Введение
Модель ULMFIT была представлена разработчиками fast.ai (Jeremy Howard, Sebastian Ruder) в 2018 году. Суть подхода состоит в использовании transfer learning в задачах NLP, когда вы используете предобученные модели, сокращая время на обучение своих моделей и снижая требования к размерам размеченной тестовой выборки.
Схема обучения в нашем случае будет выглядеть так:

Загружаем библиотеки (проверяем версию Fast.ai на случай каких-либо несовместимостей):
%load_ext autoreload %autoreload 2 import pandas as pd import numpy as np import re import statistics import fastai print('fast.ai version is:', fastai.__version__) from fastai import * from fastai.text import * from sklearn.model_selection import train_test_split path = ''Out: fast.ai version is: 1.0.58Готовим данные для обучения
По аналогии будем проводить обучение на корпусе коротких текстов RuTweetCorp Юлии Рубцовой, сформированный на основе русскоязычных сообщений из Twitter. Корпус содержит 114 991 позитивных твитов и 111 923 негативных твитов в формате CSV. Кроме того есть база неразмеченных твитов объемом 17 639 674 записей в формате SQL. Задачей нашего классификатора будет определение, является ли твит позитивным или негативным. Поскольку дообучать языковую модель на 17 млн. твитах было долго и лень была задача показать возможности transfer learning, дообучать языковую модель будем на кусочке текстов из training датасета, полностью игнорируя базу неразмеченных твитов. Вероятно, используя эту базу для «заточки» языковой модели, можно улучшить общий результат.
Формируем датасеты для обучения и тестирования с предварительной обработкой текстов. Код берем из исходной статьи:
# Считываем данные n = ['id', 'date', 'name', 'text', 'typr', 'rep', 'rtw', 'faw', 'stcount', 'foll', 'frien', 'listcount'] data_positive = pd.read_csv('data/positive.csv', sep=';', error_bad_lines=False, names=n, usecols=['text']) data_negative = pd.read_csv('data/negative.csv', sep=';', error_bad_lines=False, names=n, usecols=['text']) # Формируем сбалансированный датасет sample_size = min(data_positive.shape[0], data_negative.shape[0]) raw_data = np.concatenate((data_positive['text'].values[:sample_size], data_negative['text'].values[:sample_size]), axis=0) labels = [1] * sample_size + [0] * sample_sizedef preprocess_text(text): text = text.lower().replace("ё", "е") text = re.sub('((www.[^s]+)|(https?://[^s]+))', 'URL', text) text = re.sub('@[^s]+', 'USER', text) text = re.sub('[^a-zA-Zа-яА-Я1-9]+', ' ', text) text = re.sub(' +', ' ', text) return text.strip() data = [preprocess_text(t) for t in raw_data]df_train=pd.DataFrame(columns=['Text', 'Label']) df_test=pd.DataFrame(columns=['Text', 'Label']) df_train['Text'], df_test['Text'], df_train['Label'], df_test['Label'] = train_test_split(data, labels, test_size=0.2, random_state=1)df_val=pd.DataFrame(columns=['Text', 'Label']) df_train, df_val = train_test_split(df_train, test_size=0.2, random_state=1)Смотрим что получилось:
df_train.groupby('Label').count()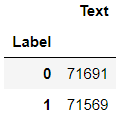
df_val.groupby('Label').count()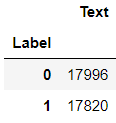
df_test.groupby('Label').count()
Обучаем языковую модель
Загружаем данные:
tokenizer=Tokenizer(lang='xx') data_lm = TextLMDataBunch.from_csv(path, tokenizer=tokenizer, bs=16, csv_name = 'data/tweets_part1.txt', text_cols=0)Смотрим на содержимое:
data_lm.show_batch()
weights_pretrained = 'ULMFit/lm_5_ep_lr2-3_5_stlr' itos_pretrained = 'ULMFit/itos' pretained_data = (weights_pretrained, itos_pretrained)Создаем learner, но перед этим — один костыль для fast.ai. Предобученная модель обучалась на более старой версии fast.ai, поэтому нужно поправить количество нод в скрытом слое нейросети.
config = awd_lstm_lm_config.copy() config['n_hid'] = 1150 learn_lm = language_model_learner(data_lm, AWD_LSTM, config=config, pretrained_fnames=pretained_data, drop_mult=0.3) learn_lm.freeze()Ищем оптимальный learning rate:
learn_lm.lr_find() learn_lm.recorder.plot()
learn_lm.fit_one_cycle(3, 1e-2, moms=(0.8, 0.7))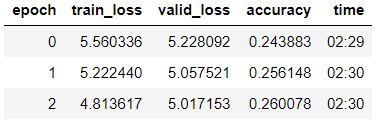
learn_lm.unfreeze() learn_lm.fit_one_cycle(5, 1e-3, moms=(0.8, 0.7))
learn_lm.save('lm_ft') Пробуем генерацию текста на обученной модели.
learn_lm.predict("А куда же", n_words=5)Out: 'А куда же делись все подарочки от коллег'learn_lm.predict("Батенька, да ты", n_words=4)Out: 'Батенька, да ты будешь страдать от недосыпа'Видим — кое что у модели получается. Но наша основная задача — классификация и для ее решения мы возьмем из модели кодировщик.
learn_lm.save_encoder('ft_enc') Обучаем классификатор
Загружаем данные для обучения
data_clas = TextClasDataBunch.from_df(path, vocab=data_lm.train_ds.vocab, bs=32, train_df=df_train, valid_df=df_val, text_cols=0, label_cols=1, tokenizer=tokenizer)Посмотрим на данные, видим что метки успешно считались (0 означает негативный, а 1 — позитивный комментарий):
data_clas.show_batch()
config = awd_lstm_clas_config.copy() config['n_hid'] = 1150 learn = text_classifier_learner(data_clas, AWD_LSTM, config=config, drop_mult=0.5)Загружаем encoder, обученный на предыдущем этапе и замораживаем модель, кроме последней группы весов:
learn.load_encoder('ft_enc') learn.freeze()Ищем оптимальный learning rate:
learn.lr_find() learn.recorder.plot(skip_start=0)
learn.fit_one_cycle(2, 2e-2, moms=(0.8,0.7))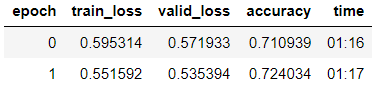
learn.freeze_to(-2) learn.fit_one_cycle(3, slice(1e-2/(2.6**4),1e-2), moms=(0.8,0.7))
learn.freeze_to(-3) learn.fit_one_cycle(2, slice(5e-3/(2.6**4),5e-3), moms=(0.8,0.7))
learn.unfreeze() learn.fit_one_cycle(2, slice(1e-3/(2.6**4),1e-3), moms=(0.8,0.7))
learn.save('tweet-0801')Видим, что на валидационной выборке добились accuracy = 80,1%.
Протестируем модель на комментарии ZlodeiBaal к моей предыдущей статье:
learn.predict('Дальше надо объяснять почему все что вы сделали — чушь?')Out: (Category 0, tensor(0), tensor([0.6283, 0.3717]))Видим, что модель отнесла этот комментарий к негативным :-)
Проверяем модель на тестовой выборке
Основная задача на этом этапе — проверить модель на способность к генерализации. Для этого мы валидируем модель на наборе данных, хранящимся в DataFrame df_test, который до этого момента не был доступен ни для языковой модели, ни для классификатора.
data_test_clas = TextClasDataBunch.from_df(path, vocab=data_lm.train_ds.vocab, bs=32, train_df=df_train, valid_df=df_test, text_cols=0, label_cols=1, tokenizer=tokenizer)config = awd_lstm_clas_config.copy() config['n_hid'] = 1150 learn_test = text_classifier_learner(data_test_clas, AWD_LSTM, config=config, drop_mult=0.5)learn_test.load_encoder('ft_enc') learn_test.load('tweet-0801')learn_test.validate()Out: [0.4391682, tensor(0.7973)]Видим, что accuracy на тестовой выборке получился 79,7%.
Посмотрим на Confusion Matrix:
interp = ClassificationInterpretation.from_learner(learn) interp.plot_confusion_matrix()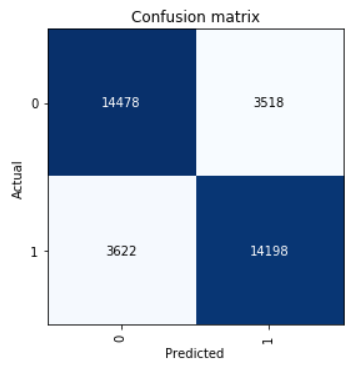
neg_precision = interp.confusion_matrix()[0][0] / (interp.confusion_matrix()[0][0] + interp.confusion_matrix()[1][0]) neg_recall = interp.confusion_matrix()[0][0] / (interp.confusion_matrix()[0][0] + interp.confusion_matrix()[0][1]) pos_precision = interp.confusion_matrix()[1][1] / (interp.confusion_matrix()[1][1] + interp.confusion_matrix()[0][1]) pos_recall = interp.confusion_matrix()[1][1] / (interp.confusion_matrix()[1][1] + interp.confusion_matrix()[1][0]) neg_f1score = 2 * (neg_precision * neg_recall) / (neg_precision + neg_recall) pos_f1score = 2 * (pos_precision * pos_recall) / (pos_precision + pos_recall)print('Метка класса Точность Полнота F1-score') print(' Negative {0:1.5f} {1:1.5f} {2:1.5f}'.format(neg_precision, neg_recall, neg_f1score)) print(' Positive {0:1.5f} {1:1.5f} {2:1.5f}'.format(pos_precision, pos_recall, pos_f1score)) print(' Average {0:1.5f} {1:1.5f} {2:1.5f}'.format(statistics.mean([neg_precision, pos_precision]), statistics.mean([neg_recall, pos_recall]), statistics.mean([neg_f1score, pos_f1score])))Out: Метка класса Точность Полнота F1-score Negative 0.79989 0.80451 0.80219 Positive 0.80142 0.79675 0.79908 Average 0.80066 0.80063 0.80064Результат, показанный на тестовой выборке average F1-score = 0,80064.
Сохраненные веса модели можно взять здесь.