Устойчивый нейронный машинный перевод
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2019-09-05 10:54
“Der Sprecher des Untersuchungsausschusses hat angek?ndigt, vor Gericht zu ziehen, falls sich die geladenen Zeugen weiterhin weigern sollten, eine Aussage zu machen.”Однако при внесении небольшого изменения во входящее предложение, заменив слово geladenen на синоним vorgeladenen, перевод резко меняется (и становится неверным):
(Машинный перевод: “The spokesman of the Committee of Inquiry has announced that if the witnesses summoned continue to refuse to testify, he will be brought to court.”)
Перевод: представитель следственного комитета объявил, что если приглашённые свидетели будут и дальше отказываться давать показания, его привлекут к ответственности.
“Der Sprecher des Untersuchungsausschusses hat angek?ndigt, vor Gericht zu ziehen, falls sich die vorgeladenen Zeugen weiterhin weigern sollten, eine Aussage zu machen.”Отсутствие устойчивости у НМП-моделей не даёт применять коммерческие системы к задачам, в которых недопустим подобный уровень нестабильности. Поэтому наличие обучающихся устойчивых переводящих моделей не просто желаемо, но часто и просто необходимо. При этом, хотя устойчивость нейросетей активно изучается сообществом исследователей компьютерного зрения, материалов по устойчивым обучающимся НМП-моделям можно найти немного.
(Машинный перевод: “The investigative committee has announced that he will be brought to justice if the witnesses who have been invited continue to refuse to testify.”).
Перевод: следственный комитет объявил, что его привлекут к правосудию, если приглашённые свидетели будут и дальше отказываться давать показания.
В нашей работе «Устойчивый машинный перевод с двойным состязательным вводом» мы предлагаем подход, использующий сгенерированные состязательные примеры для улучшения стабильности моделей машинного перевода к небольшим изменениям входа. Мы обучаем устойчивую НМП-модель преодолевать состязательные примеры, сгенерированные с учётом знаний об этой модели и в целях искажения её предсказаний. Мы показываем, что такой подход улучшает эффективность НМП-модели на стандартных тестах.
Обучение модели при помощи AdvGen
Идеальная НМП-модель должна генерировать похожие переводы для разных входов, имеющих небольшие отличия. Идея нашего подхода – мешать модели перевода при помощи состязательных входных данных в надежде увеличения её устойчивости. Это происходит при помощи алгоритма «состязательной генерации» (Adversarial Generation, AdvGen), генерирующего допустимые состязательные примеры, мешающие модели, а потом скармливающего их в модель для обучения. Хотя этот метод вдохновлён идеей генеративных состязательных сетей (ГСС), он не использует сеть-дискриминатор, а просто применяет состязательный пример в обучении, по сути, диверсифицируя и расширяя обучающий набор.
Первый шаг – внести возмущение в данные при помощи AdvGen. Начинаем мы с того, что используем трансформер для подсчёта потери перевода на основе исходного входящего предложения, целевого входного предложения и целевого выходного предложения. Затем AdvGen случайным образом выбирает слова в исходном предложении, действуя в предположении об их равномерном распределении. У каждого слова есть соответствующий ему список похожих слов, т.е. кандидатов на подстановку. Из него AdvGen выбирает слово, которое с наибольшей вероятностью приведёт к ошибкам в выходе трансформера. Затем это сгенерированное состязательное предложение скармливается обратно в трансформер, запуская стадию защиты.
 Сначала модель трансформера применяется ко входящему предложению (слева внизу), и затем подсчитывается потеря перевода совместно с целевым выходным предложением (выше вверху) и целевым входным предложением (в середине справа, начиная с “<sos>”). Затем AdvGen принимает исходное предложение, распределение выбора слов, кандидаты для слов, и потери перевода в качестве входных данных и создаёт пример состязательного исходного текста.
Сначала модель трансформера применяется ко входящему предложению (слева внизу), и затем подсчитывается потеря перевода совместно с целевым выходным предложением (выше вверху) и целевым входным предложением (в середине справа, начиная с “<sos>”). Затем AdvGen принимает исходное предложение, распределение выбора слов, кандидаты для слов, и потери перевода в качестве входных данных и создаёт пример состязательного исходного текста.
На этапе защиты состязательный исходный текст скармливается обратно в трансформер. Снова подсчитывается потеря перевода, но на этот раз уже с использованием состязательного входного исходника. Используя такой же метод, что и ранее, AdvGen использует целевое входящее предложение, распределение выбора слов, подсчитанное из матрицы внимания, кандидаты для замены слов, и потери перевода для создания примера состязательного исходного текста.
![]() На этапе защиты состязательный исходный текст становится входом для трансформера, и подсчитываются потери перевода. Используя такой же метод, что и ранее, AdvGen создаёт пример состязательного исходного текста на основе целевого входа.
На этапе защиты состязательный исходный текст становится входом для трансформера, и подсчитываются потери перевода. Используя такой же метод, что и ранее, AdvGen создаёт пример состязательного исходного текста на основе целевого входа.
Наконец, состязательное предложение скармливается обратно в трансформер, и подсчитываются потеря устойчивости на основе примера состязательного исходника, состязательного примера целевого входа и целевого предложения. Если вмешательство в текст привело к значительным потерям, они минимизируются так, чтобы, когда модели встречаются сходные возмущения, она не повторяла такой же ошибки. С другой стороны, если возмущение приводит к небольшим потерям, ничего не происходит, что говорит о том, что модель уже способна справляться с подобными возмущениями.
Эффективность работы модели
Мы демонстрируем эффективность нашего подхода, применяя его к стандартным тестам переводов с китайского на английский и с английского на немецкий. Мы получаем значительное улучшение перевода на 2,8 и 1,6 пунктов BLEU соответственно, по сравнению с конкурирующей моделью трансформера, и достигаем нового рекордного качества перевода.

Затем мы оцениваем работу нашей модели на зашумлённом наборе данных при помощи процедуры, сходной с той, что описана для AdvGen. Мы берём чистые входные данные, к примеру, такие, которые используются в стандартных тестах переводчиков, и случайным образом выбираем слова, которые заменяем на похожие. Мы обнаруживаем, что наша модель демонстрирует улучшенную устойчивость по сравнению с другими недавними моделями.
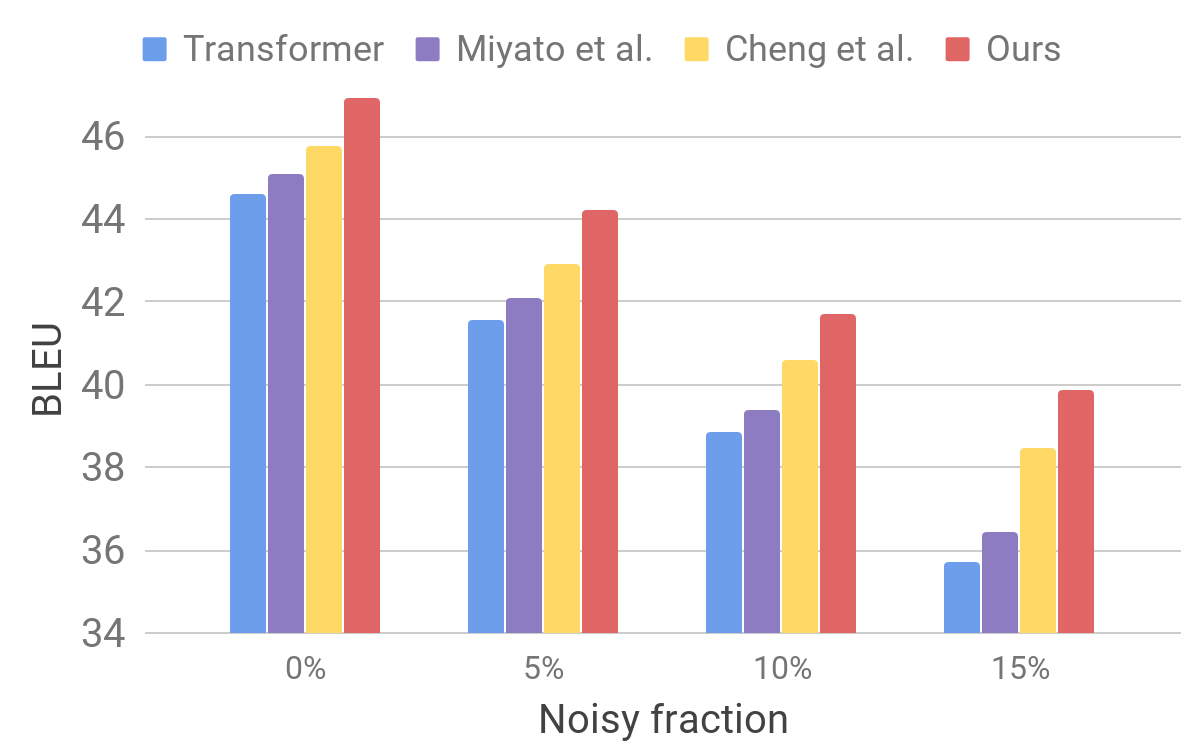
Эти результаты показывают, что наши методы способны преодолеть небольшие возмущения, возникающие во входящем предложении, и улучшить эффективность обобщения. Он опережает конкурирующие модели перевода и достигает рекордной эффективности перевода на стандартных тестах. Мы надеемся, что наша модель переводчика станет устойчивой основой для улучшения результатов решения многих следующих задач, особенно чувствительных или нетерпимых к неидеальным входным текстам.
Телеграм: t.me/ainewsline
Источник: habr.com