Какие ошибки чаще всего совершают при обучении нейросетей
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2019-11-06 13:28

Исследователи из USI выделили основные проблемы, с которыми сталкиваются разработчики при обучении нейросетей. Выборка состояла из 1059 проблем и коммитов ML-репозиториев на GitHub, которые были вручную проанализированы. Чтобы валидировать выделенный список проблем, исследователи опросили 21 разработчика.
Возросший интерес к нейросетям делает анализ ошибок при их обучении актуальным полем для исследований. В своей статье исследователи привели таксономию ошибок, которые разработчики совершают в нейросетевых проектах. Исследователи вручную проанализировали репозитории ML-проектов на GitHub и классифицировали выделенные ошибки. Репозитории проектов отбирались по критерию использования одного из популярных DL-фреймворков: TensorFlow, Keras или PyTorch. Помимо этого, в качестве данных для анализа отбирались посты на StackOverflow. Затем были собраны 20 интервью ML-разработчиков, которые описывали опыт разработки нейросетей. Проанализированные данные исследователи агрегировали в карту ошибок. Чтобы провалидировать список ошибок, исследователи дополнительно опросили 21 разработчика. По результатам опроса, как 13 из 15 категорий ошибок встречались как минимум у половины опрошенных.
Классификация проблем
Выделенные проблемы объединились в общие темы: модель, тензоры/входные данные, обучение, API.
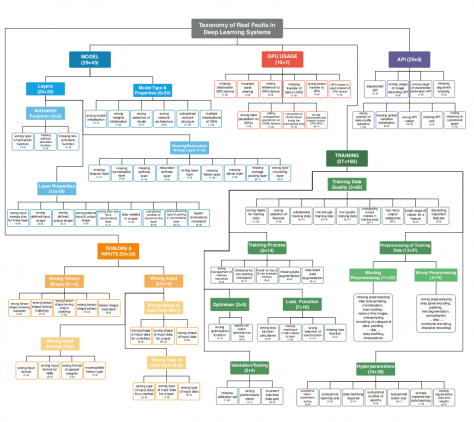
Валидация выделенных категорий
Чтобы проверить полноту списка ошибок, исследователи опросили 21 ML-разработчика. В опрос включили категории ошибок с описанием типов ошибок, которые они представляют. Участников опроса попросили отметить те категории ошибок, с которыми они сталкивались во время обучения нейросетевых моделей. Ни одна из категорий ошибок не осталась не отмеченной. Самая низкочастотная категория встречалась у 24% разработчиков.
Исследователи отмечают, что данные интервью помогли выделить две категории ошибок и 27 ошибок. Выделенные ошибки остались бы не учтенными, если бы исследователи опирались исключительно на данные GitHub.
Телеграм: t.me/ainewsline
Источник: neurohive.io