Ранее мы с вами уже пробовали решить простейшую задачу предсказания с помощью линейной регрессии в экосистеме .NET. Для этого мы использовали Accord.NET Framework. Для этих целей из открытых данных по обращениям граждан в органы исполнительной власти и лично в адрес мэра г. Москвы, был подготовлен небольшой набор данных. Спустя пару лет на обновлённом наборе данных мы попробуем решить простейшую задачу. Используя модель регрессии в Ml.NET Framework предскажем сколько запросов в месяц получает положительное решение. Попутно мы сравним Ml.NET с Accord. NET и библиотеками на Python.
Хотите овладеть силой и могуществом предсказателя? Тогда милости прошу под кат.

Содержание:
Часть I: введение и немного о данных Часть II: пишем код на C# Часть III: заключение
Думаю, необходимо сразу предупредить вас, что я отнюдь не профи в анализе данных и программировании в целом, также я не ангажирован с мэрией Москвы. Поэтому статья скорее от новичка – новичкам. Но несмотря на мои ограниченные знания, надеюсь статья будет вам полезна.
Люди, которые уже знакомы с прошлыми статьи из цикла, могут вспомнить, что мы уже пытались решить задачу предсказания количества положительно решенных вопросов из обращений граждан, поступивших в адрес исполнительной власти Москвы. Для этого мы использовали Python и Accord.Net Framework.
Другие статьи цикла
2. Практикуем первые навыки
В любом случае, не лишним будет еще раз разобрать используемый набор данных. 1. Учим азы:
- «Ловись Data большая и маленькая!» — (Краткий обзор курсов по Data Science от Cognitive Class)
- «Теперь он и тебя сосчитал» или Наука о данных с нуля (Data Science from Scratch)
- «Айсберг вместо Оскара!» или как я пробовал освоить азы DataScience на kaggle
- «Паровозик, который смог!» или «Специализация Машинное обучение и анализ данных», глазами новичка в Data Science
- Как ставить сети на начинающих аналитиков» или обзор на онлайн курс «Старт в Data Science»
2. Практикуем первые навыки
- “Восстание МашинLearning” или совмещаем хобби по Data Science и анализу спектров лампочек
- «Как по нотам!» или Машинное обучение (Data science) на C# с помощью Accord.NET Framework
- «Используй Силу машинного обучения, Люк!» или автоматическая классификация светильников по КСС
- «4 свадьбы и одни похороны» или линейная регрессия для анализа открытых данных правительства Москвы
- «Письмо турецкому султану» или линейная регрессия на C# с помощью Accord.NET для анализа открытых данных Москвы
Все материалы статьи включая код и и набор данных размещены в свободном доступе на GitHub.
Данные на GitHub представлены в формате csv, содержат 44 записи и в принципе их можно (и нужно) использовать не только для анализа приведенного в примере. Столбцы данных означают следующее:
- num – Индекс записи
- year – год записи
- month – месяц записи
- total_appeals – общее количество обращений за месяц
- appeals_to_mayor – общее количество обращений в адрес Мэра
- res_positive- количество положительных решений
- res_explained – количество обращений на которые дали разъяснения
- res_negative – количество обращений с отрицательным решением
- El_form_to_mayor – количество обращений к Мэру в электронной форме
- Pap_form_to_mayor — количество обращений к Мэру на бумажных носителях to_10K_total_VAO…to_10K_total_YUZAO – количество обращений на 10000 населения в различных округах Москвы
- to_10K_mayor_VAO… to_10K_mayor_YUZAO– количество обращений в адрес Мэра и правительства Москвы на 10000 населения в различных округах города
Я не нашел способа автоматизировать процесс сбора данных и собирал их вручную, поэтому мог слегка ошибиться. В остальном достоверность данных оставлю на совести авторов.
На текущий момент на сайте правительства Москвы в полном виде данные представлены с Января 2016 года по Август 2019 года (в Сентябре не хватает некоторых данных). Таким образом, у нас будет 44 записи. Немного, конечно, но для демонстрации нам этого будет достаточно.
Прежде чем начать, буквально пару слов о герое нашей статьи.
ML.NET Framework – разработка Microsoft с открытым исходным кодом. Если верить рекламе в соцсетях, то это их ответ библиотекам по машинному обучению на Python. Фреймворк кроссплафторменный и позволяет решать широкий круг задач от простейшей регрессиии и классифкации, до глубокого обучения. На Хабре товарищи уже проводили анализ ML.NET и библиотек на Python. Кому интересно, вот ссылка. Я не буду давать подробное руководство по установке и применению Ml.NET потому, что по сути все
Но небольшие пояснения думаю лишними не будут.
Я использовал Visual Studio 2017 с последними обновлениями.
Проект был на базе шаблона консольного приложения .NET Core (версии 2.1).
В проект пришлось установить NuGet пакеты Microsoft.ML, Microsoft.ML.FastTree. Вот, собственно, и вся подготовка.
Перейдем непосредственно к коду.
Для начала я создал класс MayorAppel, в котором описал по порядку колонки с данными из csv файлов.
Как не трудно догадаться [LoadColumn(0)]
— говорит нам какую колонку из csv файла мы берем.
Далее, следуя руководству, я создал класса MayorAppelPrediction – для результатов предсказания
Несмотря на то, что почти все столбцы в наборе данных имеют целочисленные значения, во избежание ошибки на этапе склейки данных в pipeline, мне пришлось назначить им тип float (чтобы все типы данных были одинаковыми).
Листинг достаточно большой, поэтому поместим его под спойлер.
Код класса для описания данных
Перейдем к основному коду программы. Не забудьте добавить в самом начале:using Microsoft.ML.Data; namespace app_to_mayor_mlnet { class MayorAppel { [LoadColumn(0)] public float Year; [LoadColumn(1)] public string Month; [LoadColumn(2)] public float TotalAppeals; [LoadColumn(3)] public float AppealsToMayor; [LoadColumn(4)] public float ResPositive; [LoadColumn(5)] public float ResExplained; [LoadColumn(6)] public float ResNegative; [LoadColumn(7)] public float ElFormToMayor; [LoadColumn(8)] public float PapFormToMayor; [LoadColumn(9)] public float To10KTotalVAO; [LoadColumn(10)] public float To10KMayorVAO; [LoadColumn(11)] public float To10KTotalZAO; [LoadColumn(12)] public float To10KMayorZAO; [LoadColumn(13)] public float To10KTotalZelAO; [LoadColumn(14)] public float To10KMayorZelAO; [LoadColumn(6)] public float To10KTotalSAO; [LoadColumn(15)] public float To10KMayorSAO; [LoadColumn(16)] public float To10KTotalSVAO; [LoadColumn(17)] public float To10KMayorSVAO; [LoadColumn(18)] public float To10KTotalSZAO; [LoadColumn(19)] public float To10KMayorSZAO; [LoadColumn(20)] public float To10KTotalTiNAO; [LoadColumn(21)] public float To10KMayorTiNAO; [LoadColumn(22)] public float To10KTotalCAO; [LoadColumn(23)] public float To10KMayorCAO; [LoadColumn(24)] public float To10KTotalYUAO; [LoadColumn(25)] public float To10KMayorYUAO; [LoadColumn(26)] public float To10KTotalYUVAO; [LoadColumn(27)] public float To10KMayorYUVAO; [LoadColumn(28)] public float To10KTotalYUZAO; [LoadColumn(29)] public float To10KMayorYUZAO; } public class MayorAppelPrediction { [ColumnName("Score")] public float ResPositive; } }using System.IO; using Microsoft.ML;Далее описание полей данных.
namespace app_to_mayor_mlnet { class Program { static readonly string _trainDataPath = Path.Combine(Environment.CurrentDirectory, "Data", "train_data.csv"); static readonly string _testDataPath = Path.Combine(Environment.CurrentDirectory, "Data", "test_data.csv"); static readonly string _modelPath = Path.Combine(Environment.CurrentDirectory, "Data", "Model.zip");В данных полях по сути хранятся пути к файлам с данными, в этот раз я решил разделить их заранее (в отличие от случая с Accord.NET)
Кстати, если будете делать свой проект, не забудьте в свойствах файлов данных поставить параметр «Копировать более позднюю версию», чтобы избежать ошибки из-за отсутствия файлов сборке.
Далее идет вызов методов, которые формируют модель, проводят ее оценку и дают нам предсказание.
static void Main(string[] args) { MLContext mlContext = new MLContext(seed: 0); var model = Train(mlContext, _trainDataPath); Evaluate(mlContext, model); TestSinglePrediction(mlContext, model); }Пойдем по порядку
Метод Train нужен для обучения модели.
public static ITransformer Train(MLContext mlContext, string dataPath) { IDataView dataView = mlContext.Data.LoadFromTextFile<MayorAppel>(dataPath, hasHeader: true, separatorChar: ','); var pipeline = mlContext.Transforms.CopyColumns(outputColumnName: "Label", inputColumnName: "ResPositive") .Append(mlContext.Transforms.Categorical.OneHotEncoding(outputColumnName: "MonthEncoded", inputColumnName: "Month")) .Append(mlContext.Transforms.Concatenate("Features", "Year", "MonthEncoded", "TotalAppeals", "AppealsToMayor", "ResExplained", "ResNegative", "ElFormToMayor", "PapFormToMayor", "To10KTotalVAO", "To10KMayorVAO", "To10KTotalZAO", "To10KMayorZAO", "To10KTotalZelAO", "To10KMayorZelAO", "To10KTotalSAO", "To10KMayorSAO" , "To10KTotalSVAO", "To10KMayorSVAO", "To10KTotalSZAO", "To10KMayorSZAO", "To10KTotalTiNAO", "To10KMayorTiNAO" , "To10KTotalCAO", "To10KMayorCAO", "To10KTotalYUAO", "To10KMayorYUAO", "To10KTotalYUVAO", "To10KMayorYUVAO" , "To10KTotalYUZAO", "To10KMayorYUZAO")).Append(mlContext.Regression.Trainers.FastTree()); var model = pipeline.Fit(dataView); return model; }В начале мы читаем данные из тренировочной выборки. Затем в цепочке определяем параметр, который будет предсказывать (label).
В нашем случае это количество успешно решенных вопросов по обращениям граждан за месяц.
Поскольку в данном случае используется модель бустинга решающих деревьев, основанных на регрессии, нам надо все признаки привести к числовым значениям.
В отличие от случая с Accord.NET тут в документации сразу представлено готовое решение OneHotEncoding.
После остается сформировать колонки, как я уже говорил выше все они должны быть одного типа данных, в данном случае float.
В завершение формируем и возвращаем готовую модель.
Далее проводим оценку качества предсказания нашей моделью.
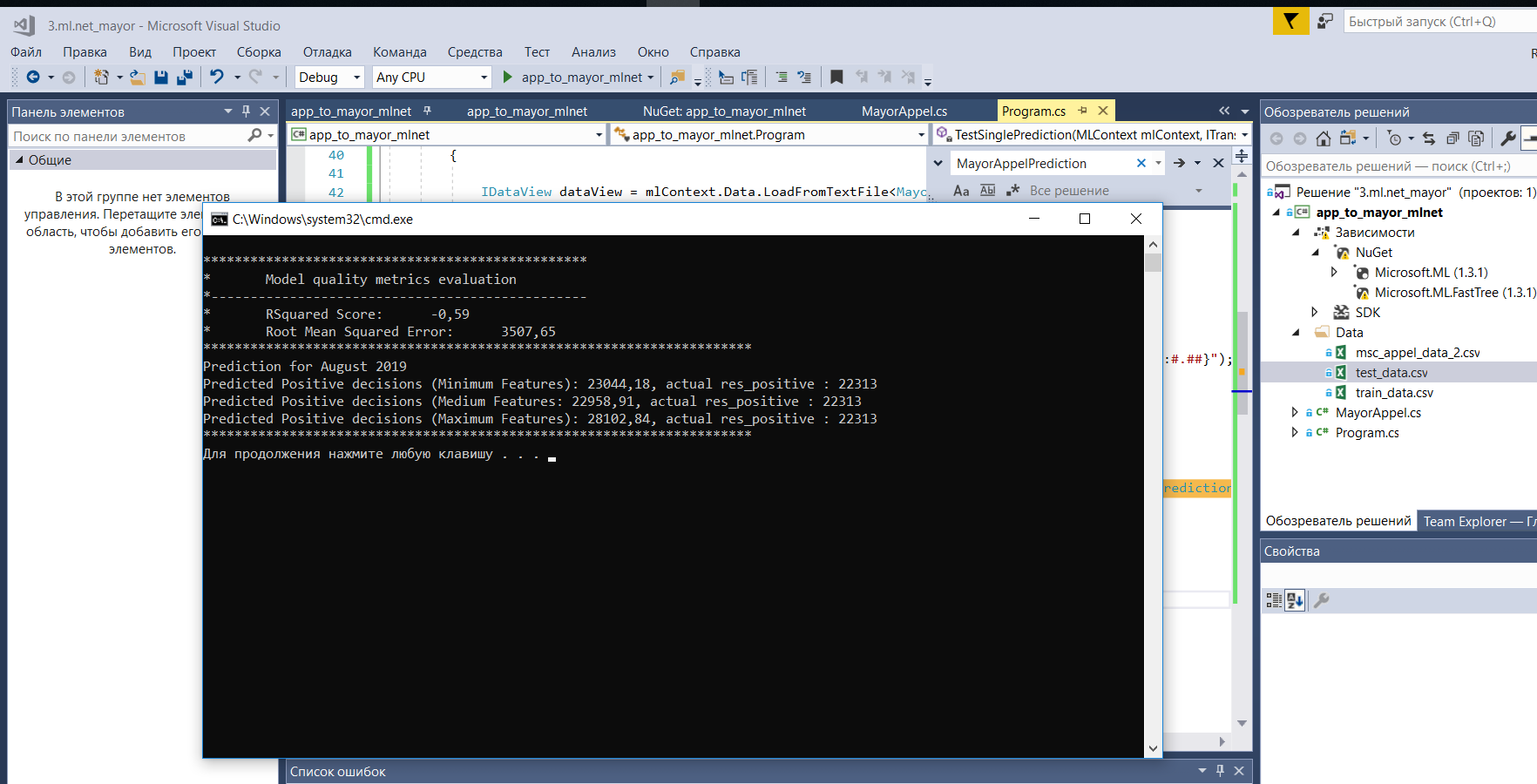
private static void Evaluate(MLContext mlContext, ITransformer model) { IDataView dataView = mlContext.Data.LoadFromTextFile<MayorAppel>(_testDataPath, hasHeader: true, separatorChar: ','); var predictions = model.Transform(dataView); var metrics = mlContext.Regression.Evaluate(predictions, "Label", "Score"); Console.WriteLine(); Console.WriteLine($"*************************************************"); Console.WriteLine($"* Model quality metrics evaluation "); Console.WriteLine($"*------------------------------------------------"); Console.WriteLine($"* RSquared Score: {metrics.RSquared:0.##}"); Console.WriteLine($"* Root Mean Squared Error: {metrics.RootMeanSquaredError:#.##}"); }Загружаем нашу тестовую выборку (последние 4 месяца из набора), получаем предсказание наших тестовых данных на обученной модели с помощью метода Transform(). После чего рассчитываем метрики и выводим их на печать. В данном случае это коэффициент детерминации и среднеквадратичное отклонение. Первый в идеале должен стремиться к 1, а второй по сути к нулю.
В принципе для того, чтобы сделать предсказание нам этот метод был не нужен, но приятно понимать, на сколько плохо наша модель что-то предсказывает.
Остался последний метод – собственно предсказание.
Его мы тоже спрячем под спойлер.
метод и данные для предсказания
В примере использовали класс PredictionEngine, который позволяет получить единичное предсказании на основании обученной модели и тестового набора данных.private static void TestSinglePrediction(MLContext mlContext, ITransformer model) { var predictionFunction = mlContext.Model.CreatePredictionEngine<MayorAppel, MayorAppelPrediction>(model); var MayorAppelSampleMinData = new MayorAppel() { Year = 2019, Month = "August", ResPositive = 0 }; var MayorAppelSampleMediumData = new MayorAppel() { Year = 2019, Month = "August", TotalAppeals = 111340, AppealsToMayor = 17932, ResExplained = 66858, ResNegative = 8945, ElFormToMayor = 14931, PapFormToMayor = 2967, ResPositive = 0 }; var MayorAppelSampleMaxData = new MayorAppel() { Year = 2019, Month = "August", TotalAppeals = 111340, AppealsToMayor = 17932, ResExplained = 66858, ResNegative = 8945, ElFormToMayor = 14931, PapFormToMayor = 2967, To10KTotalVAO = 67, To10KMayorVAO = 13, To10KTotalZAO = 57, To10KMayorZAO = 13, To10KTotalZelAO = 49, To10KMayorZelAO = 9, To10KTotalSAO = 71, To10KMayorSAO = 14, To10KTotalSVAO = 86, To10KMayorSVAO = 27, To10KTotalSZAO = 68, To10KMayorSZAO = 12, To10KTotalTiNAO = 93, To10KMayorTiNAO = 36, To10KTotalCAO = 104, To10KMayorCAO = 24, To10KTotalYUAO = 56, To10KMayorYUAO = 12, To10KTotalYUVAO = 59, To10KMayorYUVAO = 13, To10KTotalYUZAO = 78, To10KMayorYUZAO = 23, ResPositive = 0 }; var predictionMin = predictionFunction.Predict(MayorAppelSampleMinData); var predictionMed = predictionFunction.Predict(MayorAppelSampleMediumData); var predictionMax = predictionFunction.Predict(MayorAppelSampleMaxData); Console.WriteLine($"**********************************************************************"); Console.WriteLine($"Prediction for August 2019"); Console.WriteLine($"Predicted Positive decisions (Minimum Features): {predictionMin.ResPositive:0.####}, actual res_positive : 22313"); Console.WriteLine($"Predicted Positive decisions (Medium Features: {predictionMed.ResPositive:0.####}, actual res_positive : 22313"); Console.WriteLine($"Predicted Positive decisions (Maximum Features): {predictionMax.ResPositive:0.####}, actual res_positive : 22313"); Console.WriteLine($"**********************************************************************"); }Мы создадим три «пробника» с данными для предсказания.
Первый с минимальным набором данных (только месяц и год), второй со средним и третий с полным набором признаков – соответственно.
Получим три разных предсказания и распечатаем их.
Как видно на снимке экрана (Windows 10 x64) добавление данных по количеству обращений на 10000 жителей в округах, в данном случае, только все портит, а вот добавление остальных данных дает небольшую прибавку к точности предсказания.
1. Чувствуется, что разработчики стараются соответствовать трендам в области машинного обучения. Конечно, на Python с кучей библиотек установленных в Anaconda данную задачу можно было решить компактнее и потратить меньше времени на разработку. Но в целом, мне кажется, подход к решению задач у ML.NET дружелюбен к людям, привыкшим решать задачи машинного обучения с помощью Python.
2. По сравнению с Acord.NET Framework – ML.NET выглядит более удобным и перспективным, для человека, попробовавшего машинное обучение на Python. Помню, когда я два года назад пытался, что-то написать на Acord.NET, мне жутко не хватало пояснений и примеров к некоторым классам и методам. В этом плане у Ml.NET с документацией дела обстоят несколько лучше, притом, что фреймворк сильно моложе чем Accord.NET. Также не маловажными факторами является, то что ML.NET судя по активности на GitHub развивается куда интенсивнее чем Accord.NET и имеет больше рускоязычных учебных материалов.
В итоге на первый взгляд ML.NET выглядит, как удобный инструмент, дополняющий ваш арсенал в случае если нет возможности прииенить Python или R (например, при работе с API САПР, выполненным на .NET).
Всем хорошей трудовой недели!