Обучение с учителем и обучение без учителя — это ещё не все. Все это знают. Начните с OpenAI Gym.

Есть способ, который позволит вам это сделать — обучение с подкреплением.
Что такое обучение с подкреплением?
Обучение с подкреплением — это обучение принятия последовательных решений в окружающей среде с максимальным полученным вознаграждением, которое даётся за каждое действие.
В нем нет учителя, только сигнал вознаграждения от окружающей среды. Время имеет значение, и действия влияют на последующие данные. Такие условия создают трудности для обучения как с учителем, так и без него.


Мышь — это агент. Лабиринт со стенами, сыром и электрошокерами — это окружающая среда. Мышь может двигаться влево, вправо, вверх, вниз — это действия.
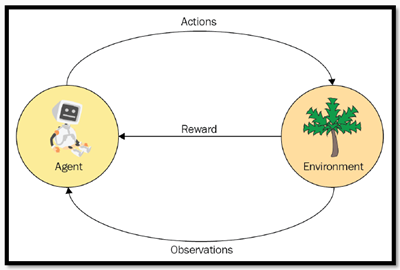
Обучение с подкреплением на льду
Давайте оставим мышь в лабиринте и перейдём на лёд. «Зима наступила. Вы и ваши друзья перекидывались фрисби в парке, когда вы вдруг закинули фрисби на середину озера. В основном вода в озере замёрзла, но осталось несколько дыр, где лёд растаял. (источник)

Как вам быть в подобной ситуации?
Это задача для обучения с подкреплением. Агент контролирует движения персонажа в мире-сетке. Некоторые плитки сетки проходимы, а другие приводят к тому, что персонаж падает в воду. Агент получает вознаграждение за нахождения проходимого пути к цели.
Мы можем смоделировать такое окружение используя OpenAI Gym — инструментарий для разработки и сравнения алгоритмов обучения с подкреплением. Он обеспечивает доступ к стандартизированному набору сред, таких как в нашем примере, которая называется «Frozen Lake» («Замершее Озеро). Это текстовая среда, которая может быть создана парой строк кода.
import gym from gym.envs.registration import register # load 4x4 environment if 'FrozenLakeNotSlippery-v0' in gym.envs.registry.env_specs: del gym.envs.registry.env_specs['FrozenLakeNotSlippery-v0'] register(id='FrozenLakeNotSlippery-v0', entry_point='gym.envs.toy_text:FrozenLakeEnv', kwargs={'map_name' : '4x4', 'is_slippery': False}, max_episode_steps=100, reward_threshold=0.8196 ) # load 16x16 environment if 'FrozenLake8x8NotSlippery-v0' in gym.envs.registry.env_specs: del gym.envs.registry.env_specs['FrozenLake8x8NotSlippery-v0'] register( id='FrozenLake8x8NotSlippery-v0', entry_point='gym.envs.toy_text:FrozenLakeEnv', kwargs={'map_name' : '8x8', 'is_slippery': False}, max_episode_steps=100, reward_threshold=0.8196 ) Теперь нам нужна структура, которая позволит нас систематически подходить к проблемам обучения с подкреплением.
Процесс принятия решений Маркова
В нашем примере, агент контролирует передвижение персонажа по миру-сетке, и это окружение называется полностью наблюдаемой средой.
Поскольку будущая плитка не зависит от прошлых плиток с учётом текущей плитки
( мы имеем дело с последовательностью случайных состояний, то есть со свойством Маркова ), поэтому мы имеем дело с так называемым Марковским процессом. Текущее состояние инкапсулирует все, что необходимо для решения, какой будет следующий ход, ничего запоминать не требуется. На каждой следующей клетке (то есть ситуации) агент выбирает с некоторой вероятностью действие, которое ведёт к следующей клетке, то есть ситуации, и окружение отвечает агенту наблюдением и наградой.
Добавим в процесс Маркова функцию вознаграждения и коэффициент скидки, и мы получим так называемый процесс вознаграждения Маркова. Добавив набор действий мы получим процесс принятия решений Маркова (MDP). Ниже более подробно рассказывается о компонентах MDP.
Состояние
Состояние — это часть окружающей среды, числовое представление того, что агент наблюдает в определённый момент времени в окружающий среде, состояние сетки озера. S — начальная точка, G — цель, F — твёрдый лёд, на котором агент может стоять, и H — дыра, в которое упадёт агент, если наступит на неё. У нас есть 16 состояний в среде сетки 4 на 4, или 64 состояния в среде 8 на 8. Ниже мы нарисуем пример среды 4 на 4 используя OpenAI Gym.
def view_states_frozen_lake(env = gym.make('FrozenLakeNotSlippery-v0')): print(env.observation_space) print() env.env.s=random.randint(0,env.observation_space.n-1) env.render() view_states_frozen_lake() Действия
У агента есть 4 возможных действия, которые представлены в окружении как 0, 1, 2 ,3 для лево, право, низ, верх соответственно.
def view_actions_frozen_lake(env = gym.make('FrozenLakeNotSlippery-v0')): print(env.action_space) print("Possible actions: [0..%a]" % (env.action_space.n-1)) view_actions_frozen_lake() Модель перехода состояний
Модель перехода состояний описывает, как меняется состояние окружающей среды, когда агент предпринимает действия, исходя из текущего своего состояния.
Модель обычно описывается вероятностью перехода, который выражается в виде квадратной переходной матрицы размером N х N, где N — это число состояний нашей модели. Иллюстрация ниже — это пример такой матрицы для погодных условий.
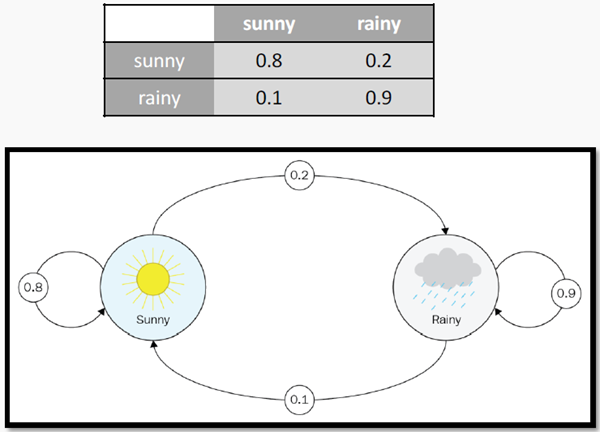
«Вверх» перемещает агента на 1 клетку вверх, или агент остаётся на том же месте, если он стоит у верхней границы.
«Вниз» перемещает агента на 1 клетку вниз, или он остаётся на том же месте, если он находится у нижней границы.
Вознаграждение
В каждом состоянии F агент получает 0 награды, в состоянии H он получает -1, так как перейдя в это состояние, агент умирает. И когда агент достигает цели, он получает +1 награду.
Из-за того что обе модели, переходная модель и модель награды, являются детерминированными функциями, это делает среду детерминированной.
Скидка
Скидка — это необязательный параметр, который контролирует важность будущих вознаграждений. Он измеряется в диапазоне от 0 до 1. Цель этого параметра — не допустить, чтобы общее вознаграждение не уходило в бесконечность.
Скидка также моделирует поведение агента, когда агент предпочитает немедленное вознаграждение вознаграждению, которое может быть получено в будущем.
Ценность
Ценность состояния — это ожидаемый долгосрочный доход со скидкой для состояния.
Политика(?)
Стратегия, которую агент использует для выбора следующего действия, называется политикой. Среди всех доступных политик оптимальной является та, которая максимизирует сумму вознаграждения, полученного или ожидаемого за время эпизода.
Эпизод
Эпизод начинается, когда агент появляется на стартовой клетке, и заканчивается, когда агент либо падает в дыру или достигает целевой клетки.
Давайте визуализируем все это
После рассмотрения всех концепций, участвующих в процессе принятия решений Маркова, мы теперь можем моделировать несколько случайных действий в среде 16x16 с использованием OpenAI Gym. Каждый раз агент выбирает случайное действие и выполняет его. Система вычисляет вознаграждение и отображает новое состояние окружающей среды.
def simulate_frozen_lake(env = gym.make('FrozenLakeNotSlippery-v0'), nb_trials=10): rew_tot=0 obs= env.reset() env.render() for _ in range(nb_trials+1): action = env.action_space.sample() # select a random action obs, rew, done, info = env.step(action) # perform the action rew_tot = rew_tot + rew # calculate the total reward env.render() # display the environment print("Reward: %r" % rew_tot) # print the total reward simulate_frozen_lake(env = gym.make('FrozenLake8x8NotSlippery-v0')) 
Заключение
В этой статье мы кратко разобрали основные концепции обучения с подкреплением. Наш пример дал представлении об OpenAI Gym toolkit, который позволяет легко экспериментировать с предварительно построенными средами.
В следующей части мы представим, как спроектировать и имплементировать политики, которые позволят агенту делать набор действий, чтобы обязательно достичь цели и получить награду, такую, как победить чемпиона мира.