Нейросеть генерирует видео с говорящим человеком по аудиозаписи
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2020-01-17 12:00
Исследователи из SenseTime опубликовали генеративную нейросеть, которая воспроизводит видеозапись говорящего человека по аудио с разговором. Модель принимает на вход изображение целевой персоны и аудиозапись с речью. На выходе модель отдает видеозапись с целевой персоной, на которой выражение лица персоны соответствует аудиодорожке.
Особенность подхода в его динамичности. Для рендеринга каждого человека в выборке не выучивается отдельная модель. При этом нейросеть может выдать реалистичную видеозапись для любой персоны и с любой аудиозаписью.
Как это работает
Модель состоит из сети, которая конвертирует аудио в выражение лица, и сети, которая генерирует изображения с измененной зоной рта. Получается, что на выходе аудиозапись и выражение лица целевой персоны сопоставимы.
Целевое видео с персоной рендерится так, чтобы получить реконструкцию лица. Модель выучивает такие параметры целевого лица, как выражение, геометрия и поза.
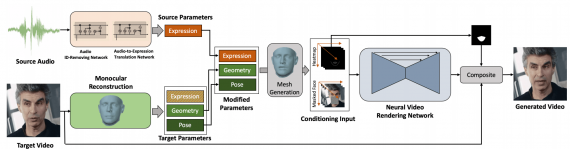
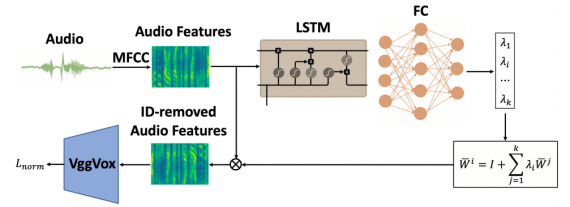
Исследователи формулируют метод адаптации спикера как нейросеть. Эта идея позаимствована из распознавания речи. Так, Audio ID-Removing блок нейросети убирает персональные особенности речи из аудиозаписи и сводит аудиозапись к звучанию “глобального спикера”. Исследователи избавляются от речевых особенностей спикеров на аудиозаписей, потому что это излишняя информация, которая добавляет больше шума в модель. После этого этапа аудиозапись поступает в рекуррентную нейросеть. Рекуррентная нейросеть конвертирует аудиозапись в набор параметров выражения лица.
Телеграм: t.me/ainewsline
Источник: neurohive.io