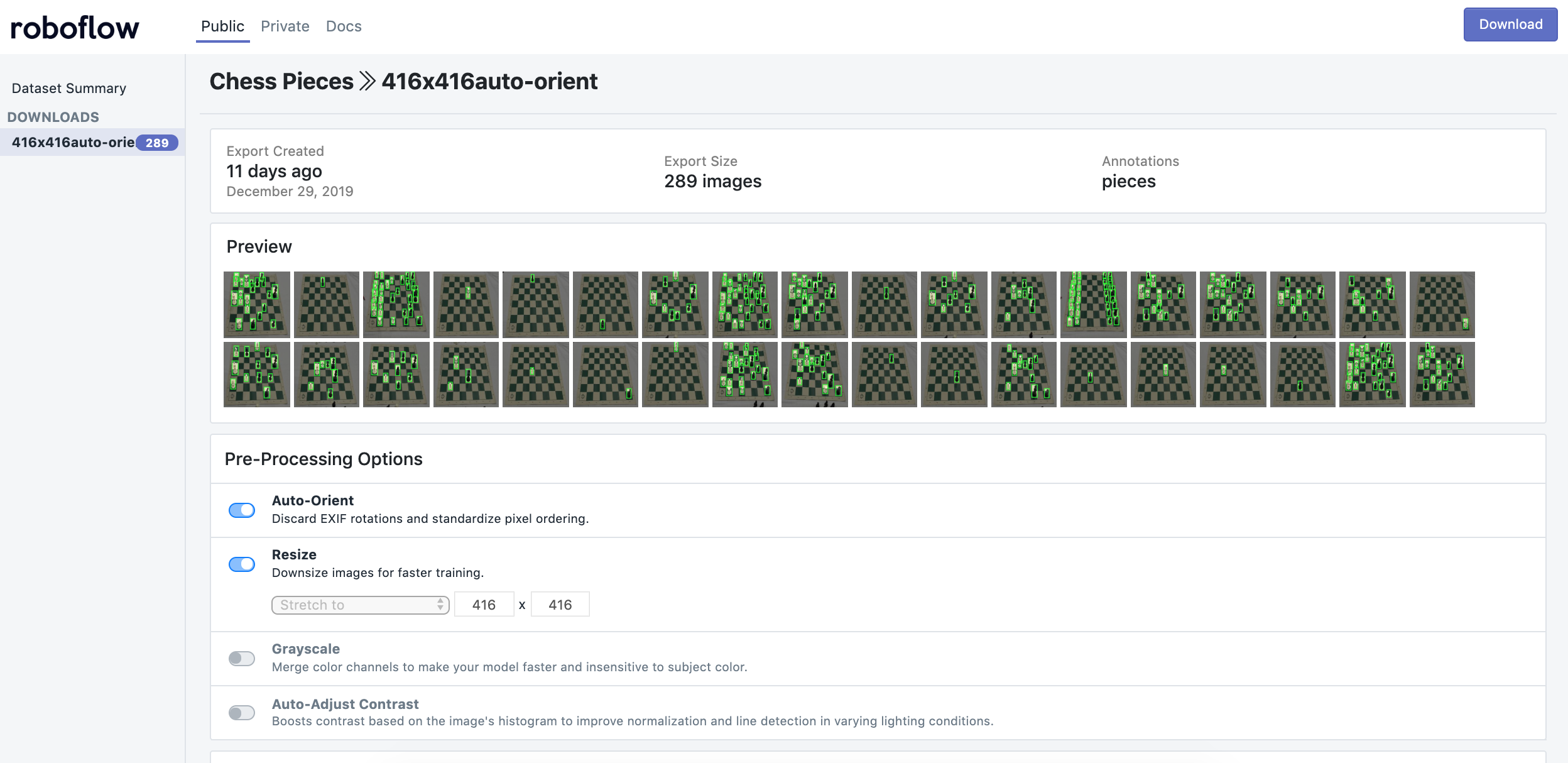
С помощью сервиса Roboflow к изображениям был применён ресайзинг и автоориентация, решающая описанную выше проблему с EXIF-данными. Roboflow также генерирует код, который можно перетащить непосредственно в блокнот Jupyter, включая Colab, и использовать так предподготовленные данные.
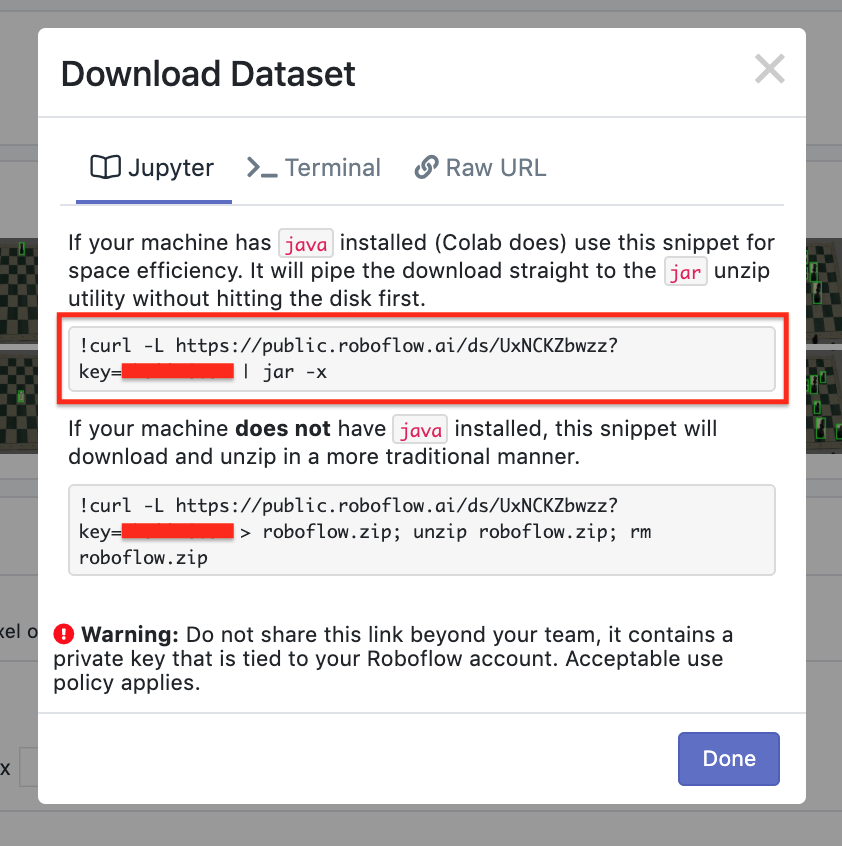
Подробнее о Roboflow написано на странице Быстрый старт.
Обучение модели
Архитектура, которую мы будем использовать, предложена Джозефом Редмоном и называется YOLO. Это сокращение от You Only Look Once, что на английском означает «Вы смотрите только один раз». То есть цифровые данные изображения проходят через нейронную сеть лишь единожды. За счёт этого предсказательная модель производительна, и анализирует до 60 кадров в секунду. Поэтому YOLO часто используют для видеопотоков. Если вам интересно лучше изучить архитектуру модели, рекомендуем прочесть эту публикацию.
Несмотря на то что мы обучаем модель на собственном наборе данных, выгодно не обучать её с чистого листа, а применить «перенос обучения». То есть использовать в качестве отправной точки веса от другой, уже обученной модели. Здесь работает следующая аналогия: чтобы забраться на конкретное место горы быстрее, мы идём не случайным образом, а по проложенной ранее тропинке.
Для поддержки вычислений модели мы будем использовать Google Colab, который предоставляет бесплатные вычислительные ресурсы на GPU, до 24 часов при открытом браузере. Соответствующий пример блокнота на Colab.

В нашем блокноте мы делаем шесть вещей:
- Выбираем среду, модель архитектуры и предварительно подобранные веса (чужой «след»).
- Загружаем данные с помощью сниппета из Roboflow.
- Определяем конфигурацию модели, например, количество эпох обучения, размеры пакетов, размер набора для теста, скорость обучения.
- Инициируем тренировку (... и ждём).
- Используем обученную модель для прогноза.
- Опционально: сохраняем модель с новыми весами в Google Drive, чтобы далее делать прогнозы, не дожидаясь окончания обучения.
Если вы используете аналогичный подход для решения вашей задачи, для обучения на той же архитектуре нужно всего лишь изменить URL-адрес загрузки данных из Roboflow. Кроме того, вы можете поиграть с параметрами обучения (например, скорость обучения, число эпох).
Применение модели
В приведённом выше примера блокнота прогноз происходит при вызове скрипта yolo_video.py. Этот сценарий принимает путь к видеофайлам или изображениям, пользовательские веса, привязки (не рассматривались в этом примере), классы, количество используемых графических процессоров, флаг, описывающий, прогнозируем ли мы изображение иди видео, и, наконец, выходной путь для предсказанного видео или изображения.
Сценарий компилирует модель, ожидает ввода в файл изображения и предоставляет координаты ограничивающих рамок и имя класса для любых найденных объектов. Координаты рамки предоставляются в формате пикселей нижнего левого угла (min_x, min_y) и пикселей верхнего правого угла (max_x, max_y).
Пользовательские веса, которые мы загружаем в этом примере, на самом деле не самые лучшие в архитектуре YOLO. Из-за ограничений Colab модель не может рассчитать конечные веса. Это означает, что модель не так эффективна, как могла бы быть. С другой стороны, это вычисления выполнены бесплатно. На видео выше показан процесс детектирования перемещения фигур на доске.
Заключение
Использование модели в производстве ставит вопрос о том, какой будет ваша производственная среда. Например, будете ли вы запускать модель в мобильном приложении, через удалённый сервер или на Raspberry Pi. То, как вы будете использовать модель, определяет наилучший способ хранения и преобразования форматов.
Следующие ресурсы могут помочь в реализации на вашей платформе:
- преобразование в TFLite (для Android и iPhone)
- преобразование в CoreML (для приложений iPhone)
- развёртывание модели на Raspberry Pi
Удачно вам всё распознать! :-)
Источники
Телеграм: t.me/ainewsline
Источник: proglib.io