Spiral++: RL-агента обучили рисовать лица людей
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2019-10-09 22:19

Spiral++ — это генеративный алгоритм, который моделирует процесс рисования объектов. RL-агенты в Spiral++ используются как генеративные модели изображений.
Агент работает в среде, которая симулирует холст. Дискриминатор контролирует реалистичность сгенерированных изображений и выдает награду агенту. У Spiral++ есть две опции — реконструкция входного снимка и свободное рисование.
Модель также способна рисовать абстрактные изображения и масштабируется на реалистичные. Spiral++ выучивает разные стили рисования под воздействием внешних факторов. Когда агенты ограничиваются в возможных действиях, агенты начинают генерировать абстрактные изображения, несмотря на то, что обучались на реальных снимках. В то время как большее время обучения результирует в повышение реалистичности генерируемых изображений.
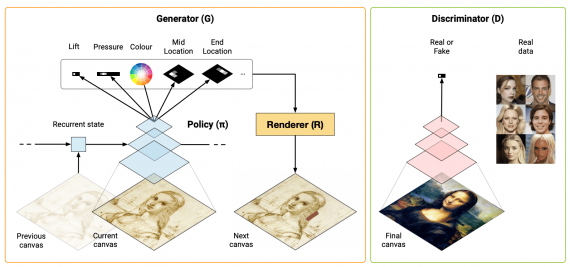
Архитектура модели
Цель SPIRAL — обучить policy, которая контролирует симулятор для рендеринга с помощью состязательного обучения. На каждом шаге policy принимает текущее состояние рисунка и выдает команду для симулятора с действием для обновления рисунка. Каждая команда содержит в себе характеристики мазка: форма, цвет, яркость и подобное. В SPIRAL обучающий сигнал для policy приходит в формате награды. Размер награды рассчитывается дискриминатором, который сравнивает сгенерированные рисунками с реальными снимками. В итоге модель выдает policy, которая генерирует последовательность команд с мазками для холста, чтобы отрисовать объект максимально реалистично.
В SPIRAL два обучаемых компонента:
- Policy нейросеть или агент, которая принимает на вход частично заполненный холст и выдает параметры действия для агента;
- Нейросеть-дискриминатор, которая принимает на вход итог policy и классифицирует его как сгенерированный или реальный
Проверка качества модели
Исследователи качественным методом сравнили сгенерированные моделью изображения. Ниже видно, как модель обучилась рисовать абстрактные изображения лиц за 32 обучающих шага.

Телеграм: t.me/ainewsline
Источник: neurohive.io