Что нового в Pandas 1.0?
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2020-01-24 09:00

Pandas
Pandas – популярная библиотека Python для работы с табличными данными, добавляющая к структуре массива NumPy именованные строки и столбцы, а также множество удобных методов. Pandas является одной из важных причин, почему Python стал доминирующим языком программирования в Data Science.

Версия 1.0 Так много изменений?
На самом деле нет. Метка 1.0 не означает существенных отклонений от 0.25.3, текущей версии от 22 января 2020 года. Релиз 1.0 также не подразумевает, что библиотека вдруг достигла стадии зрелости. Pandas и так устойчиво развивается и годами используется в производственном коде. Уэс МакКинни начал работать над Pandas в ??2008 году. GitHub показывает, что на момент написания публикации модуль используется в 170 000 репозиториев.
В дополнение к обычным исправлениям ошибок и незначительной очистке API, pandas 1.0.0 представляет несколько новых особенностей. Основная из них – введение типа данных pd.NA.
pd.NA
В pandas 0.25 объект DataFrame в зависимости от содержимого столбца может иметь три разных значения для представления отсутствующих данных: np.nan, None или pd.NaT.
Самая большая несуразность относительно пропущенных значений – целочисленный столбец с пропущенным значением автоматически начинает соответствовать типу float. ?
Такое положение дел связано с тем, что Pandas базируется на библиотеке NumPy. Стремясь улучшить ситуацию, команда разработчиков создала новый класс для представления отсутствующих данных. В документации новой версии это поясняется следующим образом:
Начиная с версии 1.0, доступно экспериментальное значение
pd.NA(синглтон) для представления скалярных пропущенных значений. На данный момент он используется в целочисленном, булевом и строковом типах данных в качестве индикатора отсутствующего значения. Цельpd.NAсостоит в том, чтобы предоставить «отсутствующий» индикатор, который можно последовательно использовать в разных типах данных (вместо зависимых от типа данныхnp.nan,Noneилиpd.NaT).
Да, мы этого давно ждали. В долгосрочной перспективе общее значение для отсутствующих данных это отлично.
Недостаток нового pd.NA заключается в том, что вы не можете сравнивать его напрямую со значением в логическом условии. То есть вместо == pd.NA надо применять df.isna(), чтобы вернуть булеву маску для пропущенных значений датафрейма.
Кроме того, pd.NA ведёт себя в логических операциях не так, как другие перечисленные значения. pd.NA следует правилам троичной логики, аналогично R и SQL. Например, если одно из значений в условии or с pd.NA является True, то результатом будет True. Вот шпаргалка:
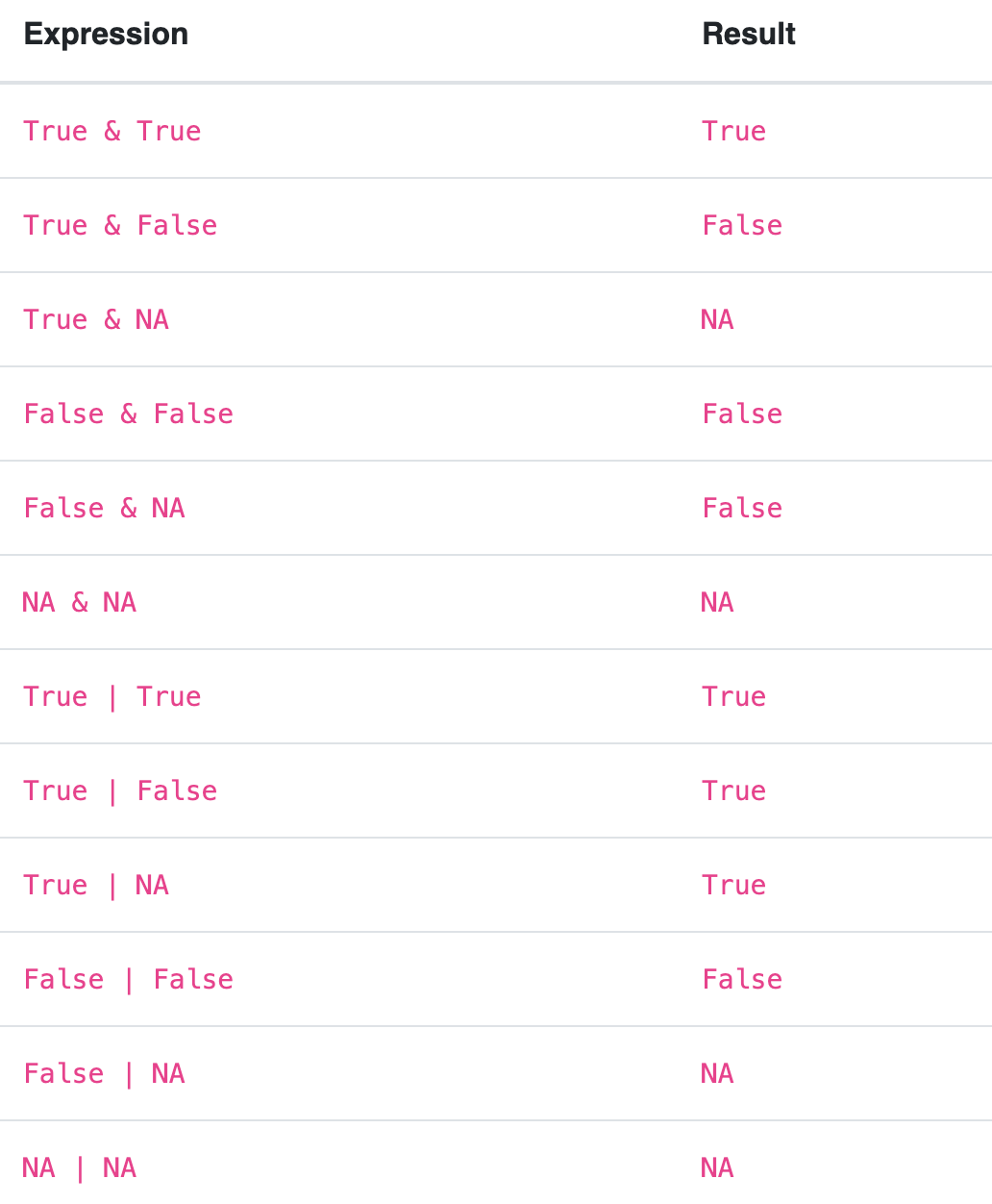
Для получения дополнительной информации см. документацию.
Посмотрим, как ведёт себя нововведение с различными типами данных
Пропущенные целочисленные
Если вы хотите использовать pd.NA и избежать типизации вашего int к float, в новой версии нужно специально указывать в качестве типа Int64. Обратите внимание на заглавную букву I. Этот dtype отличается от стандартного int64 в NumPy.
Вот старый способ создать DataFrame с целочисленным столбцом:
pd.DataFrame ([1, 2, np.nan]) Результат следующий:

Обратите внимание на автоматическое приведение типа к float.
Вот новый способ создать столбец, который может обрабатывать pd.NA:
pd.DataFrame([1, 2, np.nan], dtype="Int64") Просто указываем dtype = ”Int64" при создании Series или DataFrame, и получаем целочисленный столбец с пропусками. Обратите внимание на разницу:

Целые числа остались целыми, на месте пропуска новое отображение <NA>.
Столбцы с неизвестными булевыми значениями
Аналогично новый dtype введён и для логических значений, чтобы столбцы не приводились к типу object. Вместо стандартного bool используйте новый тип boolean:
pd.DataFrame([True, False, np.nan], dtype=”boolean”) Пропуски в столбце строковых значений
Как вы могли догадаться, тот же приём был предложен и для строковых типов, чтобы меньше людей испытывало проблемы с типом object:
pd.DataFrame(['a', 'b'], dtype='string') Прочие мелочи
- Документация теперь имеет более опрятный вид и содержит новый раздел по масштабированию для больших наборов данных.
- Команда Pandas будет использовать свободный вариант семантического управления версиями, совместимый API и другой подход к нумерации версий.
- DataFrame легко выводить в виде таблицы Markdown с помощью метода
to_markdown(). - Модуль
pandas.util.testingустарел. - Pandas 1.0.0 поддерживает Python 3.6.1 и выше.
Как установить версию?
python3.8 -m venv my_env source my_env/bin/activate 
Установка Pandas и Jupyter Lab на Conda:
conda create -n pandascfj -c conda-forge/label/rc -c conda-forge pandas==1.0.0rc0 jupyterlab Будьте осторожны ?. Не пытайтесь установить релиз-кандидат в обычной старой среде conda. Скорее всего, вы увидите множество конфликтов пакетов, приводящих к сбою установки. К тому времени, как 1.0.0 будет официально выпущен, мы надеемся, эти конфликты будут устранены.
Когда будет официальный релиз 1.0.0?
Скоро: 1 февраля 2020 года ?
Если вы хотите подождать релиза, вот другие наши публикации о Pandas:
- Анализируй данные с помощью одной строки на Python
- 10 трюков библиотеки Python Pandas, которые вам нужны
- 10 простых хаков, которые ускорят анализ данных Python
Источники
Телеграм: t.me/ainewsline
Источник: proglib.io