Обучи свою первую нейросеть: простая классификация
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2019-10-15 17:13
работа мозга, Основы нейронных сетей, Нейронные сети для начинающих
Это руководство поможет тебе обучить нейросеть, которая классифицирует изображения одежды, например, кроссовки и рубашки. Это нормально, если не все будет понятно сразу: это быстрый, ознакомительный обзор полной программы TensorFlow, где новые детали объясняются по мере их появления.
Руководство использует tf.keras, высокоуровневый API для построения и обучения моделей в TensorFlow.
2.0.0
Загружаем датасет Fashion MNIST
Это руководство использует датасет Fashion MNIST который содержит 70,000 монохромных изображений в 10 категориях. На каждом изображении содержится по одному предмету одежды в низком разрешении (28 на 28 пикселей):
| |
| Figure 1. Образцы Fashion-MNIST (Zalando, лицензия MIT). |
Fashion MNIST предназначен для замены классического датасета MNIST который часто используют как "Hello, World" программ машинного обучения для компьютерного зрения. Датасет MNIST содержит изображения рукописных цифр (0, 1, 2, и т.д.) в формате идентичном формату изображений одежды которыми мы будем пользоваться здесь.
Это руководство для разнообразия использует Fashion MNIST, и еще потому, что это проблема немного сложнее чем обычный MNIST. Оба датасета относительно малы, и используются для проверки корректности работы алгоритма. Это хорошие отправные точки для тестирования и отладки кода.
Мы используем 60,000 изображений для обучения нейросети и 10,000 изображений чтобы проверить, насколько правильно сеть обучилась их классифицировать. Вы можете получить доступ к Fashion MNIST прямо из TensorFlow. Импортируйте и загрузите данные Fashion MNIST прямо из TensorFlow:
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/train-labels-idx1-ubyte.gz 32768/29515 [=================================] - 0s 0us/step Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/train-images-idx3-ubyte.gz 26427392/26421880 [==============================] - 0s 0us/step Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/t10k-labels-idx1-ubyte.gz 8192/5148 [===============================================] - 0s 0us/step Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/t10k-images-idx3-ubyte.gz 4423680/4422102 [==============================] - 0s 0us/step
Загрузка датасета возвращает четыре массива NumPy:
- Массивы
train_imagesиtrain_labelsявляются тренировочным сетом — данными, на которых модель будет обучаться. - Модель тестируется на проверочном сете, а именно массивах
test_imagesиtest_labels.
Изображения являются 28х28 массивами NumPy, где значение пикселей варьируется от 0 до 255. Метки (labels) - это массив целых чисел от 0 до 9. Они соответствуют классам одежды изображенной на картинках:
| Label | Class |
|---|---|
| 0 | T-shirt/top |
| 1 | Trouser |
| 2 | Pullover |
| 3 | Dress |
| 4 | Coat |
| 5 | Sandal |
| 6 | Shirt |
| 7 | Sneaker |
| 8 | Bag |
| 9 | Ankle boot |
Каждому изображению соответствует единственная метка. Так как названия классов не включены в датасет, сохраним их тут для дальнейшего использования при построении изображений:
Изучите данные
Давайте посмотрим на формат данных перед обучением модели. Воспользовавшись shape мы видим, что в тренировочном датасете 60,000 изображений, каждое размером 28 x 28 пикселей:
(60000, 28, 28)
Соответственно, в тренировочном сете 60,000 меток:
60000
Каждая метка это целое число от 0 до 9:
array([9, 0, 0, ..., 3, 0, 5], dtype=uint8)
Проверочный сет содержит 10,000 изображений, каждое - также 28 на 28 пикселей:
(10000, 28, 28)
И в проверочном сете - ровно 10,000 меток:
10000
Предобработайте данные
Данные должны быть предобработаны перед обучением нейросети. Если вы посмотрите на первое изображение в тренировочном сете вы увидите, что значения пикселей находятся в диапазоне от 0 до 255:
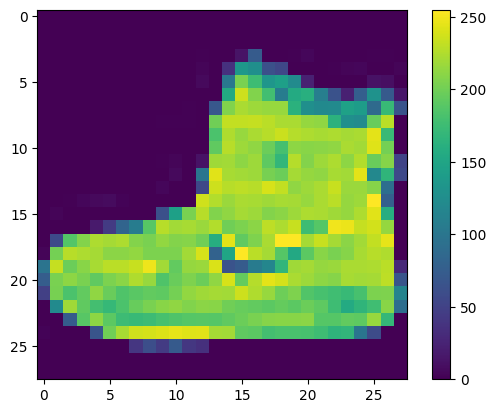
Мы масштабируем эти значения к диапазону от 0 до 1 перед тем как скормить их нейросети. Для этого мы поделим значения на 255. Важно, чтобы тренировочный сет и проверочный сет были предобработаны одинаково:
Чтобы убедиться, что данные в правильном формате и мы готовы построить и обучить нейросеть, выведем на экран первые 25 изображений из тренировочного сета и отобразим под ними наименования их классов.

Постройте модель
Построение модели нейронной сети требует правильной конфигурации каждого слоя, и последующей компиляции модели.
Настройте слои
Базовым строительным блоком нейронной сети является слой. Слои извлекают образы из данных, которые в них подаются. Надеемся, что эти образы имеют смысл для решаемой задачи.
Большая часть глубокого обучения состоит из соединения в последовательность простых слоев. Большинство слоев, таких как tf.keras.layers.Dense, имеют параметры, которые настраиваются во время обучения.
Первый слой этой сети - tf.keras.layers.Flatten, преобразует формат изображения из двумерного массива (28 на 28 пикселей) в одномерный (размерностью 28 * 28 = 784 пикселя). Слой извлекает строки пикселей из изображения и выстраивает их в один ряд. Этот слой не имеет параметров для обучения; он только переформатирует данные.
После разложения пикселей, нейросеть содержит два слоя tf.keras.layers.Dense. Это полносвязные нейронные слои. Первый Dense слой состоит из 128 узлов (или нейронов). Второй (и последний) 10-узловой softmax слой возвращает массив из 10 вероятностных оценок дающих в сумме 1. Каждый узел содержит оценку указывающую вероятность принадлежности изображения к одному из 10 классов.
Скомпилируйте модель
Прежде чем модель будет готова для обучения, нам нужно указать еще несколько параметров. Они добавляются на шаге compile модели:
- Функция потерь (Loss function) — измеряет точность модели во время обучения. Мы хотим минимизировать эту функцию чтоб "направить" модель в верном направлении.
- Оптимизатор (Optimizer) — показывает каким образом обновляется модель на основе входных данных и функции потерь.
- Метрики (Metrics) — используются для мониторинга тренировки и тестирования модели. Наш пример использует метрику accuracy равную доле правильно классифицированных изображений.
Обучите модель
Обучение модели нейронной сети требует выполнения следующих шагов::
- Подайте тренировочный данные в модель. В этом примере тренировочные данные это массивы
train_imagesиtrain_labels. - Модель учится ассоциировать изображения с правильными классами.
- Мы просим модель сделать прогнозы для проверочных данных, в этом примере массив test_images. Мы проверяем, соответствуют ли предсказанные классы меткам из массива test_labels.
Для начала обучения, вызовите метод model.fit, который называется так, поскольку "тренирует (fits)" модель на тренировочных данных:
Train on 60000 samples Epoch 1/10 60000/60000 [==============================] - 4s 72us/sample - loss: 0.4963 - accuracy: 0.8261 Epoch 2/10 60000/60000 [==============================] - 4s 60us/sample - loss: 0.3736 - accuracy: 0.8647 Epoch 3/10 60000/60000 [==============================] - 4s 60us/sample - loss: 0.3347 - accuracy: 0.8789 Epoch 4/10 60000/60000 [==============================] - 4s 60us/sample - loss: 0.3144 - accuracy: 0.8843 Epoch 5/10 60000/60000 [==============================] - 4s 62us/sample - loss: 0.2962 - accuracy: 0.8903 Epoch 6/10 60000/60000 [==============================] - 4s 61us/sample - loss: 0.2829 - accuracy: 0.8957 Epoch 7/10 60000/60000 [==============================] - 4s 60us/sample - loss: 0.2679 - accuracy: 0.9009 Epoch 8/10 60000/60000 [==============================] - 4s 60us/sample - loss: 0.2585 - accuracy: 0.9029 Epoch 9/10 60000/60000 [==============================] - 4s 60us/sample - loss: 0.2493 - accuracy: 0.9066 Epoch 10/10 60000/60000 [==============================] - 4s 60us/sample - loss: 0.2428 - accuracy: 0.9098 <tensorflow.python.keras.callbacks.History at 0x7f4f741a8198>
В процессе обучения модели отображаются метрики потери (loss) и точности (accuracy). Эта модель достигает на тренировочных данных точности равной приблизительно 0.88 (88%).
Оцените точность
Далее, сравните какую точность модель покажет на проверчном датасете:
10000/1 - 1s - loss: 0.2610 - accuracy: 0.8787 Точность на проверочных данных: 0.8787
Полученная на проверочном сете точность оказалась немного ниже, чем на тренировочном. Этот разрыв между точностью на тренировке и тесте является примером переобучения (overfitting) . Переобучение возникает, когда модель машинного обучения показывает на новых данных худший результат, чем на тех, на которых она обучалась.
Сделайте предсказания
Теперь, когда модель обучена, мы можем использовать ее чтобы сделать предсказания по поводу нескольких изображений:
Здесь полученная модель предсказала класс одежды для каждого изображения в проверочном датасете. Давайте посмотрим на первое предсказание:
array([3.9092092e-06, 5.0955748e-08, 1.0088089e-08, 1.7653681e-09, 1.0856661e-08, 2.4640898e-04, 3.9162201e-06, 1.8451020e-02, 1.2714973e-05, 9.8128188e-01], dtype=float32)
Прогноз представляет из себя массив из 10 чисел. Они описывают "уверенность" (confidence) модели в том, насколько изображение соответствует каждому из 10 разных видов одежды. Мы можем посмотреть какой метке соответствует максимальное значение:
9
Модель полагает, что на первой картинке изображен ботинок (ankle boot), или class_names[9]. Проверка показывает, что классификация верна:
9
Мы можем построить график, чтобы взглянуть на полный набор из 10 предсказаний классов.
Давайте посмотрим на нулевое изображение, предсказание и массив предсказаний.
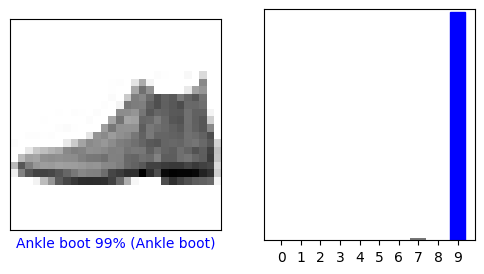
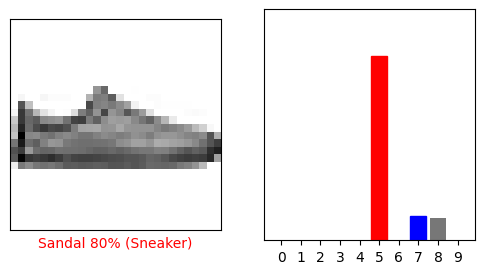
Давайте посмотрим несколько изображений с их прогнозами. Цвет верных предсказаний синий, а неверных - красный. Число это процент уверенности (от 100) для предсказанной метки. Отметим, что модель может ошибаться даже если она очень уверена.

Наконец, используем обученную модель для предсказания класса на одном изображении.
(28, 28)
Модели tf.keras оптимизированы для предсказаний на пакетах (batch) данных, или на множестве примеров сразу. Таким образом, даже если мы используем всего 1 картинку, нам все равно необходимо добавить ее в список:
(1, 28, 28)
Сейчас предскажем правильную метку для изображения:
[[3.9092124e-06 5.0955748e-08 1.0088108e-08 1.7653681e-09 1.0856661e-08 2.4640947e-04 3.9162242e-06 1.8451029e-02 1.2714986e-05 9.8128188e-01]]
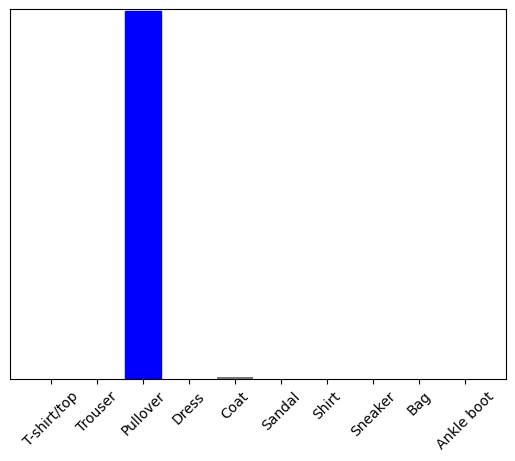
Метод model.predict возвращает нам список списков, по одному для каждой картинки в пакете данных. Получите прогнозы для нашего (единственного) изображения в пакете:
9
И, как и ранее, модель предсказывает класс 9.
Телеграм: t.me/ainewsline
Источник: www.tensorflow.org