DialoGPT: в Microsoft GPT-2 обучили генерировать ответы в диалоге
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2019-11-12 17:16

DialoGPT — это диалоговая модель, которую обучили на 147 миллионах комментариев в Reddit. Нейросеть генерирует ответы на реплики пользователя (single-turn dialogue). DialoGPT базируется на GPT-2. Обучающая выборка состояла из цепочек комментариев на Reddit с 2005 по 2017. Предобученная модель и пайплайн обучения доступны в репозитории на GitHub.
Что внутри DialoGPT
Исследователи обучили нейросеть, которая основана на GPT-2. GPT-2 модель трансформера использует в основе стандартную архитектуру трансформера и набор скрытых multi-head self-attention слоев. На текущий момент GPT-2 модель — одна из state-of-the-art моделей в обработке естественного языка. Успех GPT-2 показывает, что трансформер языковая модель может выучивать распределения из естественного языка с высокой точностью. DialoGPT наследует у GPT-2 трансформер из 12 в 24 слоя с нормализацией слоев, схему инициализации и BPE.
Модель оптимизирует максимальную совместную информацию (MMI). MMI использует предобученную backward модель для предсказания предыдущих реплик по текущим ответам. Исследователи пробовали оптимизировать награду с помощью policy градиента. Однако этот метод быстро сходился к локальным оптимумам, где предсказание полностью повторяло предыдущие реплики.
Исследователи обучили 3 модели разного размера: с 117, 345 и 762 миллионами параметров. Детали конфигурации моделей можно изучить в таблице ниже.

Тестирование модели
Для проверки модели исследователи использовали 7-й трек соревнования DSTC (Dialog System Technology Challenges). Задача заключалась в моделировании ответов на реплики с использованием сторонней информации end-to-end. Данные тестового набора DSTC-7 содержат треды бесед из Reddit. В расчет принимались треды с как минимум 6 ответами.
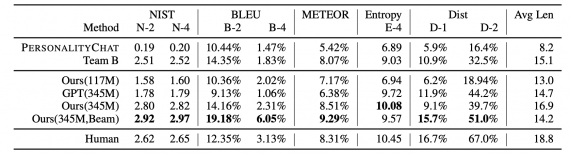
В качестве метрик использовались стандартные метрики для генерации текста: BLEU, METEOR, NIST, Entropy и Dist-n. Последние две метрики оценивают лексическое разнообразие предсказанных ответов.
Ниже можно видеть, что предложенная модель с 345 миллионом параметром и beam search обошла топ-1 модель соревнования (Team B) и внутреннюю диалоговую систему в Microsoft (PersonalityChat).
Телеграм: t.me/ainewsline
Источник: neurohive.io