Как обучить нейронную сеть DeepPavlov на ноутбуке с использованием GPU
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2020-01-10 07:55
В этой статье я хочу поделиться своим опытом использования данной open-source библиотеки на примере реализации одной задачи с парсингом файлов PDF/DOC/DOCX содержащих резюме специалистов.
Здесь я также опишу этапы реализации инструмента для подготовки датасета. После чего можно будет обучить модель BERT на полученном датасете в рамках задачи распознавания сущностей из текстов (Named Entity Recognition – в дальнейшем NER).
Итак, с чего начать. Естественно для начала нужно установить и настроить среду для запуска нашего инструмента. Установку я буду выполнять на Windows 10.
На Хабре уже есть несколько статей от разработчиков этой библиотеки, где как раз есть подробная инструкция по установке. А в этой статье я хотел бы собрать все воедино, от запуска и до обучения модели. Также я укажу решения некоторых проблем, с которыми я столкнулся при работе с этой библиотекой.
ВАЖНО: при установке важно соблюдение версий всех продуктов и компонентов, так как часто возникают проблемы при несовместимости версий. Особенно это касается библиотеки TensorFlow. Бывает даже так, что для некоторых задач вплоть до нужного коммита на GitHub нужно использовать. В случае с DeepPavlov достаточно соблюдение только поддерживаемой версии.
Я укажу версии продуктов работающей конфигурации, и спецификации моего ноутбука, на котором я запускал процесс обучения нейронной сети. Я приведу несколько ссылок в которых также описан процесс установки и настройки open-source библиотеки DeepPavlov.
Полезные ссылки от разработчиков DeepPavlov
- DeepPavlov для разработчиков: #1 инструменты NLP и создания чат-ботов. Здесь описан процесс установки библиотеки на примере модели ner_ontonotes_bert_mult, которая используется для мультиязычного анализа текстов.
- DeepPavlov для разработчиков: #2 настройка и деплоймент. Здесь вы сможете найти информацию об основных важных моментах в настройке библиотеки.
Версии компонентов для установки
- Python 3.6.6 – 3.7
- Visual Studio Community 2017 (опционально)
- Visual C++ Build Tools 14.0.25420.1
- nVIDIA CUDA 10.0.130_411.31_win10
- cuDNN-10.0-windows10-x64-v7.6.5.32
Установка среды для поддержки GPU
- Установка Python или Visual Studio Community 2017 в составе с Python. В моей установке я использовал второй способ, установив Visual Studio Community с поддержкой Python.
Конечно, придется вручную добавить путь до папки
в системную переменную PATH, там где установлен Python от Visual Studio, но для меня это не проблема, для меня важно знать, что я установил одну версию для Python.C:Program Files (x86)Microsoft Visual StudioSharedPython36_64
Но это мой случай, вы можете установить все отдельно. - Cледующим шагом необходимо установить Visual C++ Build Tools.
- Далее необходимо установить nVIDIA CUDA.
ВАЖНО: если ранее была установлена библиотека nVIDIA CUDA, тогда нужно удалить все установленные ранее компоненты от nVIDIA, вплоть до видео-драйвера. И уже потом на чистую установку видео-драйвера выполнять установку nVIDIA CUDA.
- Теперь устанавливаем cuDNN для nVIDIA CUDA.
Для этого Вам необходимо зарегистрировать членство для NVIDIA Developer Program (это бесплатно).

- Скачиваем версию cuDNN для CUDA 10.0

- Распаковываем архив в папку
C:Users<имя_пользователя>DownloadscuDNN - Копируем все содержимое папки ..cuDNN в папку где у нас установлена CUDA
C:Program FilesNVIDIA GPU Computing ToolkitCUDAv10.0 - Перезагружаем компьютер. Необязательно, но я рекомендую.
Установка DeepPavlov
- Создаeм и активируем виртуальное окружение Python.
ВАЖНО: я это делал через Visual Studio.
- Для этого я создал новый проект для From Existing Python code.

- Жмем далее до последнего окна, но на Finish пока не жмем. Необходимо снять галочку «Detect Virtual Environments»

- Жмем на Finish.
- Теперь нужно создать виртуальное окружение.

- Все оставляем по-умолчанию.

- Открываем папку проекта в командной строке. И выполняем команду:
.envScriptsactivate.bat
- Теперь все готово чтобы установить DeepPavlov. Выполняем команду:
pip install deeppavlov - Далее необходимо установить TensorFlow 1.14.0 с поддержкой GPU. Для этого выполняем команду:
pip install tensorflow-gpu==1.14.0 - Почти все готово. Необходимо только убедиться, что TensorFlow будет использовать видеокарту для вычислений. Для этого напишем простенький скрипт devices.py, следующего содержания:
from tensorflow.python.client import device_lib print(device_lib.list_local_devices())
или tensorflow_test.py:
import tensorflow as tf tf.test.is_built_with_cuda() tf.test.is_gpu_available(cuda_only=False, min_cuda_compute_capability=None) - После выполнения devices.py, мы должны увидеть примерно следующее:
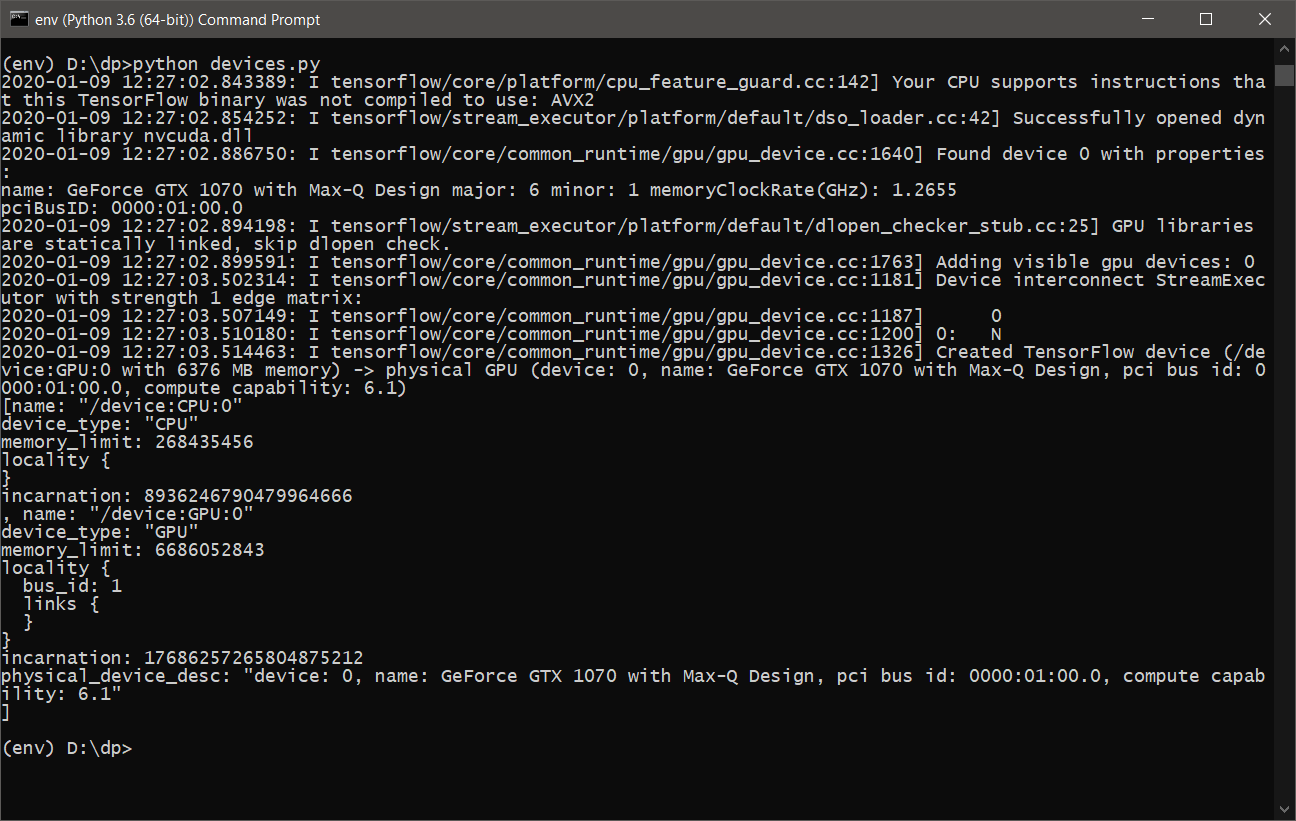
- Теперь все готово для обучения и использования DeepPavlov с поддержкой GPU.
DeepPavlov на REST API
Для того чтобы запустить и установить сервис для REST API, нужно выполнить следующие команды:
- Устанавливаем в активное виртуальное окружение
python -m deeppavlov install ner_ontonotes_bert_mult - Скачиваем модель ner_ontonotes_bert_mult с серверов DeepPavlov
python -m deeppavlov download ner_ontonotes_bert_mult - Запустить REST API
python -m deeppavlov riseapi ner_ontonotes_bert_mult -p 5005
Данная модель будет доступна по адресу http://localhost:5005. Порт можете указать свой. Все модели по-умолчанию будут скачены по пути
C:Users<имя_пользователя>.deeppavlov
Настройка DeepPavlov для обучения
Перед тем как запускать процесс обучения нам необходимо настроить конфигурацию DeepPavlov так, чтобы процесс обучения не «валился» с ошибкой от того, что память на нашей видеокарте переполнена. Для этого у нас есть файлы конфигурации для каждой модели.
Как и в примере от разработчиков, я также собираюсь использовать модель ner_ontonotes_bert_mult. Все конфигурации по умолчанию для DeepPavlov находятся по пути:
<папка_проекта>envLibsite-packagesdeeppavlovconfigs er
В моем случае файл будет называться как и модель ner_ontonotes_bert_mult.json.
Для моей конфигурации ноутбука мне пришлось поменять значение batch_size в блоке train на 4.

Иначе моя видеокарта после нескольких минут «захлёбывалась», и процесс обучения падал с ошибкой.
Конфигурация ноубука
- Модель: MSI GS-65
- Процессор: Core i7 8750H 2200 МГц
- Объём установленной памяти: 32 Гб DDR-4
- Жесткий диск: SSD 512 Гб
- Видеокарта: GeForce GTX 1070 8192 Мб
Инструмент для подготовки датасета
Для того чтобы обучить модель, нужно подготовить датасет. Датасет состоит из трех файлов train.txt, valid.txt, test.txt. С разбивкой данных в следующем процентном соотношении train – 80%, valid и test по 10%.
Датасет для BERT-модели имеет следующий вид:
Ivan B-PERSON Ivanov I-PERSON Senior B-WORK_OF_ART Java I-WORK_OF_ART Developer I-WORK_OF_ART IT B-ORG - I-ORG Company I-ORG Key O duties O : 0 Java B-WORK_OF_ART Python B-WORK_OF_ART CSS B-WORK_OF_ART JavaScript B-WORK_OF_ART Russian B-LOC Federation I-LOC . O Petr B-PERSON Petrov I-PERSON Junior B-WORK_OF_ART Web I-WORK_OF_ART Developer I-WORK_OF_ART Boogle B-ORG I O ' O ve O developed O Web B-WORK_OF_ART - O Application O . Skills O : O ReactJS B-WORK_OF_ART Vue B-WORK_OF_ART - I-WORK_OF_ART JS I-WORK_OF_ART HTML B-WORK_OF_ART CSS B-WORK_OF_ART Russian B-LOC Federation I-LOC . O ...
Формат датасета выглядит так:
<текст_токена><пробел><тип_токена>
ВАЖНО: после конца предложения обязательно должен быть перенос строки. Если предложение содержит более 75 токенов, то также необходимо поставить перенос строки, иначе при обучении модели процесс выпадет с ошибкой.
Для подготовки датасета я написал веб-интерфейс, где имеется возможность загрузить файлы DOC/PDF/DOCX на сервер, распарсить в обычный текст, а потом пропустить этот текст через активную модель с доступом по REST API сохранив при этом результат в промежуточную БД. Для этого я использую MongoDB.
После того как вышеперечисленные действия будут выполнены, можно приступать к формированию датасета под наши нужды.
Для этого в мною написанном веб-интерфейсе я сделал отдельную панель, где есть возможность осуществлять поиск по токенам датасета и затем менять тип токена и сам текст токена.
Инструмент также умеет автоматически на основе списка слов делать обновление типа у токена, указанного пользователем при запросе.
В целом инструмент помогает автоматизировать часть работы, но все равно приходится много делать ручной работы.
Интерфейс для проверки результата и разбивка датасета на три файла также реализованы.
Обучение DeepPavlov
Вот мы и добрались до самой интересной части. Для процесса обучения сначала нужно скачать модель ner_ontonotes_bert_mult, если вы это еще не сделали, то нужно выполнить первые два шага из раздела DeepPavlov на REST API выше.
Перед запуском процесса обучения необходимо выполнить два шага:
- Удалить полностью папку с обученной моделью:
C:Users<имя_пользователя>.deeppavlovmodels er_ontonotes_bert_mult
Так как эта модель обучалась на другом датасете. - Скопировать подготовленные файлы датасета train.txt, valid.txt, test.txt в папку
C:Users<имя_пользователя>.deeppavlovdownloadsontonotes
Теперь можно запускать процесс обучения.
Для запуска обучения можно написать простенький скрипт train.py следующего вида:
from deeppavlov import configs, train_model ner_model = train_model(configs.ner.ner_ontonotes_bert_mult, download=False)
или использовать командную строку:
python -m deeppavlov train <папка_проекта>envLibsite-packagesdeeppavlovconfigs er er_ontonotes_bert_mult.json
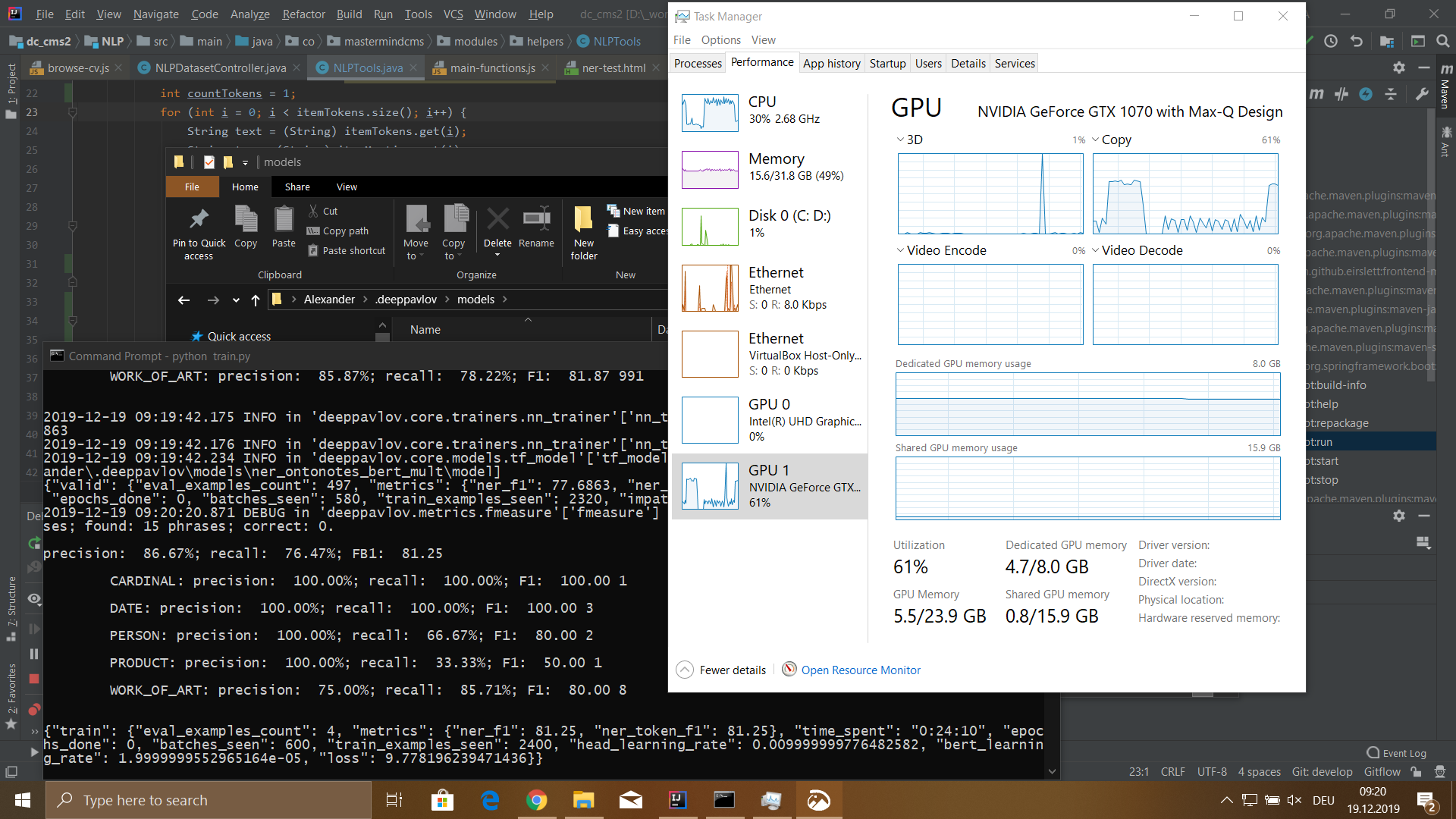
Результаты
Я обучал модель на датасете размером 115540 токенов. Этот датасет был сгенерирован из 100 файлов резюме сотрудников. Процесс обучения у меня занял 5 часов 18 минут.
Модель имела следующие значения:
- precision: 76.32%;
- recall: 72.32%;
- FB1: 74.27;
- loss: 5.4907482981681826;
После правок нескольких проблем в авто-генерации датасета, я получил loss ниже. А в целом остался доволен результатом. Конечно, у меня осталось много вопросов по использованию этой библиотеки и то, что я здесь описал, это лишь капля в море.
Библиотека мне очень понравилась своей простотой и удобством в использовании. По крайней мере для задачи NER. Буду очень рад обсудить другие возможности этой библиотеки и надеюсь кому-то будет полезен материал из этой статьи.
Телеграм: t.me/ainewsline
Источник: habr.com