Понимание поисковых запросов лучше, чем когда-либо прежде
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2019-10-30 21:14
Если есть одна вещь, которую я узнал за 15 лет работы над поиском Google, это то, что любопытство людей бесконечно. Мы видим миллиарды запросов каждый день, и 15 процентов из этих запросов-это те, которые мы не видели раньше, поэтому мы построили способы возврата результатов для запросов, которые мы не можем предвидеть.
Когда такие люди, как вы или я, приходят на поиски, мы не всегда уверены в том, как лучше сформулировать запрос. Мы можем не знать правильных слов, чтобы использовать, или как написать что-то, потому что часто мы приходим к поиску, чтобы узнать-у нас не обязательно есть знание, чтобы начать.
По своей сути, поиск связан с пониманием языка. Это наша работа, чтобы выяснить, что вы ищете и поверхность полезную информацию из интернета, независимо от того, как вы пишете или объединить слова в вашем запросе. Хотя мы продолжали улучшать наши возможности понимания языка на протяжении многих лет, мы иногда все еще не совсем правильно понимаем его, особенно со сложными или разговорными запросами. На самом деле, это одна из причин, по которой люди часто используют “keyword-ese”, набирая строки слов, которые, как они думают, мы поймем, но на самом деле не так, как они естественно задают вопрос.
Благодаря последним достижениям нашей исследовательской группы в области понимания языка,ставшим возможными благодаря машинному обучению,мы значительно улучшаем понимание запросов, что представляет собой самый большой скачок вперед за последние пять лет и один из самых больших скачков вперед в истории поиска.
Применяя модели Берта для поиска
в прошлом году, мы представили и открыли метод нейронной сети на основе обработки естественного языка (NLP) предварительной подготовки , называемой двунаправленными Кодировочными представлениями от трансформаторов, или, как мы это называем-- BERT, для краткости. Эта технология позволяет любому человеку обучить свою собственную современную систему ответов на вопросы.
Этот прорыв стал результатом исследований Google по трансформаторам: моделям, которые обрабатывают слова по отношению ко всем другим словам в предложении, а не по одному в порядке. Поэтому модели BERT могут рассматривать полный контекст слова, рассматривая слова, которые приходят до и после него, что особенно полезно для понимания цели, стоящей за поисковыми запросами.
Но это не только достижения в области программного обеспечения, которые могут сделать это возможным: нам также требовалось новое оборудование. Некоторые модели, которые мы можем построить с помощью BERT, настолько сложны, что они раздвигают границы того, что мы можем сделать с использованием традиционного оборудования, поэтому впервые мы используем новейшие облачные ТПУ для обслуживания результатов поиска и быстрого получения более актуальной информации.
Взламывая ваши запросы
, так что это много технических деталей, но что все это значит для вас? Ну, применяя модели BERT к ранжированию и признакам фрагментов в поиске, мы можем сделать гораздо лучшую работу, помогая вам найти полезную информацию. На самом деле, когда речь заходит о результатах ранжирования, BERT поможет поиск лучше понять один из 10 поисков в США на английском языке, и мы принесем это на большее количество языков и локалей с течением времени.
В частности, для более длинных, более разговорных запросов или поисков, где предлоги, такие как “for” и “to”, имеют большое значение для значения, Search сможет понять контекст слов в вашем запросе. Вы можете искать таким образом, который кажется вам естественным.
Чтобы запустить эти улучшения, мы провели много тестов, чтобы убедиться, что изменения на самом деле являются более полезными. Вот некоторые из примеров, которые показали наш процесс оценки, демонстрирующий способность Берта понять намерение, стоящее за вашим поиском.
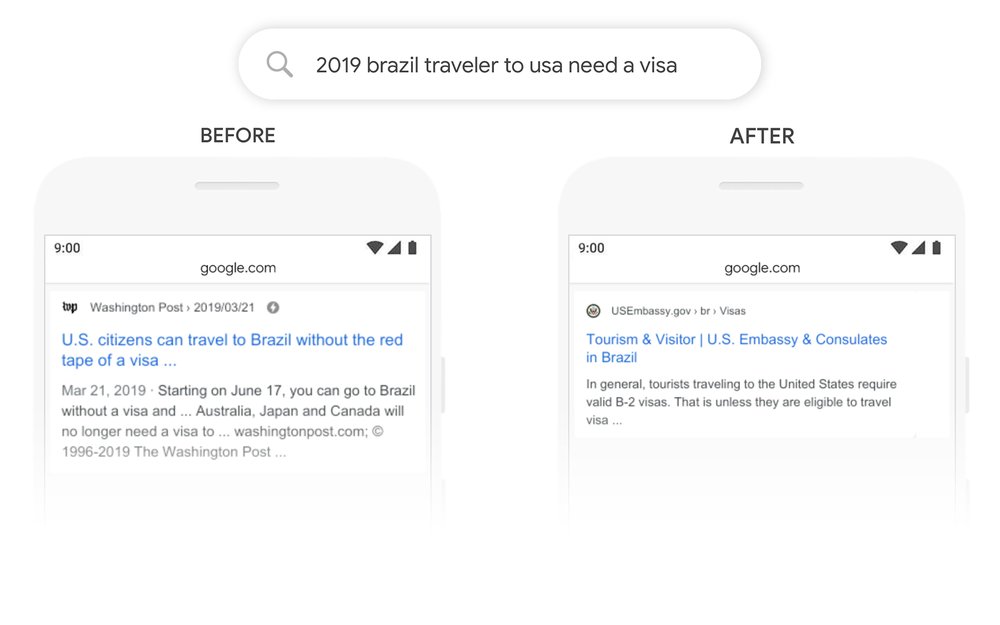
Вот поиск “2019 Бразилия путешественник в США нужна виза."Слово" to " и его отношение к другим словам в запросе особенно важны для понимания значения. Речь идет о бразильце, путешествующем в США, а не наоборот. Ранее наши алгоритмы не понимали важности этой связи, и мы вернули результаты о гражданах США, путешествующих в Бразилию. С помощью BERT, Search способен уловить этот нюанс и знать, что очень распространенное слово “to” На самом деле имеет здесь большое значение, и мы можем предоставить гораздо более релевантный результат для этого запроса.
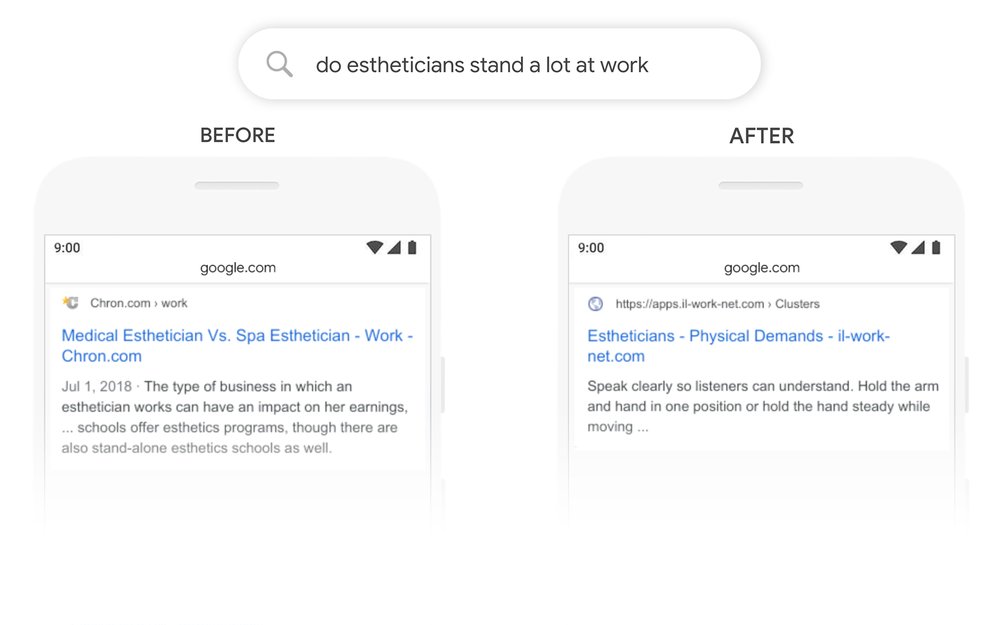
Давайте рассмотрим еще один вопрос: "много ли стоят эстетики на работе."Ранее наши системы использовали подход подбора ключевых слов, сопоставляя термин" автономный “в результате со словом” стенд " в запросе. Но это не совсем правильное использование слова “стоять” в контексте. Наши модели BERT, с другой стороны, понимают, что “стенд” связан с понятием физических требований к работе и отображает более полезный ответ.
Вот некоторые другие примеры, где Берт помог нам понять тонкие нюансы языка, которые компьютеры не совсем понимают так, как люди.
Берт в поиске: пример аптеки
С помощью модели BERT мы можем лучше понять, что “для кого-то” является важной частью этого запроса, тогда как ранее мы пропустили смысл, с общими результатами о заполнении предписаний.
Улучшение поиска на большем количестве языков
мы также применяем BERT, чтобы сделать поиск лучше для людей по всему миру. Мощная характеристика этих систем заключается в том, что они могут брать знания из одного языка и применять их к другим. Таким образом, мы можем взять модели, которые учатся от улучшений на английском языке (язык, где существует подавляющее большинство веб-контента) и применить их к другим языкам. Это помогает нам лучше возвращать релевантные результаты на многих языках, на которых предлагается Поиск.
Для избранных фрагментов мы используем модель BERT для улучшения избранных фрагментов в двух десятках стран, где эта функция доступна, и видим значительные улучшения в таких языках, как корейский, хинди и португальский.
Поиск не является решенной проблемой
независимо от того, что вы ищете, или на каком языке вы говорите, мы надеемся, что вы сможете отпустить некоторые из ваших ключевых слов-ese и искать таким образом, который чувствует себя естественным для вас. Но вы все равно будете время от времени ставить Google в тупик. Даже с Бертом мы не всегда все делаем правильно. Если вы ищете “какой штат находится к югу от Небраски“, лучшее предположение Берта-это сообщество под названием " Южная Небраска.” "Если у тебя есть предчувствие, что это не в Канзасе, то ты прав.)
Понимание языка остается постоянной проблемой, и это заставляет нас продолжать совершенствовать Поиск. Мы всегда становимся лучше и работаем, чтобы найти смысл в-и наиболее полезную информацию для-каждого запроса, который вы отправляете нам.
Телеграм: t.me/ainewsline
Источник: www.blog.google