
Создаём семантический поисковик с машинным обучением в реальном времени за 300 строк Python кода.
Мой опыт подсказывает, что любой более или менее сложный проект по машинному обучению рано или поздно превращается в набор сложных неподдерживаемых внутренних инструментов. Эти инструменты, как правило, мешанина из скриптов Jupyter Notebooks и Flask, которые сложно развёртывать и интегрировать с решениями типа GPU сессий Tensorflow.
Впервые я столкнулся с этим в университете Карнеги, затем в Беркли, в Google X, и, наконец, при создании автономных роботов в Zoox. Зарождались инструменты в виде небольших Jupyter notebooks: утилита калибровки сенсора, сервис моделирования, приложение LIDAR, утилита для сценариев и т.д.
С ростом важности инструментов появлялись менеджеры. Бюрократия росла. Требования повышались. Маленькие проекты превращались в огромные неуклюжие кошмары.

Когда инструмент становился критически важным, мы привлекали команду для создания инструментов. Они использовали Vue и React. Их ноутбуки были покрыты стикерами с конференций по декларативным фреймворкам. У них был свой отлаженный процесс:

Процесс был замечательным. Вот только инструменты появлялись каждую неделю. А команда по созданию инструментов поддерживала ещё десять других проектов. Добавление новой функциональности занимало месяцы.
Так что мы возвращались к созданию своих инструментов, деплою приложений на Flask, написанию HTML, CSS и JavaScript, и попыткам перенести всё это из Jupyter с сохранением стилей. Так мой старый друг по Google X Тхиаго Теиxеира и я начали размышлять над вопросом: Что если бы мы могли создавать инструменты так же легко, как пишем скрипты на Python?
Мы хотели, чтобы специалисты по машинному обучению могли делать элегантные приложения без привлечения команд для создания инструментов. Внутренние инструменты должны быть не самоцелью, а побочным результатом работы с ML. Написание утилиты должно чувствоваться частью работы по обучению нейросети или проведению анализа в Jupyter! Но в то же время мы хотели иметь гибкость и мощь веб фреймворка. Фактически, мы хотели чего-то такого:

С помощью отличного сообщества инженеров из Uber, Twitter, Stitch Fix и Dropbox мы за год разработали Streamlit — бесплатный опенсорсный фреймворк в помощь работающим с машинным обучением. С каждой следующей итерацией принципы в основе Streamlit становились всё проще. Вот к чему мы пришли:
#1: Используйте знания Python. Приложения на Streamlit — скрипты, исполняющиеся сверху вниз. В них нет скрытого состояния. Если вы умеете писать на Python, вы умеете создавать приложения на Streamlit. Вот как происходит вывод на экран:
import streamlit as st st.write('Hello, world!')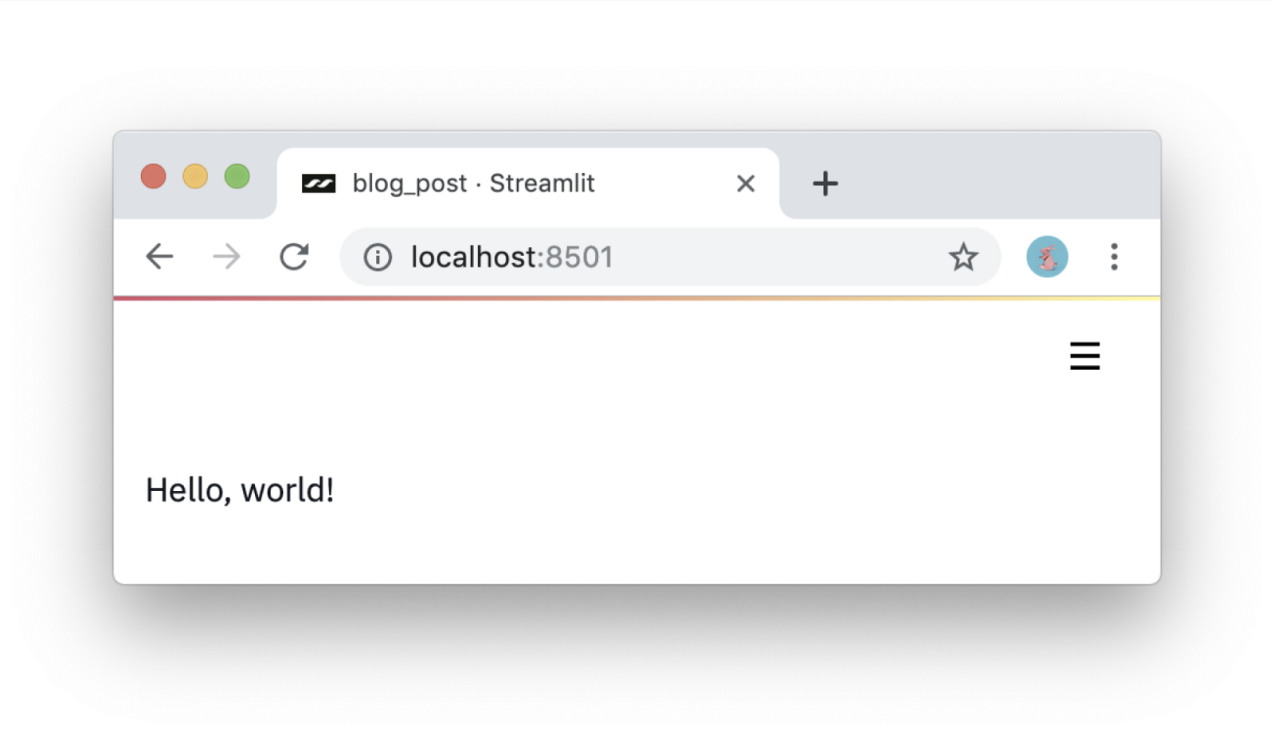
#2: Воспринимайте виджеты как переменные. В Streamlit нет колбэков! Каждое изменение просто перезапускает скрипт сверху вниз. Такой подход позволяет писать код чище:
import streamlit as st x = st.slider('x') st.write(x, 'squared is', x * x)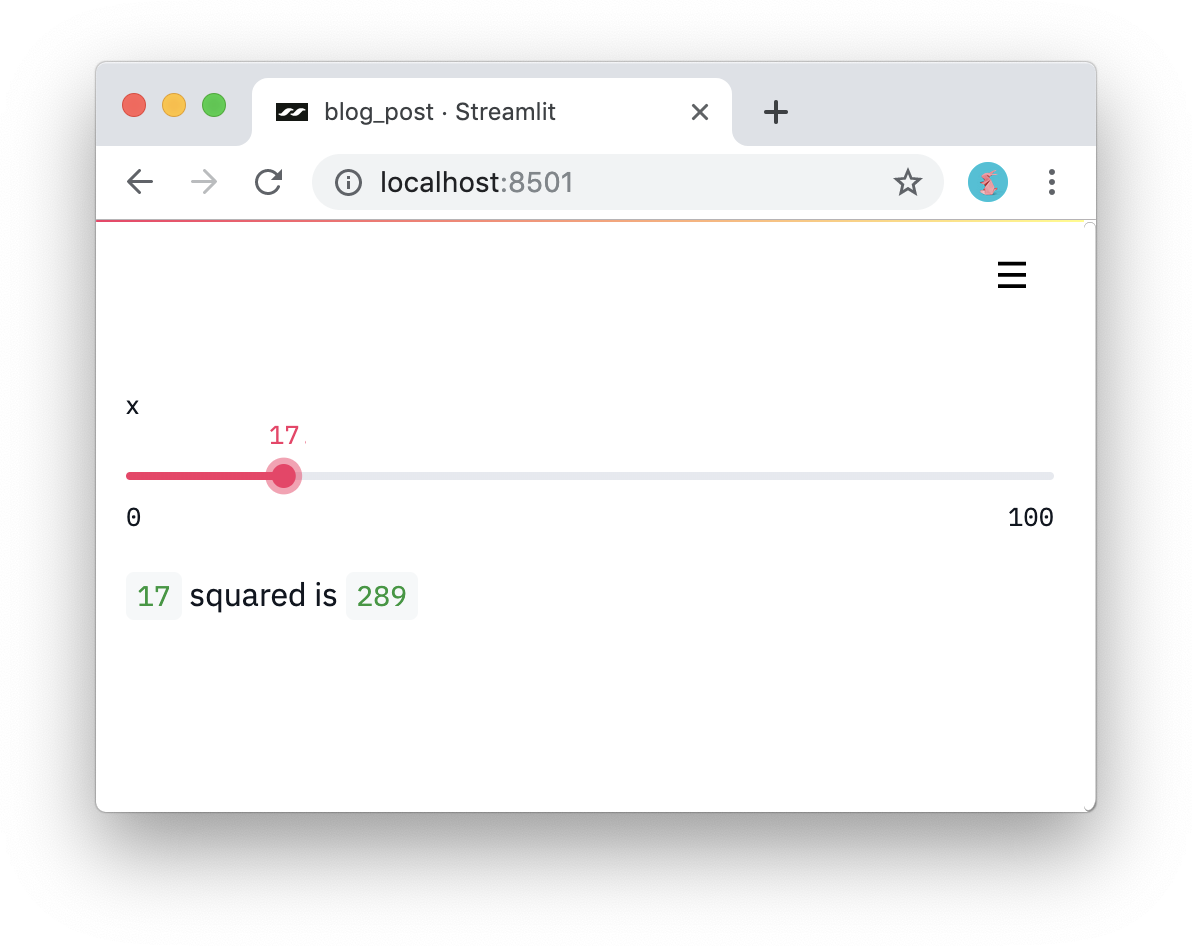
#3: Используйте данные и вычисления многократно. Что, если вы скачали много данные для выполнения длительных вычислений? Тогда важно будет использовать их повторно между перезапусками. В Streamlit есть примитив для персистентного кэширования неизменяемого по умолчанию состояния. Так, например, код ниже скачивает данные из проекта Udacity по самоуправляемым авто единожды, выдавая простое и красивое приложение:
import streamlit as st import pandas as pd # Reuse this data across runs! read_and_cache_csv = st.cache(pd.read_csv) BUCKET = "https://streamlit-self-driving.s3-us-west-2.amazonaws.com/" data = read_and_cache_csv(BUCKET + "labels.csv.gz", nrows=1000) desired_label = st.selectbox('Filter to:', ['car', 'truck']) st.write(data[data.label == desired_label])Для запуска кода выше следуйте инструкциям отсюда.

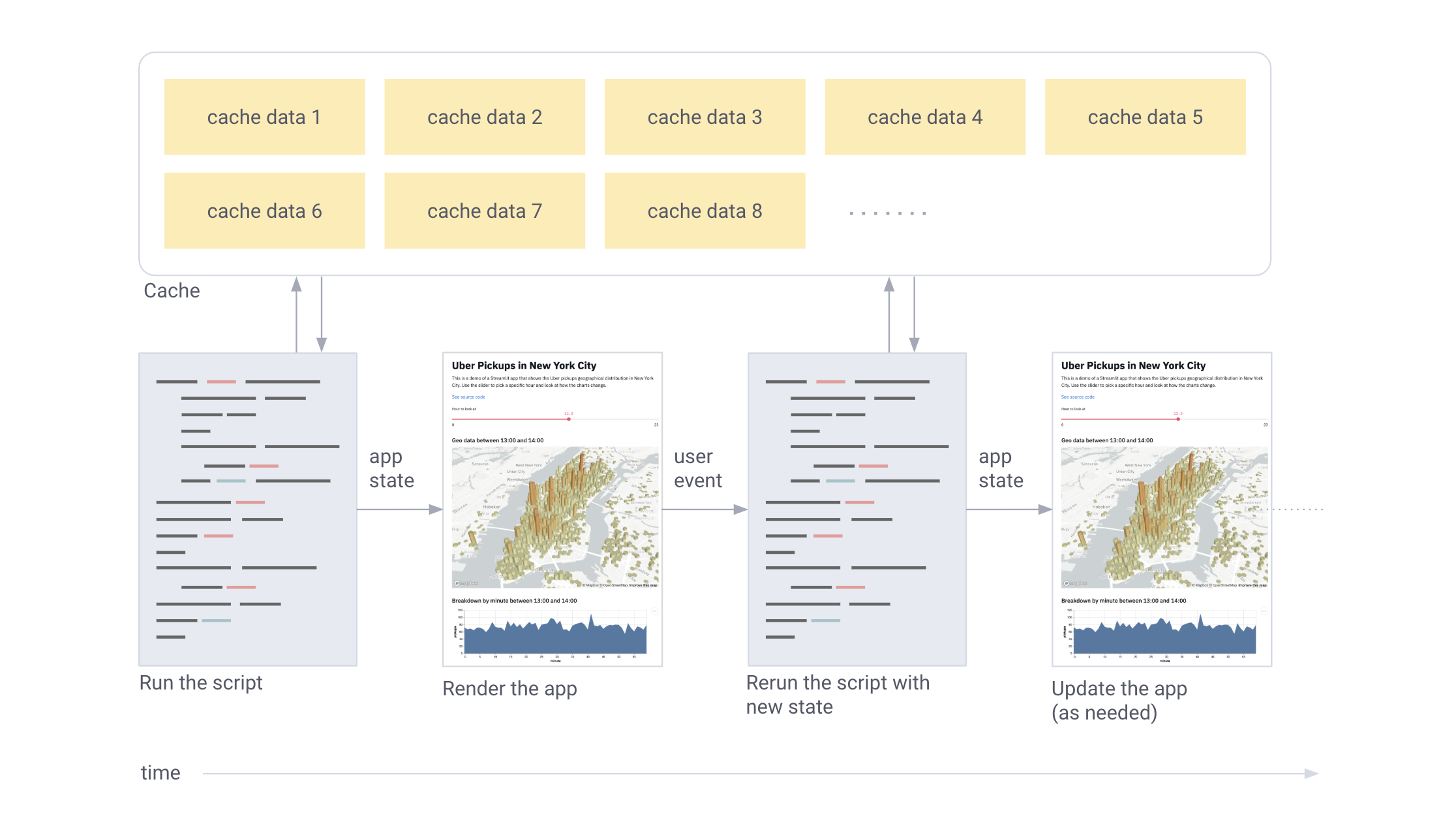
Короче говоря, Streamlit работает так:
- Скрипт каждый раз запускается заново
- Streamlit присваивает каждой переменной актуальное значение из виджетов.
- Кэширование позволяет избежать лишнего обращения к сети или долгих перерасчётов.
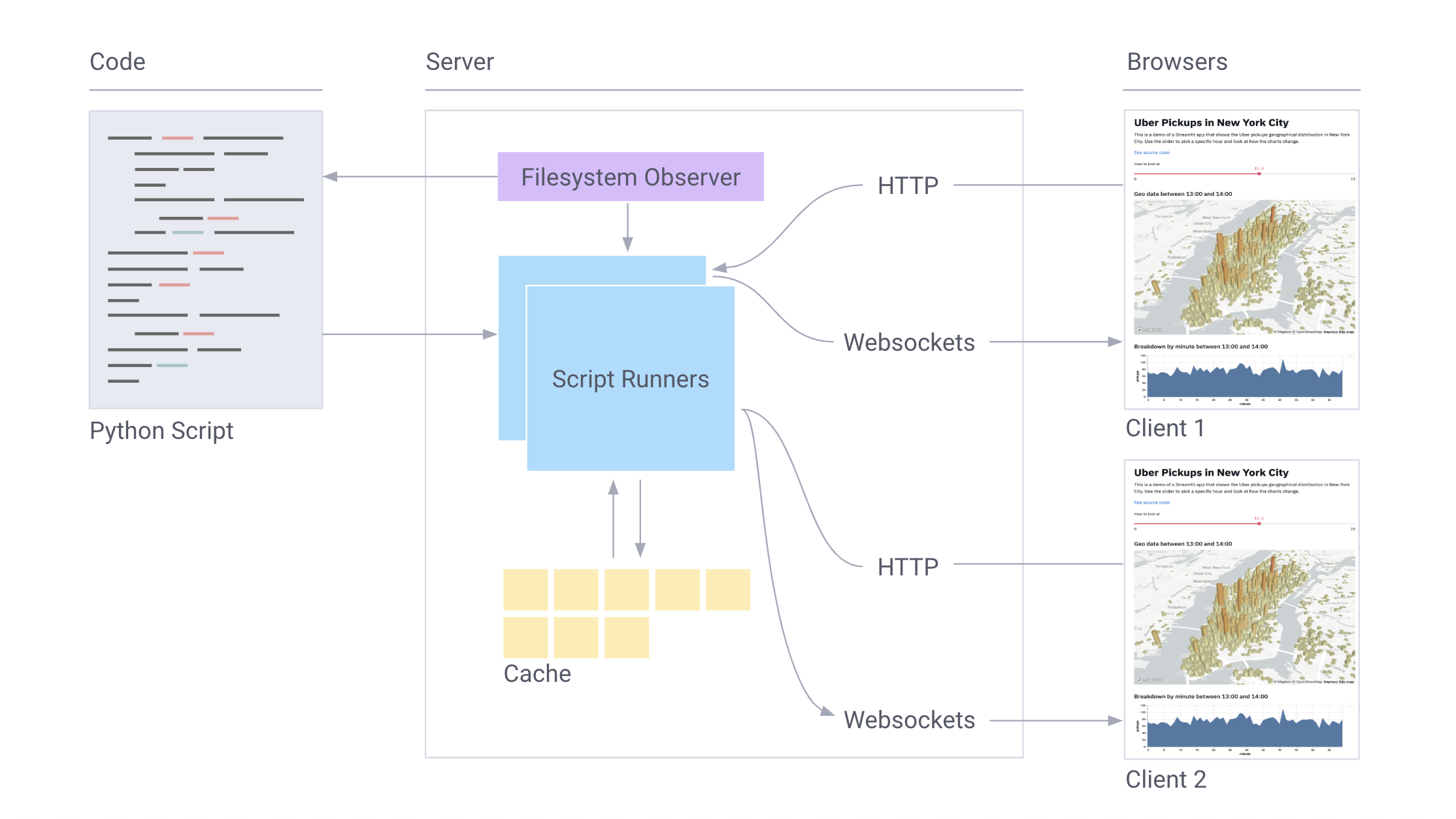
Работа Streamlit в картинках:
Заинтригованы? Тогда попробуйте сами! Выполните:
$ pip install --upgrade streamlit $ streamlit hello Теперь приложение доступно из браузера. Локальный URL: http://localhost:8501 Сетевой URL: http://10.0.1.29:8501Этот код откроет приложение Streamlit в браузере. Если этого не произошло, просто кликните по ссылке.

Ещё не наигрались с фракталами? Будьте осторожны, с фракталами можно залипнуть надолго.
Простота примеров не должна вводить в заблуждение: на Streamlit можно создавать огромные приложения. Работая в Zoox и Google X, я видел как проекты по самоуправляемым авто раздувались до гигабайтов визуальных данных, которые необходимо найти и обработать, включая испытания разных моделей для сравнения производительности. Каждый небольшой проект по самоуправляемым машинам рано или поздно разрастался до размеров требующих отдельной команды разработчиков.
Но со Streamlit создание таких приложений тривиально. Вот демо на Streamlit, где реализован полноценный семантический поиск по всему массиву данных Udacity для самоуправляемых машин, визуализация аннотированных людьми меток и запуск полноценной нейросети (YOLO) в реальном времени внутри того же приложения [1].

Приложение полностью самодостаточно, большую часть из 300 строк занимает машинное обучение. Более того, API Streamlit вызывается всего 23 раза. Попробуйте сами!
$ pip install --upgrade streamlit opencv-python $ streamlit run https://raw.githubusercontent.com/streamlit/demo-self-driving/master/app.pyВ процессе работы с командами по машинному обучению мы поняли, что несколько простых идей окупаются сторицей:
Приложения на Streamlit — обычные питоновские файлы. А значит, вы можете использовать свой любимый редактор для разработки всего приложения.

Чистые скрипты без проблем хранятся в Git или других системах контроля версий. Работая с чистым питоном, вы получаете огромный пул готовых инструментов для разработки в команде .
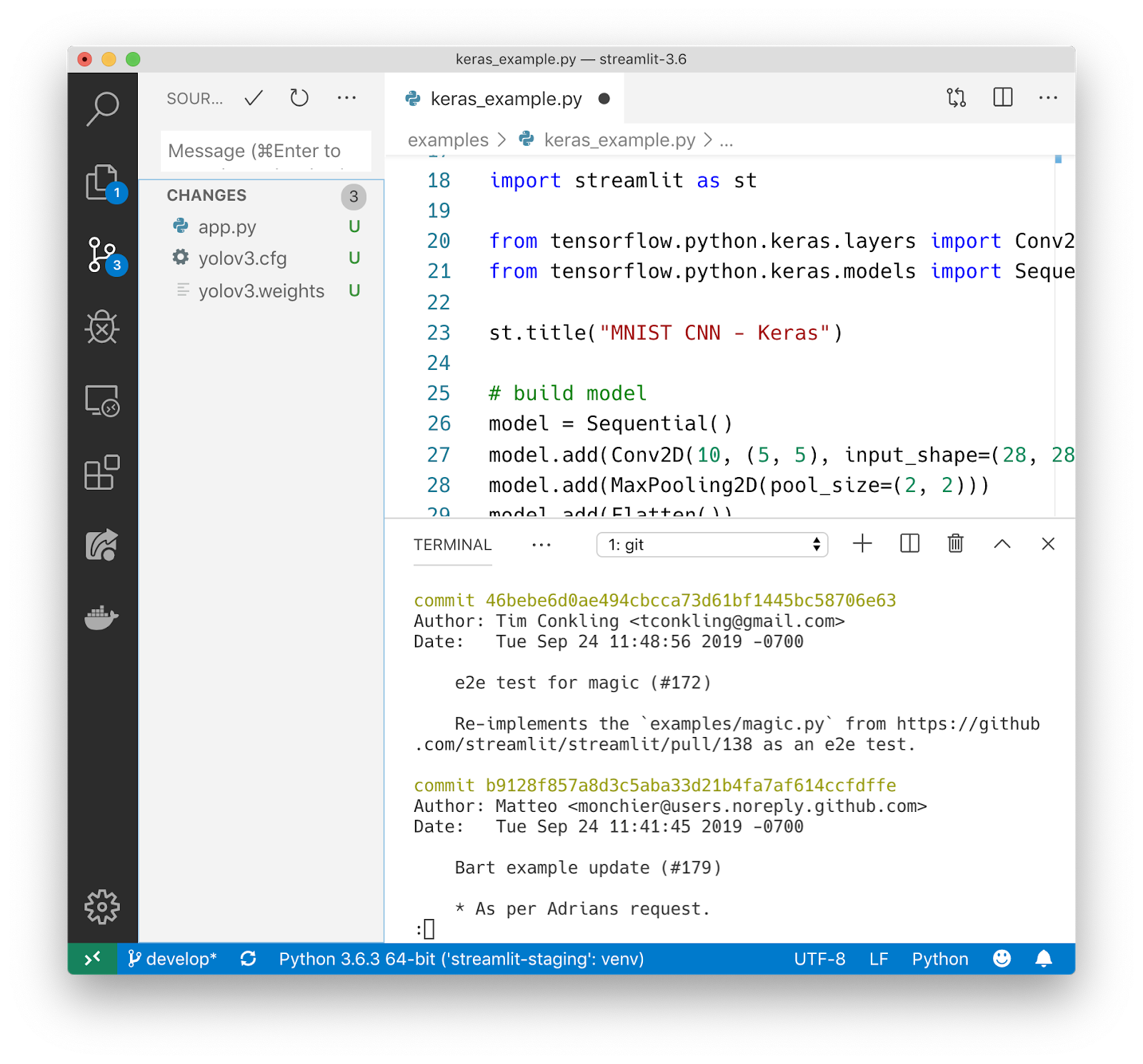
Streamlit — это среда для кодинга с мгновенным откликом. Просто кликните Always rerun, когда Streamlit заметит изменение исходного файла.

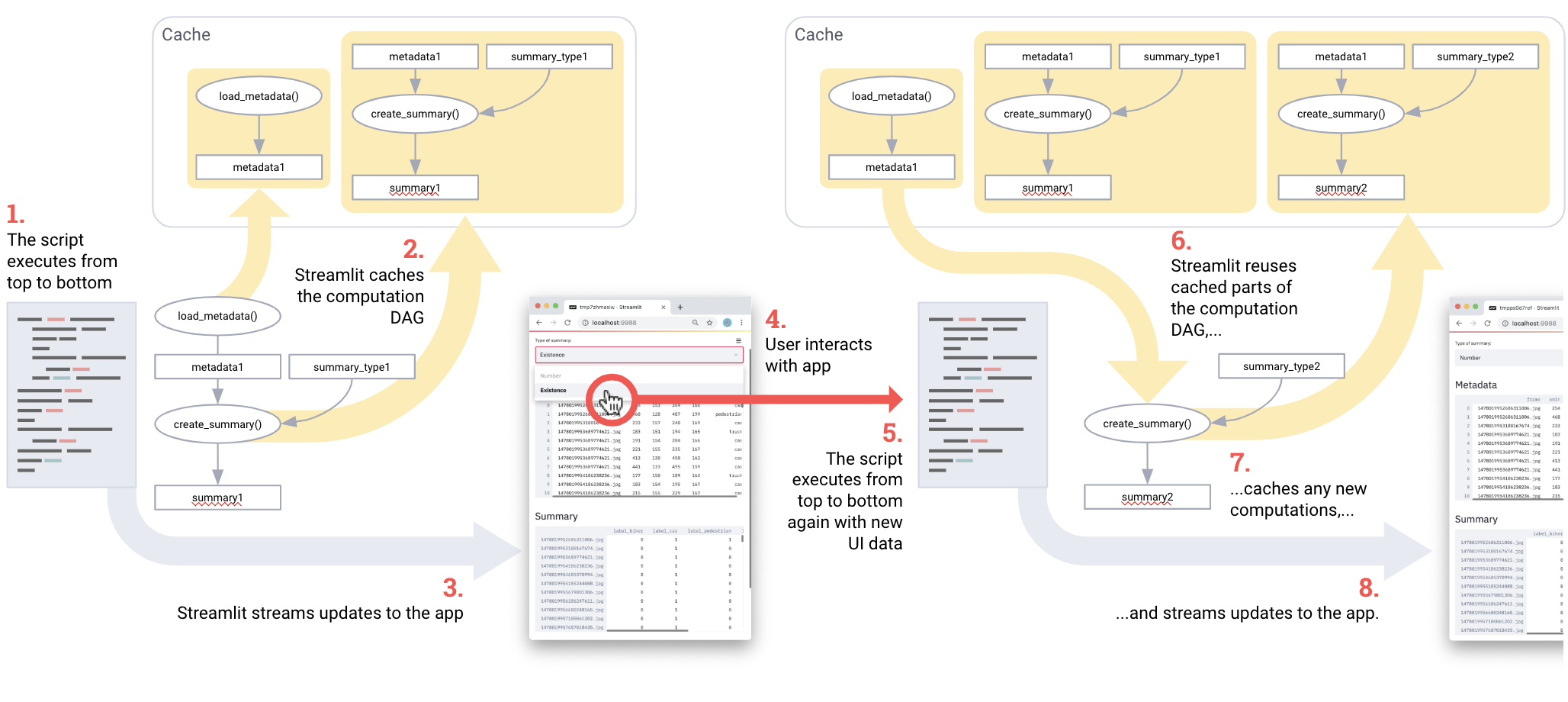
Кэширование значительно упрощает работу с цепочкой вычислений. Соединение нескольких результатов кэширования отлично работает как эффективный пайплайн для вычислений! Посмотрите на этот код взятый из Udacity демо:
import streamlit as st import pandas as pd @st.cache def load_metadata(): DATA_URL = "https://streamlit-self-driving.s3-us-west-2.amazonaws.com/labels.csv.gz" return pd.read_csv(DATA_URL, nrows=1000) @st.cache def create_summary(metadata, summary_type): one_hot_encoded = pd.get_dummies(metadata[["frame", "label"]], columns=["label"]) return getattr(one_hot_encoded.groupby(["frame"]), summary_type)() # Piping one st.cache function into another forms a computation DAG. summary_type = st.selectbox("Type of summary:", ["sum", "any"]) metadata = load_metadata() summary = create_summary(metadata, summary_type) st.write('## Metadata', metadata, '## Summary', summary)Пайплайн для вычислений на Streamlit. Чтобы запустить скрипт, следуйте этой инструкции.
Фактически, пайплайн это load_metadata ? create_summary. При каждом запуске скрипта Streamlit пересчитывает только то, что нужно для корректного результата. Круть!
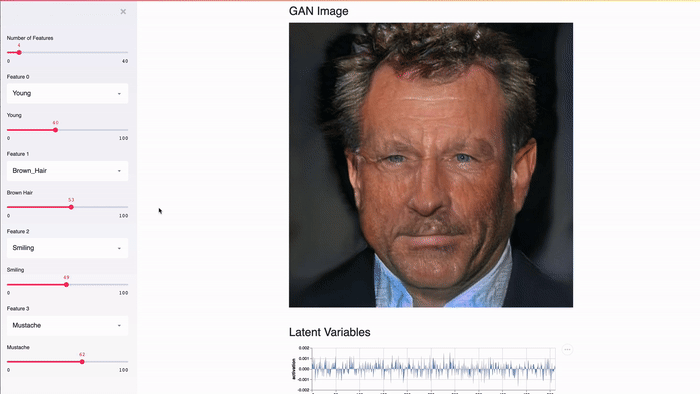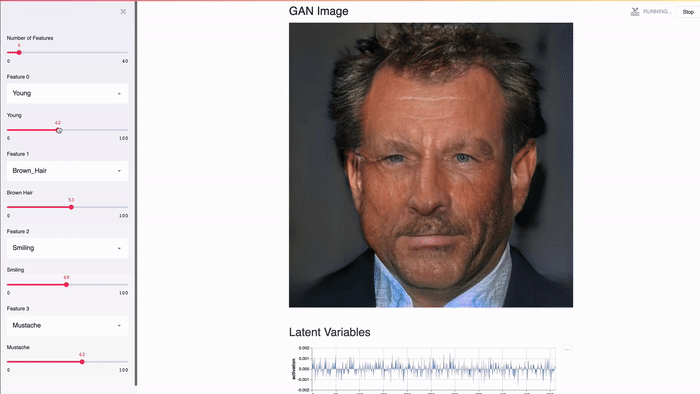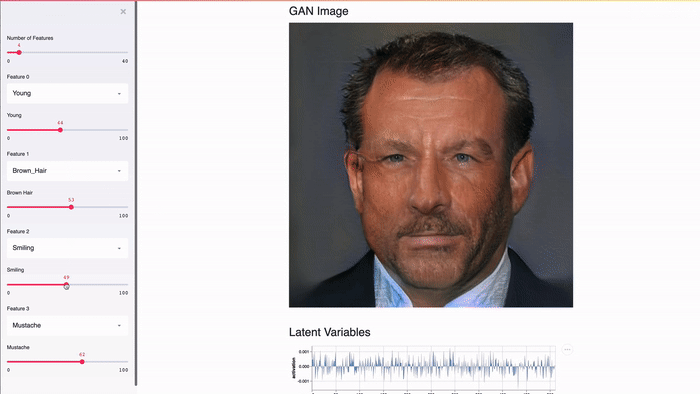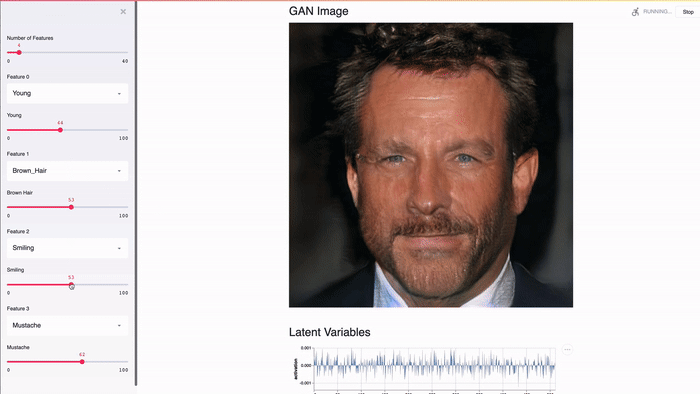
Streamlit создан для работы с GPU. Streamlit позволяет работать напрямую с TensorFlow, PyTorch и другими подобными библиотеками. Например, в этом демо кэш Streamlit хранит GAN лиц знаменитостей от NVIDIA [2]. Это позволяет добиться почти мгновенного отклика при изменении значений слайдера.
Streamlit — опенсорсный проект. Вы можете свободно распространять приложения на Streamlit, не спрашивая у нас разрешения. Вы даже можете запускать приложения на Streamlit локально без подключения к интернету! А уже существующие проекты могут внедрять Streamlit постепенно.

И это лишь общий обзор возможностей Streamlit. Одним из самых крутых аспектов библиотеки является простота комбинирования примитивов в огромные приложения. Нам есть что ещё рассказать об инфраструктуре Streamlit и планах на будущее, но мы прибережём это для следующих публикаций.
Мы счастливы поделиться Streamlit с миром и надеемся что с ним ваши питоновские скрипты по ML превратятся в красивые полноценные приложения.
Ссылки:
[1] J. Redmon and A. Farhadi, YOLOv3: An Incremental Improvement (2018), arXiv.
[2] T. Karras, T. Aila, S. Laine, and J. Lehtinen, Progressive Growing of GANs for Improved Quality, Stability, and Variation (2018), ICLR.
[3] S. Guan, Controlled image synthesis and editing using a novel TL-GAN model (2018), Insight Data Science Blog.