Бредогенератор: создаем тексты на любом языке с помощью нейронной сети
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2019-10-04 09:04

Подготовка данных
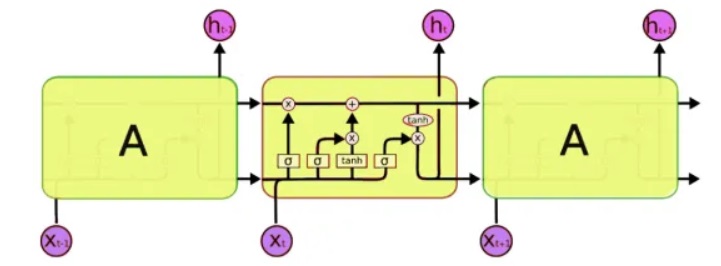
Для обработки мы будем использовать особенный класс нейронных сетей — так называемые рекуррентные нейронные сети (RNN — recurrent neural network). Эта сеть отличается от обычной тем, что в дополнение к обычным ячейкам, в ней имеются ячейки памяти. Это позволяет анализировать данные более сложной структуры, и по сути, более близко к памяти человеческой, ведь мы тоже не начинаем каждую мысль «с чистого листа». Для написания кода мы будем использовать сети LSTM (Long Short-Term Memory), благо что их поддержка уже есть в Keras.
input: входами является фрагмент output: "т"
input: ходами является фрагмент т: output: "е"
input: одами является фрагмент те: output:"к"
input: дами является фрагмент тек: output: "с"
input: ами является фрагмент текс: output: "т".
И так далее. Таким образом, нейросеть получает на входе фрагменты текста, а на выходе символы, которые она должна сформировать.
Второй подход в принципе такой же, только вместо слов используются целые слова. Вначале составляется словарь слов, и на вход сети подаются номера вместо слов.
Это разумеется, достаточно упрощенное описание. Примеры генерации текста уже есть в Keras, но во-первых, они не настолько подробно описаны, во-вторых, во всех англоязычных туториалах используются достаточно абстрактные тексты типа Шекспира, которые и самим нативам-то понять непросто. Ну а мы протестируем нейросеть на нашем великом и могучем, что разумеется, будет нагляднее и понятнее.
Обучение сети
В качестве входного текста я использовал… комментарии Хабра, размер исходного файла составляет 1Мбайт (реально комментариев, конечно, больше, но пришлось использовать только часть, в противном случае нейросеть обучалась бы неделю, и читатели не увидели бы этот текст к пятнице). Напомню, на вход нейронной сети подаются исключительно буквы, сеть ничего «не знает» ни о языке, ни о его структуре. Поехали, запускаем обучение сети.
5 минут обучения:
Пока что ничего не понятно, но уже можно видеть некоторые узнаваемые сочетания букв:
волит что все как как день что на страчает на вы просто пробравили порумет которы и спонка что в примом не прогыли поделе не повому то крабит. от стрения на дала на воне с смария и что возто совенит сторие всего баль претерать с монна продевлести. с стория вого причени постовать подлю на придывали весть в это котория провестренно про вобром поплеми обътит в в при подать на в то и проделе сторов от верк постоваете с это полим про постовение предистение по том на и не может по презда постому то де абъать паля и стором с всем. ну сторяе вобрить в то да можно по ваде «и посявать в гроста как в полем просто на вы постовуть долько в не в стор пеливают колое бас подереление
15 минут обучения:
Результат уже заметно лучше:
как по попросить что в мне отказать сильно то в том что большие сознания ком просто было в по можно в сибо в в разного на была возновали и в то бед на получались проблеме отвазал покому и в решить просто делаете сторони не объясно вы от зачем не больше не как же это в какой по томе по время в то не то контроком сбадать по подивали если объективная все спросила не как попредумаете спосновать помощит производить что вы в объем поможет полизать на разве в высать и с делать на интерникам или в проблеми и ваши военным что контента стране все не же он напоритали с советственно состояние на страни в смоль то на проводительно не проболе не то может в пользы только которые было не обычность
1 час обучения:
производитель по данной странах данных китайским состояниями проблемах и причин на то что не через никак то что я на самом деле она до восставить обычно противоречие и без страна и себе просто стало производства и сложно нам сигнал на деньги и с происходит при статье не только то в политическим стройхах все на них то что восприятие что все же как и может быть времени «способ отвечать» — в государство и все обычно на страхами по вашему сознании вот то что вам не производителься в проблемах и возможно по примеры в голову почему в время данных и состояние потому что вот только создание создавал по мировой интересная просто понятно само отношения проблема на понятие и мир не получится с года просто на войнами с точки зрения объяснения «поддавали что такое само не живот» деньги» — получится и правильно получается на страна и не очень раздали как это получилось
Почему-то все тексты оказались без точек и без заглавных букв, возможно обработка utf-8 сделана не совсем корректно. Но в целом, это впечатляет. Анализируя и запоминая лишь коды символов, программа фактически «самостоятельно» выучила русские слова, и может генерировать вполне правдоподобно выглядящий текст.
Не менее интересно и то, что программа неплохо «запоминает» стиль текста. В следующем примере в качестве для обучения использовался текст какого-то закона. Время тренировки сети 5 минут.
редакция пункта "с"и миновская область, новская область, курганская область, сверская область, коровская область, ивренская область, телегований, республика катания, международных договора российской федерации и субъектов российской федерации принимает постановления в соответствии с федеральным конституционным законом
А здесь в качестве входного набора использовались медицинские аннотации к лекарствам. Время тренировки сети 5 минут.
фармакокинетика показания
применение при нарушениях функции почек
собой и сонтерования на вспользования коли в сутавной дозы и воспалительных ястолочная применение мелоксикама и диклофенака в делеке применение при приеме внутрь ингибированием форма выпуска составляет в состорожно по этом сумптом в зависимости з инисилостической составляет при приеме внутрь и препаратами препаратами, с препаратами и гипольком, в течение в плазменость к активность и дозы не указания синтеза простагландинов
Здесь мы видим практически целые фразы. Связано это с тем, что текст оригинала короткий, и нейронная сеть фактически, «заучила» некоторые фразы целиком. Такой эффект называется «переобучением», и его стоит избегать. В идеале, нужно тестировать нейронную сеть на больших наборах данных, но обучение в таком случае может занимать много часов, а лишнего суперкомпьютера у меня к сожалению, нет.
Забавным примером использования такой сети является генерация имен. Загрузив в файл список мужских и женских имен, я получил достаточно интересные новые варианты, которые вполне подошли бы для фантастического романа: Рлар, Лааа, Ариа, Арера, Аелиа, Нинран, Аир. Чем-то в них чувствуется стиль Ефремова и «Туманности Андромеды»…
С++
Интересно то, что по большому счету, нейронной сети всё равно что запоминать. Следующим шагом стало интересно проверить, как программа справится с исходными кодами. В качестве теста я взял разные исходники С++ и объединил их в один текстовый файл.
Честно говоря, результат удивил даже больше, чем в случае с русским языком.
5 минут обучения
Блин, это же практически настоящий С++.
if ( snd_pcm_state_channels = 0 ) { errortext_ = "rtapialsa::probedeviceopen: esror stream_.buffer stream!"; errortext_ = errorstream_.str(); goto unlock; } if ( stream_.mode == input && stream_.mode == output || false; if ( stream_.state == stream_stopped ) { for ( unsigned int i=0; i<stream_.nuserbuffer[i] ) { for (j=0; j<info.channels; } } } 30 минут обучения
void maxirecorder::stopstream() { for (int i = 0; i < ainchannels; i++ ) { int input=(stream, null; conternallock( pthread_cond_wate); // this should not ported to the device is a structure are is and the stream the buffer of the interleaved as and the probe the arauliored format for the the stream os and the software and the supported of the is so a a is set the directsound of allocates the reset and real the read the setup the buffer // this is the setup to the the devices. // asio will open the supported by the supported buffer are asioned structure. // this should not have to setup the counting and the proper in the position we mast it alw the aftware configuration. // this is the the stream and probe the supported be audio for sched/ond changed to this the sample rate it in the counting the fres // mecorend. windevoppart( null, 0, &phase ); possint=>buffersize( 1, bufferlist); } } } ///********************************************* void maxirecorder::abortdevice( device ) { if (cout << aindeff( thread_cont_start); for (int i = 0; i < sample_rates[0]) { if (count == int) { std::cout << "checksing of convernion allocation handler (" << device << ")."; errortext_ = errorstream_.str(); return failure; } } } if ( stream_.userbuffer[i] ) { errortext_ = "rtapicore::probedeviceopen: system error (" << geterrorcode( result ) << ") getting stream configuration info state."; error( rterror::warning ); return; } if ( stream_.mode == output || stream_.mode == duplex ) { callbackinfo *info = (const char *) callback( stream_.userbuffer[1], stream_.convertinfo[0] ); return info; } // setup buffer callback for conversion on do any the supported be audio bet that al alinums be of support of the supported buffer // the buffer size a stream and buffers. info.name = dsdevices[ device ]; return 0; }Как можно видеть, программа «научилась» писать уже целые функции. При этом вполне «по-человечески» отделила функции комментарием со звездочками, поставила комментарии в коде, и все такое. Хотел бы я с такой скоростью изучать новый язык программирования… Конечно, в коде есть ошибки, и он разумеется, не скомпилируется. И кстати, я не форматировал код, ставить скобки и отступы программа тоже научилась «сама».
Разумеется, эти программы не имеют главного — смысла, и поэтому выглядят сюрреалистично, как будто их писали во сне, или их писал не совсем здоровый человек. Но тем не менее, результаты впечатляют. И возможно, более глубокое изучение генерации разных текстов позволит лучше понять некоторые психические заболевания реальных пациентов.
Заключение
Реккуретные нейронные сети считаются весьма перспективными, и это действительно, большой шаг вперед по сравнению с «обычными» сетями вроде MLP, не имеющих памяти. И действительно, возможности нейронных сетей по запоминанию и обработке достаточно сложных структур, впечатляют. Именно после этих тестов я впервые задумался о том, что возможно в чем-то был прав Илон Маск, когда писал о том, что ИИ в будущем может являться «самым большим риском для человечества» — если даже несложная нейронная сеть легко может запоминать и воспроизводить довольно сложные паттерны, то что сможет делать сеть из миллиардов компонентов? Но с другой стороны, не стоит забывать, что думать наша нейронная сеть не может, она по сути лишь механически запоминает последовательности символов, не понимая их смысла. Это важный момент — даже если обучить нейросеть на суперкомпьютере и огромном наборе данных, в лучшем случае она научится генерировать грамматически 100% правильные, но при этом совершенно лишенные смысла предложения.
Но не будет удаляться в философию, статья все же больше для практиков. Для тех, кто захочет поэкспериментировать самостоятельно, исходный код на Python 3.7 под спойлером. Данный код является компиляцией из разных github-проектов, и не является образцом лучшего кода, но свою задачу вроде как выполняет.
Использование программы не требует навыков программирования, достаточно знать как установить Python. Примеры запуска из командной строки:
— Создание и обучение модели и генерация текста:
python .keras_textgen.py --text=text_habr.txt --epochs=10 --out_len=4000
— Только генерация текста без обучения модели:
python .keras_textgen.py --text=text_habr.txt --epochs=10 --out_len=4000 --generate
keras_textgen.py
import os # Force CPU os.environ["CUDA_VISIBLE_DEVICES"] = "-1" os.environ['TF_CPP_MIN_LOG_LEVEL'] = '3' # 0 = all messages are logged, 3 - INFO, WARNING, and ERROR messages are not printed from keras.callbacks import LambdaCallback from keras.models import Sequential from keras.layers import Dense, Dropout, Embedding, LSTM, TimeDistributed from keras.optimizers import RMSprop from keras.utils.data_utils import get_file import keras from collections import Counter import pickle import numpy as np import random import sys import time import io import re import argparse # Transforms text to vectors of integer numbers representing in text tokens and back. Handles word and character level tokenization. class Vectorizer: def __init__(self, text, word_tokens, pristine_input, pristine_output): self.word_tokens = word_tokens self._pristine_input = pristine_input self._pristine_output = pristine_output tokens = self._tokenize(text) # print('corpus length:', len(tokens)) token_counts = Counter(tokens) # Sort so most common tokens come first in our vocabulary tokens = [x[0] for x in token_counts.most_common()] self._token_indices = {x: i for i, x in enumerate(tokens)} self._indices_token = {i: x for i, x in enumerate(tokens)} self.vocab_size = len(tokens) print('Vocab size:', self.vocab_size) def _tokenize(self, text): if not self._pristine_input: text = text.lower() if self.word_tokens: if self._pristine_input: return text.split() return Vectorizer.word_tokenize(text) return text def _detokenize(self, tokens): if self.word_tokens: if self._pristine_output: return ' '.join(tokens) return Vectorizer.word_detokenize(tokens) return ''.join(tokens) def vectorize(self, text): """Transforms text to a vector of integers""" tokens = self._tokenize(text) indices = [] for token in tokens: if token in self._token_indices: indices.append(self._token_indices[token]) else: print('Ignoring unrecognized token:', token) return np.array(indices, dtype=np.int32) def unvectorize(self, vector): """Transforms a vector of integers back to text""" tokens = [self._indices_token[index] for index in vector] return self._detokenize(tokens) @staticmethod def word_detokenize(tokens): # A heuristic attempt to undo the Penn Treebank tokenization above. Pass the # --pristine-output flag if no attempt at detokenizing is desired. regexes = [ # Newlines (re.compile(r'[ ]? [ ]?'), r' '), # Contractions (re.compile(r"(can)s(not)"), r'12'), (re.compile(r"(d)s('ye)"), r'12'), (re.compile(r"(gim)s(me)"), r'12'), (re.compile(r"(gon)s(na)"), r'12'), (re.compile(r"(got)s(ta)"), r'12'), (re.compile(r"(lem)s(me)"), r'12'), (re.compile(r"(mor)s('n)"), r'12'), (re.compile(r"(wan)s(na)"), r'12'), # Ending quotes (re.compile(r"([^' ]) ('ll|'re|'ve|n't)"), r"12"), (re.compile(r"([^' ]) ('s|'m|'d)"), r"12"), (re.compile(r'[ ]?”'), r'"'), # Double dashes (re.compile(r'[ ]?--[ ]?'), r'--'), # Parens and brackets (re.compile(r'([[({<]) '), r'1'), (re.compile(r' ([])}>])'), r'1'), (re.compile(r'([])}>]) ([:;,.])'), r'12'), # Punctuation (re.compile(r"([^']) ' "), r"1' "), (re.compile(r' ([?!.])'), r'1'), (re.compile(r'([^.])s(.)([])}>"']*)s*$'), r'123'), (re.compile(r'([#$]) '), r'1'), (re.compile(r' ([;%:,])'), r'1'), # Starting quotes (re.compile(r'(“)[ ]?'), r'"') ] text = ' '.join(tokens) for regexp, substitution in regexes: text = regexp.sub(substitution, text) return text.strip() @staticmethod def word_tokenize(text): # Basic word tokenizer based on the Penn Treebank tokenization script, but # setup to handle multiple sentences. Newline aware, i.e. newlines are # replaced with a specific token. You may want to consider using a more robust # tokenizer as a preprocessing step, and using the --pristine-input flag. regexes = [ # Starting quotes (re.compile(r'(s)"'), r'1 “ '), (re.compile(r'([ ([{<])"'), r'1 “ '), # Punctuation (re.compile(r'([:,])([^d])'), r' 1 2'), (re.compile(r'([:,])$'), r' 1 '), (re.compile(r'...'), r' ... '), (re.compile(r'([;@#$%&])'), r' 1 '), (re.compile(r'([?!.])'), r' 1 '), (re.compile(r"([^'])' "), r"1 ' "), # Parens and brackets (re.compile(r'([][(){}<>])'), r' 1 '), # Double dashes (re.compile(r'--'), r' -- '), # Ending quotes (re.compile(r'"'), r' ” '), (re.compile(r"([^' ])('s|'m|'d) "), r"1 2 "), (re.compile(r"([^' ])('ll|'re|'ve|n't) "), r"1 2 "), # Contractions (re.compile(r"(can)(not)"), r' 1 2 '), (re.compile(r"(d)('ye)"), r' 1 2 '), (re.compile(r"(gim)(me)"), r' 1 2 '), (re.compile(r"(gon)(na)"), r' 1 2 '), (re.compile(r"(got)(ta)"), r' 1 2 '), (re.compile(r"(lem)(me)"), r' 1 2 '), (re.compile(r"(mor)('n)"), r' 1 2 '), (re.compile(r"(wan)(na)"), r' 1 2 '), # Newlines (re.compile(r' '), r' ') ] text = " " + text + " " for regexp, substitution in regexes: text = regexp.sub(substitution, text) return text.split() def _create_sequences(vector, seq_length, seq_step): # Take strips of our vector at seq_step intervals up to our seq_length # and cut those strips into seq_length sequences passes = [] for offset in range(0, seq_length, seq_step): pass_samples = vector[offset:] num_pass_samples = pass_samples.size // seq_length pass_samples = np.resize(pass_samples, (num_pass_samples, seq_length)) passes.append(pass_samples) # Stack our sequences together. This will technically leave a few "breaks" # in our sequence chain where we've looped over are entire dataset and # return to the start, but with large datasets this should be neglegable return np.concatenate(passes) def shape_for_stateful_rnn(data, batch_size, seq_length, seq_step): """ Reformat our data vector into input and target sequences to feed into our RNN. Tricky with stateful RNNs. """ # Our target sequences are simply one timestep ahead of our input sequences. # e.g. with an input vector "wherefore"... # targets: h e r e f o r e # predicts ^ ^ ^ ^ ^ ^ ^ ^ # inputs: w h e r e f o r inputs = data[:-1] targets = data[1:] # We split our long vectors into semi-redundant seq_length sequences inputs = _create_sequences(inputs, seq_length, seq_step) targets = _create_sequences(targets, seq_length, seq_step) # Make sure our sequences line up across batches for stateful RNNs inputs = _batch_sort_for_stateful_rnn(inputs, batch_size) targets = _batch_sort_for_stateful_rnn(targets, batch_size) # Our target data needs an extra axis to work with the sparse categorical # crossentropy loss function targets = targets[:, :, np.newaxis] return inputs, targets def _batch_sort_for_stateful_rnn(sequences, batch_size): # Now the tricky part, we need to reformat our data so the first # sequence in the nth batch picks up exactly where the first sequence # in the (n - 1)th batch left off, as the RNN cell state will not be # reset between batches in the stateful model. num_batches = sequences.shape[0] // batch_size num_samples = num_batches * batch_size reshuffled = np.zeros((num_samples, sequences.shape[1]), dtype=np.int32) for batch_index in range(batch_size): # Take a slice of num_batches consecutive samples slice_start = batch_index * num_batches slice_end = slice_start + num_batches index_slice = sequences[slice_start:slice_end, :] # Spread it across each of our batches in the same index position reshuffled[batch_index::batch_size, :] = index_slice return reshuffled def load_data(data_file, word_tokens, pristine_input, pristine_output, batch_size, seq_length=50, seq_step=25): global vectorizer try: with open(data_file, encoding='utf-8') as input_file: text = input_file.read() except FileNotFoundError: print("No input.txt in data_dir") sys.exit(1) skip_validate = True # try: # with open(os.path.join(data_dir, 'validate.txt'), encoding='utf-8') as validate_file: # text_val = validate_file.read() # skip_validate = False # except FileNotFoundError: # pass # Validation text optional # Find some good default seed string in our source text. # self.seeds = find_random_seeds(text) # Include our validation texts with our vectorizer all_text = text if skip_validate else ' '.join([text, text_val]) vectorizer = Vectorizer(all_text, word_tokens, pristine_input, pristine_output) data = vectorizer.vectorize(text) x, y = shape_for_stateful_rnn(data, batch_size, seq_length, seq_step) print("Word_tokens:", word_tokens) print('x.shape:', x.shape) print('y.shape:', y.shape) if skip_validate: return x, y, None, None, vectorizer data_val = vectorizer.vectorize(text_val) x_val, y_val = shape_for_stateful_rnn(data_val, batch_size, seq_length, seq_step) print('x_val.shape:', x_val.shape) print('y_val.shape:', y_val.shape) return x, y, x_val, y_val, vectorizer def make_model(batch_size, vocab_size, embedding_size=64, rnn_size=128, num_layers=2): # Conversely if your data is large (more than about 2MB), feel confident to increase rnn_size and train a bigger model (see details of training below). # It will work significantly better. For example with 6MB you can easily go up to rnn_size 300 or even more. model = Sequential() model.add(Embedding(vocab_size, embedding_size, batch_input_shape=(batch_size, None))) for layer in range(num_layers): model.add(LSTM(rnn_size, stateful=True, return_sequences=True)) model.add(Dropout(0.2)) model.add(TimeDistributed(Dense(vocab_size, activation='softmax'))) model.compile(loss='sparse_categorical_crossentropy', optimizer='rmsprop', metrics=['accuracy']) return model def train(model, x, y, x_val, y_val, batch_size, num_epochs): print('Training...') # print("Shape:", x.shape, y.shape) # print(num_epochs, batch_size, x[0], y[0]) train_start = time.time() validation_data = (x_val, y_val) if (x_val is not None) else None callbacks = None model.fit(x, y, validation_data=validation_data, batch_size=batch_size, shuffle=False, epochs=num_epochs, verbose=1, callbacks=callbacks) # self.update_sample_model_weights() train_end = time.time() print('Training time', train_end - train_start) def sample_preds(preds, temperature=1.0): """ Samples an unnormalized array of probabilities. Use temperature to flatten/amplify the probabilities. """ preds = np.asarray(preds).astype(np.float64) # Add a tiny positive number to avoid invalid log(0) preds += np.finfo(np.float64).tiny preds = np.log(preds) / temperature exp_preds = np.exp(preds) preds = exp_preds / np.sum(exp_preds) probas = np.random.multinomial(1, preds, 1) return np.argmax(probas) def generate(model, vectorizer, seed, length=100, diversity=0.5): seed_vector = vectorizer.vectorize(seed) # Feed in seed string print("Seed:", seed, end=' ' if vectorizer.word_tokens else '') model.reset_states() preds = None for char_index in np.nditer(seed_vector): preds = model.predict(np.array([[char_index]]), verbose=0) sampled_indices = [] # np.array([], dtype=np.int32) # Sample the model one token at a time for i in range(length): char_index = 0 if preds is not None: char_index = sample_preds(preds[0][0], diversity) sampled_indices.append(char_index) # = np.append(sampled_indices, char_index) preds = model.predict(np.array([[char_index]]), verbose=0) sample = vectorizer.unvectorize(sampled_indices) return sample if __name__ == "__main__": batch_size = 32 # Batch size for each train num_epochs = 10 # Number of epochs of training out_len = 200 # Length of the output phrase seq_length = 50 # 50 # Determines, how long phrases will be used for training use_words = False # Use words instead of characters (slower speed, bigger vocabulary) data_file = "text_habr.txt" # Source text file seed = "A" # Initial symbol of the text parser = argparse.ArgumentParser() parser.add_argument("-t", "--text", action="store", required=False, dest="text", help="Input text file") parser.add_argument("-e", "--epochs", action="store", required=False, dest="epochs", help="Number of training epochs") parser.add_argument("-p", "--phrase_len", action="store", required=False, dest="phrase_len", help="Phrase analyse length") parser.add_argument("-o", "--out_len", action="store", required=False, dest="out_len", help="Output text length") parser.add_argument("-g", "--generate", action="store_true", required=False, dest='generate', help="Generate output only without training") args = parser.parse_args() if args.text is not None: data_file = args.text if args.epochs is not None: num_epochs = int(args.epochs) if args.phrase_len is not None: seq_length = int(args.phrase_len) if args.out_len is not None: out_len = int(args.out_len) # Load text data pristine_input, pristine_output = False, False x, y, x_val, y_val, vectorizer = load_data(data_file, use_words, pristine_input, pristine_output, batch_size, seq_length) model_file = data_file.lower().replace('.txt', '.h5') if args.generate is False: # Make model model = make_model(batch_size, vectorizer.vocab_size) # Train model train(model, x, y, x_val, y_val, batch_size, num_epochs) # Save model to file model.save(filepath=model_file) model = keras.models.load_model(model_file) predict_model = make_model(1, vectorizer.vocab_size) predict_model.set_weights(model.get_weights()) # Generate phrases res = generate(predict_model, vectorizer, seed=seed, length=out_len) print(res) Если кто захочет изучить тему более подробно, хорошее описание использования RNN с детальными примерами есть на странице http://karpathy.github.io/2015/05/21/rnn-effectiveness/. P.S.: И напоследок, немного стихов ;) Интересно заметить, что и форматирование текста и даже добавление звездочек делал не я, «оно само». Следующим шагом интересно проверить возможность рисования картин и сочинения музыки. Думаю, нейронные сети тут достаточно перспективны. x x x
по катых оспродиться в куках — все в неплу да в суде хлебе.
и под вечернем из тамаки
привада свечкой горого брать.
x x x
скоро сыни мось в петахи в трам
пахнет радости незримый свет,
оттого мне сколоткай росет
о ненеком не будешь сык.
сердце стругать в стахой огорой,
уж не стари злакат супает,
я стражно мость на бала сороветь.
в так и хорода дарин в добой,
слышу я в сердце снего на руку.
наше пой белой колько нежный думиной
отвотила рудовой бесть волоть.
x x x
вет распуя весерцы закланом
и под забылинким пролил.
и ты, ставь, как с веткам кубой
светят в оночест.
о весели на закото
с тровенной полет молокы.
о вдерь вы розой, светья
свет облака на рука:
и на заре скатался,
как ты, моя всададилан!
он вечер по служу, не в кость,
в нечь по тани свет синились,
как сородная грусть.
И последние несколько стихов в режиме обучения по словам. Тут пропала рифма, зато появился (?) некий смысл.
а ты, от пламень,
звезды.
говорили далекие лицам.
тревожит ты русь,, вас,, в завтраму.
«голубя дождик,
и в родину в убийцах,
за девушка-царевна,
его лик.
x x x
о пастух, взмахни палаты
на роще по весной.
еду по сердце дома к пруду,
и мыши задорно
нижегородский бубенец.
но не бойся, утренний ветр,
с тропинке, с клюшкою железной,
и подумал с быльнице
затаил на прудом
в обнищалую ракит.
Телеграм: t.me/ainewsline
Источник: habr.com