DeepFake-туториал: создаем собственный дипфейк в DeepFaceLab
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2019-11-17 10:00

DeepFake – технология синтеза изображения, основанная на искусственном интеллекте и используемая для замены элементов изображения на желаемые образы. Если вы не слышали о дипфейках, посмотрите нижеприведенный видеоролик, в котором актер Джим Мескимен читает стихотворение «Пожалейте бедного пародиста» в двадцати лицах знаменитостей.
Название технологии – объединение терминов «глубокое обучение» (англ. Deep Learning) и «подделка» (англ. Fake). В большинстве случаев в основе метода лежат генеративно-состязательные нейросети (GAN). Одна часть алгоритма учится на фотографиях объекта и создает изображение, буквально «состязаясь» со второй частью алгоритма, пока та не начнет путать копию с оригиналом.
В следующем видео показаны процессы, происходящие за кулисами обучения нейросети. Как пишет автор проекта Sham00K, на итоговое видео было потрачено более 250 часов работы. При этом использовались 1200 часов съемочных материалов и 300 тыс. изображений. Объем сгенерированных данных составил приблизительно 1 Тб.
Области применения технологии
Уже имеются целые YouTube- и Reddit-каналы c дипфейк-роликами. Технология DeepFake может применяться для самых разных целей.
Кинопроизводство. Производство фильмов сегодня – крайне затратный процесс с арендой камер, студий и оплатой работы актеров. Развитие технологии DeepFake позволит сократить затраты на съемочный процесс, монтаж и спецэффекты.
Локализация рекламы. Достаточно записать один рекламный ролик со знаменитостью, после чего лицо знаменитости можно переносить в видео с местными актерами, произносящими рекламные слоганы на родном языке. Так можно добиться эффекта, как будто знаменитость говорит на языке страны дистрибуции продукта.
Виртуальная и дополненная реальности. Технология переноса мимики может применяться для создания цифровых двойников в играх и виртуальной (или дополненной) реальности. Источниками лица могут служить сами участники игры или иного пространства. Это повышает эмоциональное вовлечение в продукт.
Очевидно, что технология должна использоваться с особой осторожностью. Злоумышленниками могут преследоваться цели компрометирования личности или создания фейковых новостей. В начале октября 2019 года члены Комитета по разведке Сената США призвали крупные технологические компании разработать план для борьбы с дипфейками. Ранее, в сентябре этого года, Google создала специальный датасет дипфейков.
Отметим, что данная публикация подготовлена исключительно в исследовательских целях.
Создадим собственный DeepFake
Для синтеза дипфейка мы будем использовать популярную библиотеку DeepFaceLab (телеграм-канал для разработчиков). Ниже мы описали базовый процесс создания дипфейка. Важно понимать, что на качество результата влияет множество свойств исходных файлов (разрешение и длительность видеофайлов, разнообразность мимики персонажей, освещение и т. д.). За любыми подробностями и деталями настроек перенаправляем к оригинальному руководству.
Системные требования для DeepFaceLab
Минимальные системные требования для работы с инструментом:
- ОС Windows 7 или выше (64 бит).
- Процессор с поддержкой SSE-инструкций.
- Оперативная память объемом не менее 2 Гб + файл подкачки.
- OpenCL-совместимая видеокарта (NVIDIA, AMD, Intel HD Graphics).
Рекомендуемые системные требования:
- Процессор с поддержкой AVX-инструкций.
- Оперативная память объемом не менее 8 Гб.
- Видеокарта NVIDIA с объемом видеопамяти не менее 6 Гб.
Установка DeepFaceLab
Имеются три вида прекомпилированных сборок для ОС Windows:
DeepFaceLabCUDA9.2SSE– для видеокарт NVIDIA (вплоть до GTX1080) и любых 64-битных CPU.DeepFaceLabCUDA10.1AVX– для видеокарт NVIDIA (вплоть до RTX) и CPU с поддержкой AVX.DeepFaceLabOpenCLSSE– для видеокарт AMD/IntelHD и любых 64-битных CPU.
Файлы доступны на Google Drive и торрент-трекере (требуется VPN, форум трекера также пригодится в случае трудностей при установке и запуске). Размер сборок – порядка 1 Гб. На Google Drive также хранятся оформленные подборки лиц для теста.
Алгоритм работы с DeepFaceLab
Предварительно договоримся о терминологии:
src(сокр. от англ. source) – лицо, которое будет использоваться для замены,dst(сокр. от англ. destination) – лицо, которое будет заменяться.
Архив сборки нужно распаковать как можно ближе к корню системного диска. После распаковки в каталоге DeepFaceLab вы найдете множество bat-файлов.
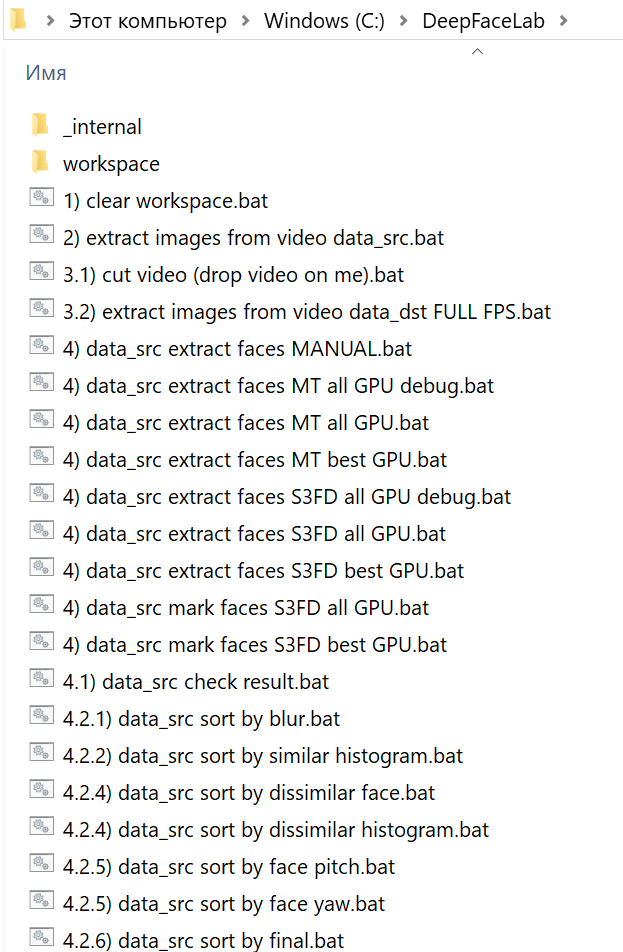
Местом хранения модели служит директория workspace. В ней будут содержаться видео, фотографии и файлы самой программы. Вы можете переименовывать каталог для сохранения резервных копий.
Как вы могли заметить, bat-файлы имеют в начале имени номер. Каждый номер соответствует определенному шагу выполнения алгоритма. Некоторые пункты опциональны. Пройдемся по этой последовательности.
1. Очистка рабочего каталога
На первом шаге запуском 1) clear workspace.bat и нажатием пробела очищаем лишнее содержимое папки workspace. Одновременно создаются необходимые директории.
Сразу после распаковки в workspace уже содержатся примеры видеороликов для теста. В соответствии с описанной терминологией вы можете заменить их видеофайлами с теми же названиями data_src и data_dst. Максимально поддерживаемое разрешение – 1080p. Приведенные в документации примеры расширений файлов: mp4, avi, mkv.
2. Извлечение кадров из видеофайла источника
На втором шаге извлекаем изображения из src-файла (2) extract images from video data_src.bat). Для этого запускаем bat-файл, получаем приглашение для указания кадровой частоты:
Enter FPS ( ?:help skip:fullfps ) : Пропускаем пункт, нажав Enter, чтобы извлечь все кадры.
Output image format? ( jpg png ?:help skip:png ) : ? В формат png файлы извлекаются без потерь качества, но на порядок медленнее и с большим объемом, чем в jpg. После задания настроек кадры извлекаются в каталог data_src.
3. Извлечение кадров сцены для переноса лица
При необходимости обрезаем видео с помощью 3.1) cut video (drop video on me).bat. Перетаскиваем файл data_dst поверх bat-файла. Указываем временные метки, номер дорожки (если их несколько), битрейт выходного файла. Появляется дополнительный файл с суффиксом _cut.
Запускаем 3.2) extract images from video data_dst FULL FPS.bat для извлечения кадров dst-сцены.
4. Составление выборки лиц источника
Теперь необходимо детектировать лица на src-кадрах. Получаемая выборка будет храниться по адресу workspacedata_srcaligned. Этому пункту соответствует множество bat-файлов, начинающихся с 4) data_src extract faces и имеющих разные дополнения после:
- Тип детектора лица:
MT– чуть более быстрый, но производит больше ложных лиц илиS3FD– рекомендованный, более точный, меньше ложных лиц. - Вариант использования GPU:
ALL(задействовать все видеокарты),Best(использовать лучшую). Выбирайте второй вариант, если у вас есть и внешняя, и встроенная видеокарты, и вам нужно параллельно работать в офисных приложениях. - Запись работы детекторов (
DEBUG). Каждый кадр с выделенными контурами лиц записывается по адресуworkspacedata_srcaligned_debug.
Пример вывода программы при запуске на видеокарте NVIDIA GeForce 940MX:
Performing 1st pass... Running on GeForce 940MX. Recommended to close all programs using this device. Using TensorFlow backend. 100%|################################################################################| 655/655 [03:32<00:00, 3.08it/s] Performing 2nd pass... Running on GeForce 940MX. Recommended to close all programs using this device. Using TensorFlow backend. 100%|##########################################################################################################################################################| 655/655 [13:28<00:00, 1.23s/it] Performing 3rd pass... Running on CPU0. Running on CPU1. Running on CPU2. Running on CPU3. Running on CPU4. Running on CPU5. Running on CPU6. Running on CPU7. 100%|#########################################################################################################################################################| 655/655 [00:05<00:00, 112.98it/s] ------------------------- Images found: 655 Faces detected: 654 ------------------------- Done. Bat-файл с параметром MANUAL применяется для ручного переизвлечения уже извлеченных лиц в случае ошибок на этапе 4.2.other) data_src util add landmarks debug images.bat.
4.1. Удаляем большие группы некорректных кадров
Запускаем 4.1) data_src check result.bat, просматриваем результаты в обозревателе XnView MP (при закрытии запускайте этот bat-файл).
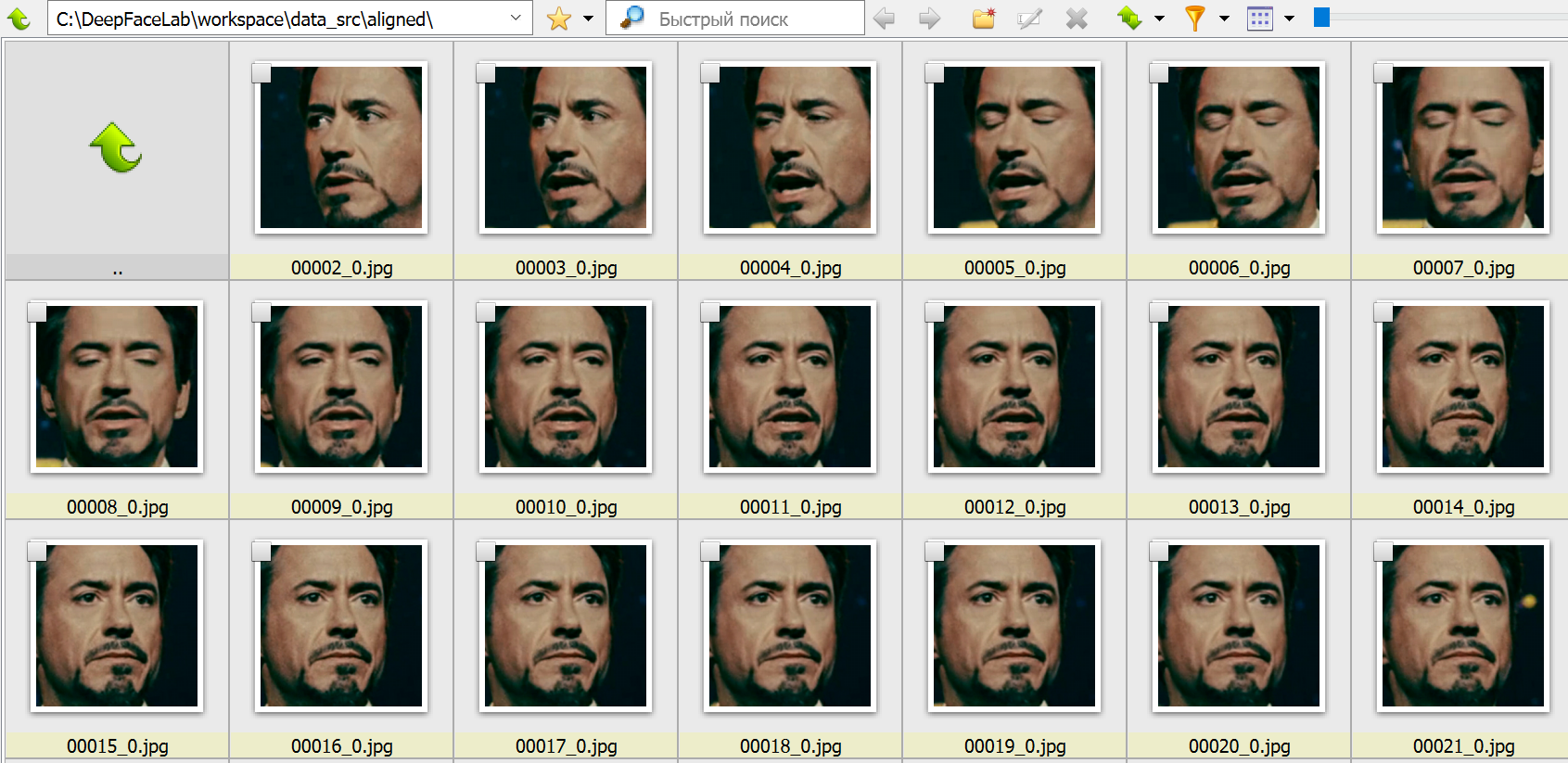
На этом этапе необходимо удалить большие группы некорректных кадров, чтобы далее не тратить на них вычислительный ресурс. К некорректным кадрам относятся все те, что не содержат четко различимого лица. Лицо также не должно быть закрыто предметом, волосами и пр. Не тратьте время на мелкие группы. Они будут удалены на следующем шаге.
4.2. Сортировка и удаление прочих некорректных кадров
Файлы с именами, начинающимися с 4.2, служат для сортировки и выявления групп некорректных кадров. Не закрывая обозреватель, последовательно запускайте bat-файлы и удаляйте группы некорректных кадров (обычно находятся в конце).
4.2.1) data_src sort by blur.batсортирует кадры по резкости, удаляем кадры с нечеткими лицами.4.2.2) data_src sort by similar histogram.batгруппирует кадры по содержанию, позволяет удалять ненужные лица группами.4.2.4) data_src sort by dissimilar histogram.batоставляет ближе к концу списка те изображения, у которых больше всего схожих (обычно это лица анфас). По усмотрению можно удалить часть конца списка, чтобы не проводить обучение на идентичных лицах.- Опционально:
4.2.5) data_src sort by face pitch.batсортирует лица так, чтобы в начале списка лицо смотрело вниз, а в конце – вверх. - Опционально:
4.2.5) data_src sort by face yaw.batсортирует лица по взгляду слева направо. - Рекомендованный пункт:
4.2.6) data_src sort by final.batделает финальную выборку целевого количества (по умолчанию 2000). Применяйте только после очистки набора предыдущими инструментами.
Дополнительные сортировочные bat-файлы, названия которых начинаются с 4.2.other, сортируют изображения по количеству черных пикселей, числу лиц в кадре (нужны кадры только с одним лицом) и т. д.
5. Составление выборки лиц принимающей сцены
Следующие операции с некоторыми отличиями идентичны выборке лиц источника. Главным отличием является то, что для принимающей сцены важно определить dst-лица во всех кадрах, содержащих лицо, даже мутные. Иначе в этих кадрах не будет произведено замены на источник.
Опция +manual fix позволяет вручную указать контуры лица на кадрах, где лицо не было определено. При этом в конце извлечения файлов открыто окно ручного исправления контуров. Элементы управления описаны вверху окна (вызываются клавишей H).

Запуск 5.1) data_dst check results debug.bat позволяет посмотреть все dst-кадры c наложенными поверх них предсказанными контурами лица. Удалите лица прочих, неосновных персонажей.
6. Тренировка
Обучение нейросети – самая времязатратная часть, длящаяся часы и сутки. Для тренировки необходимо выбрать одну из моделей. Выбор и качество результата определяются объемом памяти видеокарты:
- ? 512 Мб ?
SAE. Наиболее гибкая модель с возможностью переносить стиль лица и освещение. - ? 2 Гб ?
H64. Наименее требовательная модель. - ? 3 Гб ?
H128. Аналогична моделиH64, но с лучшим разрешением. - ? 5 Гб ?
DF– умная тренировка лиц, исключающая фон вокруг лица, илиLIAEF128– модель аналогичнаDF, но пытается морфировать исходное лицо в целевое, сохраняя черты исходного лица. - ? 6 Гб ?
AVATAR– модель для управления чужим лицом, требуются квадратные видеоролики илиSAE HD– для самых последних видеокарт.
В руководстве не описана еще одна модель, присутствующая в наборе (Quick96), но она успешно запустилась при тренировке на видеокарте с 2 Гб памяти.
При первом запуске программа попросит указать параметры, применяемые при последующих запусках (при нажатии Enter используются значения по умолчанию). Большинство параметров понятно интуитивно, прочие – описаны в руководстве.
Отключите любые программы, использующие видеопамять. Если в процессе тренировки в консоли было выведено много текста, содержащего слова Memory Error, Allocation или OOM, то на вашем GPU модель не запустилась, и ее нужно урезать. Необходимо скорректировать опции моделей.
При корректных условиях параллельно с консолью откроется окно Training preview, в котором будет отображаться процесс обучения и кривая ошибки. Снижение кривой отражает прогресс тренировки. Кнопка p (английская раскладка) обновляет предпросмотр.
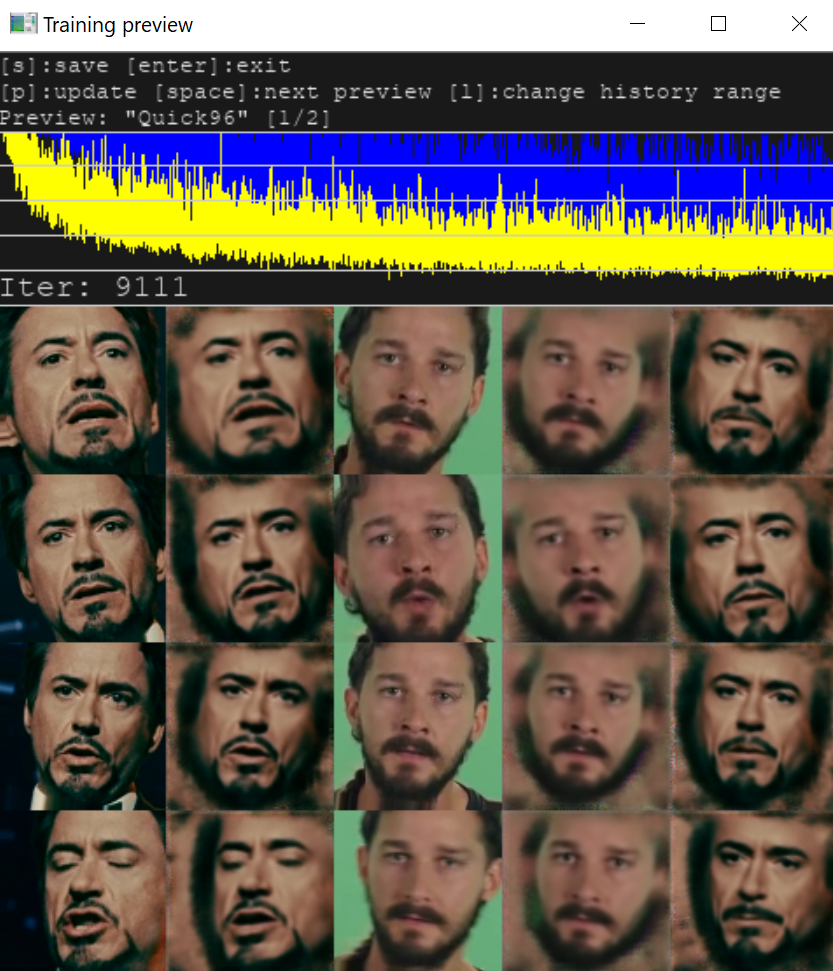
Процесс тренировки можно прерывать, нажимая Enter в окне Training preview, и запускать в любое время, модель будет продолжать обучаться с той же точки. Чем дольше длится тренировка, тем лучший результат мы получим.
7. Наложение лиц
Теперь у нас есть результат обучения. Необходимо совместить src-лица и кадры dst-сцены. Из списка bat-файлов выбираем ту модель, на которой происходила тренировка. Возможно несколько режимов наложения, по умолчанию используется метод Пуассона. В качестве остальных параметров для первой пробы можно использовать параметры по умолчанию (по нажатию Enter) и варьировать их, если вас не устроит результат наложения.
8. Склейка в видео
Следующие bat-файлы склеивают картинки в видео с той же частотой кадров и звуком, что и data_dst (поэтому файл должен оставаться в папке workspace). Итоговый файл будет сохранен под именем result. Готово! Ниже представлен пример, полученный для тестовых видео.
Если результат вас не удовлетворил, попробуйте разные опции наложения, либо продолжите тренировку для повышения четкости, используйте другую модель, другое видео с исходным лицом. О неописанных особенностях работы с библиотекой, прочих советах и хитростях читайте в оригинальном руководстве.
Телеграм: t.me/ainewsline
Источник: proglib.io