Ультимативное сравнение embedded платформ для AI
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2019-09-25 03:56
Замечательные фреймворки. Что PyTorch, что второй TensorFlow. Всё становиться удобнее и удобнее, проще и проще…
Но есть одна тёмная сторона. Про неё стараются молчать. Там нет ничего радостного, только тьма и отчаяние. Каждый раз когда видишь позитивную статью — грустно вздыхаешь, так как понимаешь что просто человек что-то не понял. Или скрыл.
Давайте поговорим про продакшн на embedded-устройствах.

В чём проблема.
Казалось бы. Посмотри производительность устройства, убедись что её достаточно, запусти и получай профит.
Но, как всегда, есть пара нюансов. Давайте разложим их по полкам:
- Production. Если ваше устройство делается не в единичных экземплярах, тогда надо быть уверенным что система не зависнет, что устройства не будут перегреваться, что при пропадании питания всё автоматически загрузится. И это на большой партии. Это даёт лишь два варианта — либо устройство должно быть полностью разработано с учётом всех возможных проблем. Либо надо побороть проблемы исходного устройства. Ну, например вот такие (1, 2 ). Что, понятно, жесть. Чтобы решить проблемы чужого устройства на больших партиях надо потратить нереальный объём сил.
- Реальные бэнчмарки. Очень много жульничества и хитрости. NVIDIA в большинстве примеров завышает производительность на 30-40%. Но не только она этим развлекается. Ниже я привожу много примеров когда производительность может быть в 4-5 раз меньше чем хочешь. Нельзя закладываться “на компе всё хорошо работало, тут будет пропорционально хуже”.
- Очень ограниченная поддержка архитектуры нейронных сетей. Есть много аппаратных embedded платформ которые очень сильно ограничивают сети которые можно на них запустить (Coral, gyrfalcone, snapdragon). Портирование на такие платформы будет вызывать боль.
- Поддержка. У вас что-то не работает, а проблема на стороне устройства?.. Это судьба, оно и не будет работать. Только для RPi комьюнити затыкает большую часть багов. И, частично, для Jetson.
- Цена. Многим кажется что embedded это дёшево. Но, в реальности, с ростом производительности устройства, цена будет расти почти экспоненциально. RPi-4 в 5 раз дешевле Jetson Nano/Google Coral и в 2-3 раза слабее. Jetson Nano в 5 раз дешевле Jetson TX2/Intel NUC, и в 2-3 раза слабее их.
- Лоргус. Помните такую конструкцию из Желязны?
Кажется именно его я поставил в качестве титульной картинки...“the Logrus is a shifting, three-dimensional maze which represents the forces of Chaos in the multiverse”.Тут так же. Всё это обилие багов и дыр, все эти разномастные железки, все меняющиеся фреймворки… Это нормально когда за 2-3 месяца картина рынка полностью меняется. За этот год она поменялась 3-4 раза. Нельзя войти в одну и ту же реку дважды. Так что все текущие мысли справедливы примерно на лето 2019 года.
Что есть
Разберём по порядку, на вкус он не сладкий… Что сейчас вообще есть и пригодно для нейронок? Вариантов, не смотря на их изменчивость, не так уж и много. Несколько общих слов, чтобы оограничить перебор:
- Я не буду разбирать нейронки/инференс на телефонах. Это сама по себе огромная тема. Но так как телефоны это embedded платформы лишь с натягом, не думаю что это плохо.
- Я затрону Jetson TX1|TX2. В нынешних условиях это не самые оптимальные из платформ по цене, но есть ситуации когда их всё же удобно использовать.
- Я не гарантирую что в списке будут все платформы которые существуют сегодня. Может что-то забыл, может про что-то не знаю. Если знаете ещё интересные платформы — пишите!
Итак. Основные вещи, которые явно Embeding. В статье мы будем сравнивать именно их:

- Платформа Jetson. Для неё есть несколько устройств:
- Jetson Nano — дешевая и достаточно современная (весна 2019г.) игрушка
- Jetson Tx1|Tx2 — достаточно дорогие но хорошие по производительности и универсальности платформы
- Raspberry Pi. Реально для нейронных сеток сейчас производительность есть лишь у RPi4. Но какие-то отдельные задачки можно и на третьем поколении делать. Совсем простые сетки я даже на первом пускал.
- Платформа Google Coral. По сути для embeding устройств там есть только один чип и два девайса — Dev Board и USB Accelerator
- Платформа Intel Movidius. Если вы не огромная компания, то для вас будут доступны только стики Movidius 1|Movidius 2.
- Платформа Gyrfalcone. Чудо китайских технологий. Есть уже два поколения — 2801, 2803
Прочее. Про них поговорим после основных сравнений:
- Intel процессоры. В первую очередь сборки NUC.Почти embedding
- Nvidia мобильные GPU. Готовые решения, можно считать, не embedding. А если собирать embedding, то получиться прилично по финансам.
- Мобильники. Android характерен тем что для использования максимума производительности надо использовать по максимуму именно то железо которое у конкретного производителя. Или использовать что-то универсальное, такое как tensorflow light. Для Apple то же самое.
- Jetson AGX Xavier — дорогая версия Jetson с большей производительностью.
- GAP8 — низкопотребляющие процессоры для супердешёвых устройств.
- Загадочный Grove AI HAT
Jetson
С Jetson мы работаем очень долго. Ещё в 2014 году Vasyutka придумал математику для тогдашнего Стрижа именно на Jetson. В 2015 году на встрече с Artec 3D мы рассказали о том какая это классная платформа, после чего они предложили нам собрать прототип на его базе. Через пару месяцев прототип был готов. Ещё пара лет работы всей фирмы, пару лет проклятий проклятий в адрес платформы и в адрес небес… И родился Artec Leo — самый классный сканер в своём классе. Даже Nvidia на презентации TX2 показывала его как один из самых интересных проектов созданных на платформе. С тех пор TX1/TX2/Nano мы использовали где-то в 5-6 проектах. И, наверное, знаем все проблемы которые были с платформой. Давайте разберём по порядку.
Jetson TK1
Про него особо говорить не буду. Платформа была очень эффективная по вычислительной мощности на свой день. Но она не была продуктовой. NVIDIA продавала чипы TegraTK1, который лежал в основе Jetson. Но эти чипы было невозможно использовать мелким и средним производителям. Реально что-то на них смогли сделать кроме Nvidia только Google/HTC/Xiaomi/Acer/Google. Все остальные интегрировали в прод либо отладочные платы, либо мародерствовали другие устройства.
Jetson TX1|TX2
Nvidia сделала правильные выводы, и следующее поколение было сделано офигенно. TX1|TX2, это уже не чипы, а чип на плате.


Но, естественно, не всё слава богу. Что не так:
- Jetson TX2 это дорогая платформа. В большинстве продуктов вы будете использовать основной модуль (как я понимаю от размера партии цена будет где-то от 200-250 до 350-400 у.е. за штуку). Для него нужна CarrierBoard. Не знаю текущий рынок, но раньше это было примерно 100-300 у.е. в зависимости от комплектации. Ну, и сверху ваш обвес.
- Jetson TX2 это не самая быстрая платформа. Ниже мы будем обсуждать сравнительные скорости, там я покажу почему это не лучший вариант.
- Надо отводить много тепла. Наверное это справедливо для почти всех платформ про которые мы будем говорить. Корпус должен решать проблему теплоотведения. Вентиляторы.
- Это плохая платформа для маленьких партий. Партии в сотни устройств — ок. Заказать материнские платы, разработать дизайн и корпусировать — норм. Партии в тысячи устройств? Разработать свою материнку — и шикарно. Если вам нужно 5-10 — плохо. Вам придётся брать DevBoard скорее всего. Они большого размера, их немного мерзко прошивать. Это не платформа уровня RPi-готовности.
- Плохая поддержка от Nvidia в плане технических вопросов. Слышал очень много ругани что на запросы отвечают что либо это секретная информация, либо ответы по месяцу.
- Плохая инфраструктура в России. Сложно заказывать, надо долго ждать. Но при этом дилеры работают хорошо. Мне попался недавно Jetson nano который сгорел в день запуска — поменяли без вопросов. Сам забрали курьером/привезли новый. ВАХ! Так же, сам видел, что московский офис консультирует хорошо. Но как только уровень их знаний не позволяет ответить на вопрос и требует запроса к международному офису — ответов ждать долго.
Что офигенно:
- Очень много информации, очень большое комьюнити.
- Вокруг Nvidia много мелких фирм выпускающих аксессуары. Они открыты к переговорам, вы можете затюнинговать их решение. И CarierBoard, и прошивку, и охлаждающие системы.
- Поддержка всех нормальных фреймворков (TensorFlow|PyTorch) и полноценная поддержка всех сетей. Единственную конвертацию которую, возможно, вам придётся сделать — это перенести код на TensorRT. Это сохранит память, возможно ускорит. По сравнению с тем что будет на других платформах это смешно.
- Я не умею разводить платы. Но от тех кто это делал для Nvidia — слышал что TX2 это неплохой вариант. Есть мануалы, соответствуют реальности.
- Неплохое энергопотребление. Но из всего что будет у нас именно “embedded” — самое плохое:)
- Суппорт в России (выше объяснял почему)
- В отличие от movidius | RPi | Coral | Gyrfalcon — это настоящий GPU. Вы можете гонять на нём не только сетки, но и нормальные алгоритмы
Как результат — это хорошая платформа для вас если у вас штучные девайсы, но по каким-то причинам вы не можете поставить полноценный комп. Что-то массовое? Биометрия — скорее нет. Распознавание номеров — на грани, зависит от потока. Переносимые устройства с ценой овер 5к баксов — возможно. Автомобили — нет, проще ставить более мощную платформу чуть дороже.
Как мне кажется, с выходом нового поколения дешёвых девайсов TX2 со временем умрёт.
Материнские платы для Jetson TX1|TX2|TX2i и прочие выглядят примерно так:

Jetson Nano

- Конструкция слабая и не отлаженная:
- Перегревается, при постоянной нагрузке периодически виснеты/вылетает. Знакомая фирма уже 3 месяца пытается забороть все проблемы — не выходит.
- У меня один погорел при питании с USB. Слышал, что у одного знакомого погорел USB выход, а работал штекерный. Скорее всего какие-то траблы с питанием USB.
- Если корпусировать оригинальную плату — то радиатора от NVIDIA не хватит, нафиг перегреется.
- Скорости как-то маловато. Почти в 2 раза меньше TX2 (в реальности может и в 1.5, но зависит от задачи).
- Партии в 5-10 устройств — вообще очень хорошо. 50-200 — сложно, придётся компенсировать все баги производителя, обвешивать вотчдогами, если надо добавить что-то типо POE, то будет больно. Более большие партии. На сегодня не слышал пока про успешные проекты. Но мне кажется, что там сложности могут всплыть как с TK1. Если честно, то хочется надеяться что в следующем году выйдет Jetson Nano 2, где эти детские болезни поправят.
- Поддержка плохая, same as TX2
- Плохая инфраструктура
Хорошее:
- Достаточно бюджетно, в сравнении с конкурентами. Особенно для малых партий. Выгодно по «цена/производительность»
- В отличие от movidius | RPi | Coral | Gyrfalcon — это настоящий GPU. Вы можете гонять на нём не только сетки, но и нормальные алгоритмы
- Просто запустить любую сеть (same as tx2)
- Энергопотребление (same as tx2)
- Суппорт в России (same as tx2)
Сам Nano вышел в начале весны, где-то с апреля/мая я активно в него тыкался. Успели уже два проекта сделать на них. В целом проблемы обозначил выше. Как хоббийный продукт/продукт для малых партий — очень круто. Но можно ли затащить в продакшн и как это сделать — пока не понятно.
Поговорим о скорости Jetson.
Сравнивать с другими устройствами мы будем сильно позже. А пока просто поговорим о Jetson и скорости. Почему Nvidia нас обманывает. Как оптимизировать ваши проекты.
Ниже всё пишется про TensorRT-5.1. С 17.09.2019 вышла TensorRT-6.0.1, все утверждения надо перепроверять там.
Давайте предположим, что поверим Nvidia. Откроем их сайт и посмотрим время инференса SSD-mobilenet-v2 на 300*300:
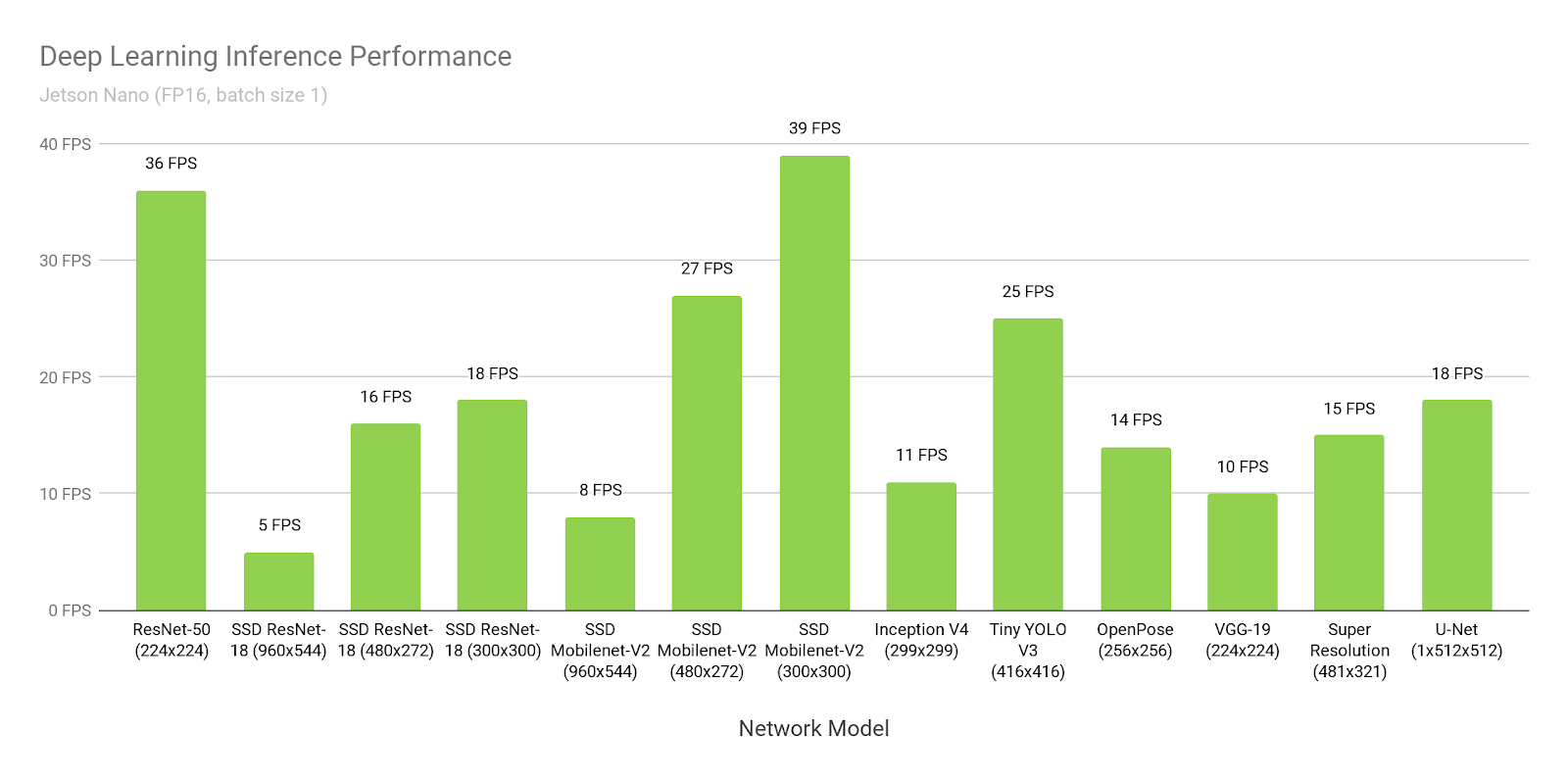
- SSD состоит из двух частей. Одна часть — это нейронка. Вторая часть — постобработка того что выдала нейронка (non maximum suppression) + предобработка того что загружается на вход.
- Как я и говорил ранее, под Jetson всё надо конвертировать в TensorRT. Это такой нативный фреймворк от NVIDIA. Без него всё будет плохо. Только вот есть одна проблемка. Портируется туда далеко не всё, особенно из TensorFlow. Глобально есть два подхода:
- Google, сам понимая, что это проблема, выпустил для TensorFlow такую штуку, которая называется “tf-trt”. По сути это надстройка на tf, которая позволяет конвертировать на tensorrt любую сетку. Части которые не поддерживаются — инферятся на CPU, остальное на GPU.
- Переписать все слои/найти их аналоги
В примерах выше:
- В этой ссылке время 300ms это обычный tensorflow без оптимизации.
- Там же, 72ms — это tf-trt версия. Там весь nms по сути делается на проце.
- Это фанатская версия, где человек весь nms перенёс и сам написал на gpu.
- А это… Это NVIDIA решила измерить все производительности без постобработки нигде явно об этом не упомянув.
Для себя надо понимать, что если бы это была ваша нейронка, которую бы никто до вас не конвертировал, то без проблем вы бы смогли запустить её со скоростью 72ms. А со скоростью 46 ms посидев над мануалами и сорсами день-недельку.
По сравнению со многими другими вариантами — это очень хорошо. Но не забывайте, что что бы вы не делали — никогда не верьте бенчмаркам от NVIDIA!
RaspberryPI 4
Продакшн?.. Я так и слышу, как десятки инженеров начинают смеяться от упоминания слова “RPI” и “продакшн” рядом. Но, я вынужден сказать — RPI всё же стабильнее Jetson Nano и Google Coral. Но, безусловно, проигрывает TX2 и, судя по всему, gyrfalcone.

- Как бы не хотелось, это не продуктовое решение. Перегревы. Периодические зависания. Но за счёт огромного комьюнити на каждую проблему есть сотни решений. Это не делает Rpi хорошим для тысячных тиражей. Но десятки/сотни — вай нот.
- Скорость. Это самое медленное устройство из всех основных про которые мы говорим.
- Поддержка от производителя почти отсутствует. Товар ориентирован на энтузиастов.
Плюсы:
- Цена. Нет, конечно, если вы сами разводите плату, то используя gyrfalcone вы может быть сможете сделать дешевле на партиях в тысячи. Но скорее всего это нереально. Там где производительности RPi хватает — это будет самое дешёвое решение.
- Популярность. Когда вышел Caffe2, то в базовом релизе была версия под Rpi. Tensorflow light? Конечно работает. И.т.д., и.т.п. Что не делает производитель — переносят пользователи. Я запускал на разных RPi и Caffe и Tensorflow и PyTorch, и кучу более редких вещей.
- Удобство для маленьких партий/штучных изделий. Просто прошить флешку и запустить. Есть WiFi на борту, в отличие от JetsonNano. Можно просто через PoE запитать (вроде там нужно докупить переходник, которые продаются активно).
Про скорость Rpi мы поговорим в конце. Так как производитель не постулирует что его продукт для нейронок — то мало бенчмарков. Всем понятно что Rpi не идеален по скорости. Но для каких-то задач годится даже он.
У нас было пара полупродуктовых задач, которые мы реализовывали на Rpi. Впечатление было приятное.
Movidius 2

Хотя нет, не так. Разговор надо начинать не с Movidius, а с Intel OpenVino. Я бы сказал, что это идеология. А точнее фреймворк. По сути это набор предобученных нейронок и инференесов к ним, которые оптимизированы под продукты компании Intel (процы, GPU, спецвычислители). Интегрированный с OpenCV, с Raspberry Pi, с кучей других свистелок и перделок. Плюсом OpenVino является то, что в нём масса нейронок. В первую очередь самые известные детекторы. Нейронки для распознавания людей, лиц, номеров, букв, поз, и.т.д., и.т.п. (1, 2, 3). И они обучены. Не по открытым датасетам, а по датасетам собранным самим Intel’ом. Они сильно больше/разнообразнее и лучше открытых. Их можно дообучить по вашим кейсам, тогда работать будут вообще классно. Можно ли сделать лучше? Конечно можно. Например распознавание номеров которое мы делали — работало ощутимо лучше. Но мы потратили на его разработку и понимание как его сделать идеально — много лет. А тут вы можете из коробки получить охрененное качество, которого вам хватит для большинства кейсов. У OpenVino, конечно, есть несколько проблем. Сетки там появляются далеко не сразу. Если что-то новое выйдет — вам долго ждать. Сетки там появляются глубоко продуктовые. Никаких GANов вы там не найдёте. Только глубокая польза. И, по нашему опыту, туда достаточно сложно перегнать сетку, если у вас есть какие-то хитрости в архитектуре, отличные от суровых стандартов. Зато ребята перегнали некоторые, даже достаточно сложные модели:

Глобально минус у него один. USB это, блин, не продуктовый разъём!!! Вы не можете сделать девайсину с USB. Выход есть. Intel продаёт чипы. Даже что-то такое есть в продаже на прошлом поколении (1, 2) Вроде как есть продукты на нём. Но я не видел ни одной продуктовой платы на которой можно было бы разработать что-то. И ни одна знакомая мелко-средняя фирма ничего разрабатывать на базе этого чипа не начинала. С другой стороны что будет танку?.. Он нас всё равно догонит и раздавит:) Ах да, и из радостного. OpenVino, как я понимаю, разрабатывают в России, в Нижнем Новгороде (мне кажется что половину Computer Vision делают там). Вот тут Сергей про него рассказывает:
Ладно, уже почти про всё сказали. Краткая вытяжка по Movidius 2. Минусы:
- Базовая версия не продуктовая. Хуже Rpi и Jetson Nano. Можно ли купить чип и собрать на его основе свой девайс — не понятно. Но в любом случае это долго и дорого. Возможно выйдут Third Party решения?
- Свои сети сложно портировать. Необычные слои сразу в минус. Частично компенсируется представленным спектром сетей.
- Скорость не самая быстрая. Но об этом позже.
- Нужно базовое устройство для запуска. Скорость инференса зависит от устройства и от наличия на нём USB 3.0
- Если я правильно понимаю, то две сетки держать в памяти одновременно нельзя. Надо выполнить выгрузку-загрузку. Что замедляет инференс нескольких сетей. Для Movidius первого поколения это точно было так. Вроде ничего не должно было поменяться.
Плюсы:
- Очень простой и удобный. Достаточно минимального знания питона чтобы создать рабочий прототип. Не надо ничего обучать.
- Низкое энергопотребление, не перегревается
- Неплохая поддержка, как я слышал
Сами мы не использовали его ни в одном проекте. Все наши знакомые которые тестили его для инференса задач — в результате не взяли в продакшн.
Но пара фирм которые я консультировал, где были задачи уровня “нам надо поставить 20-30 камер на шлагбаумы, но покупать ничего не хотим, разработаем сами” — вроде как в итоге взяли именно Movidius.
Недавно Intel анонсировал новую платформу. Но пока никакой подробной информации нет, посмотрим.

Прислали ссылку на такое. Плата с двумя Мовидиусами вторыми. Вполне себе embedded формат. PCI-e шину много кто для такого использует. К таким вещам только в цене вопрос. Два мовидиуса — вряд ли такая штука будет дешевле чем 200 у.е. стоить. А ещё нужно будет свою плату с своей системой…
Google Coral
Я разочарован. Не, нет ничего чего бы я не предсказывал. Но я разочарован что Google решили выпустить это. Тестил это чудо я в начале лета. Может быть с тех пор что-то изменилось, но описывать я буду свой тогдашний опыт.
Настройка… Чтобы прошить Jetson Tk-Tx1-Tx2 вам надо было воткнуть его в компьютер хост и в питание. И этого было достаточно. Чтобы прошить Jetson Nano и RPi вам достаточно запушить образ на флешку.
А чтобы прошить Coral — вам нужно в правильном порядке втыкать три провода:

Ок. Запустили. Как вы думаете, просто ли запустить вашу сетку на нём? Почти никак:)
Вот список того что можно пустить. Если честно, то до этой мысли я дошёл не быстро. Потратил пол дня. Нет, правда. Вы не можете скачать модель из репозитория TF и запустить на устройстве. Или там надо перекорёжить все слои. Инструкции не нашёл. Так вот. Надо взять именно модель из репозитория сверху. Их там не много (с начала лета добавилось 3 модели). И как её дотренировать? Открыть в TensorFlow в стандартном пайплайне? ХАХАХАХАХАХАХА. Конечно нет!!! У вас есть специальный Doker-контейнер, и модель будет тренироваться только в нём. (Наверное, можно как-то и в своём TF затрейнить… Но инструкции, инструкции… Которых не было и вроде нет.) Скачали/установили/запустили. Что это такое… Почему GPU на нуле?.. ПОТОМУ ЧТО ТРЕНИРОВАТЬСЯ БУДЕТ НА CPU. Докер есть только под него!!! Хотите ещё прикол? В инструкции написано “based on a 6-core CPU with 64G memory workstation”. Кажется что это лишь совет? Может быть. Только вот мне не хватило моих 8 гигов на том серваке где большая часть моделей тренируется. Обучение на 4-ртом часу выжрало их все. Стойкое ощущение что у них что-то текло. Я попробовал ещё пару дней с разными параметрами на разных машинах, эффект был один. Я не стал перепроверять это перед тем как выложить статью. Если честно, то мне хватило одного раза.
Что ещё добавить? Что этот код не генерит модель? Чтобы её сгенерить вы должны:
- Зафризить граф
- Сконверить его в tflite
- Скомпилировать в формал Edge TPU. Слава богу сейчас это делается на компе. Весной это можно было сделать только online. И там надо было ставить галочку “я не буду использовать это во зло/я не нарушаю никаких законов этой моделью”. Сейчас уже слава богу нет этого.

Минусы:
- Эта плата не продуктовая на уровне АД. Про продажу чипов не слышал => продакшн нереален
- Уровень разработки максимально ужасен. Всё бажет. Пайплайн разработки не вписывается в традиционные схемы.
- Вентилятор. На “энергетически оптимальном чипе” они ставят его. Ладно, не буду больше про продакшн
- Стоимость. Дороже всего кроме TX2.
- Две сетки держать в памяти одновременно нельзя. Надо выполнить выгрузку-загрузку. Что замедляет инференс нескольких сетей.
Плюсы:
- Из всего о чём мы будем говорить Coral самый быстрый
- Потенциально, если чип довести, то он производительнее чем Movidius. И вроде его архитектура более оправдана для нейронок.
Gyrfalcon

Зато удалось посмотреть оригинальную документацию. Из неё тоже мало что понятно (китайский). По хорошему надо было тестить и смотреть исходники.
Техподдержка RockChip на нас тупо забила.
Не смотря на этот ужас мне понятно, что тут всё же в первую очередь косяки RockChip’а. И у меня есть надежда что в нормальной плате Gyrfalcon может быть вполне используемым. Но из-за недостатка информации мне сложно сказать.
Минусы:
- Нет открытых продаж, взаимодействуют только с фирмами
- Мало информации, нет комьюнити. Существующая информация зачастую на китайском. Нельзя заранее предсказать возможности платформы
- Скорее всего инференс не более одной сети одновременно.
- С самим гирфальконом можно взаимодействовать только производителям железяк. Остальным надо искать каких-то посредников/производителей плат.
Плюсы:
- Как я понимаю по цене чипа гирфалькон сильно дешевле остальных. Даже в форм факторе флешек.
- Уже сейчас есть сторонние устройства с интегрированным чипом. Следовательно разработка несколько проще чем у movidius.
- Уверяют что есть много предобученных сеток, перенос сеток сильно проще чем Movidius|Coral. Но я бы не гарантировал это как правду. У нас не получилось ничего.
Если вкратце рассказывать, то заключение такое: очень мало инфы. Нельзя закладываться только на эту платформу. И прежде чем что-то сделать на ней — надо произвести огромный ресёрч.
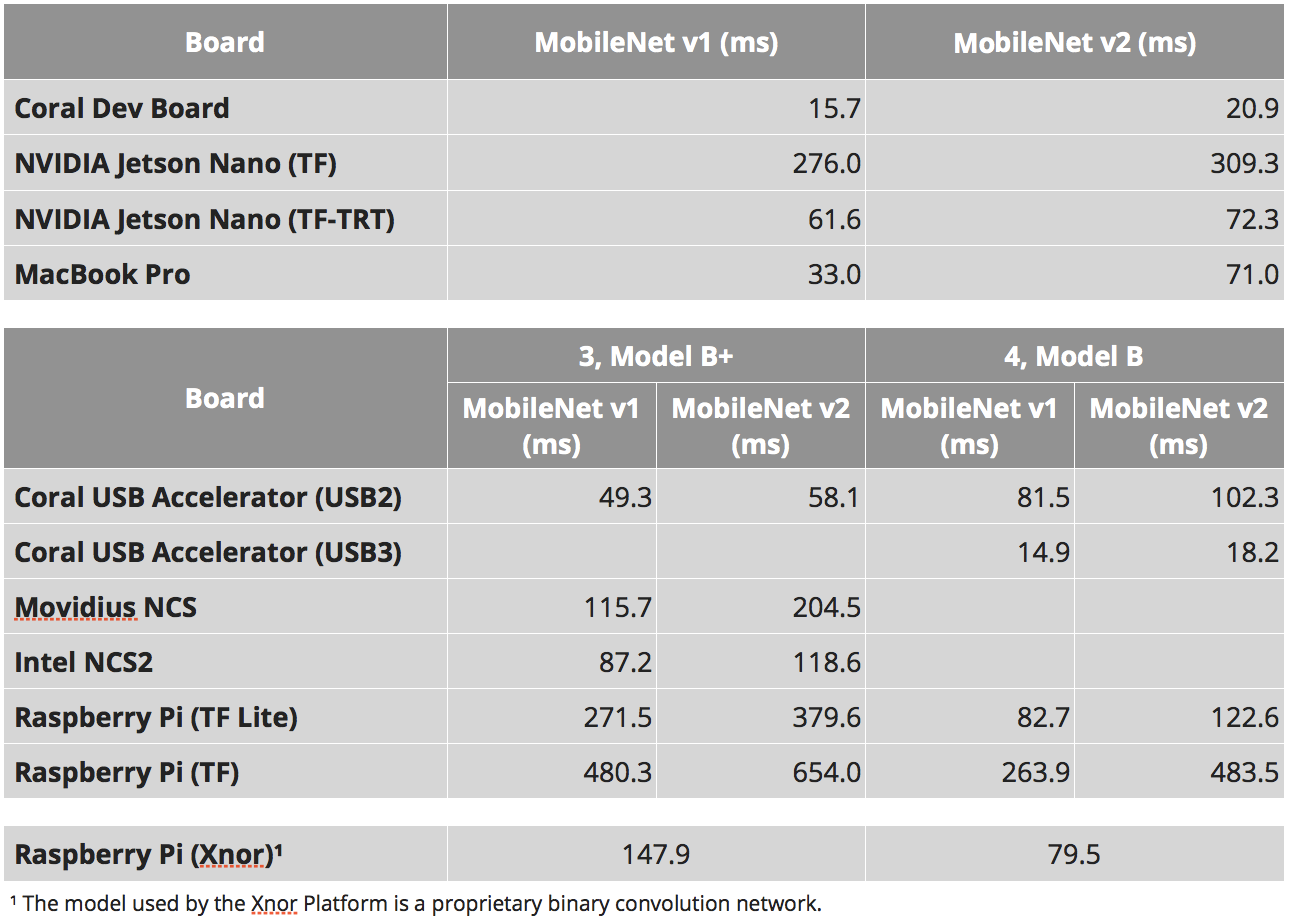
Скорости
Мне очень нравиться, как 90% сравнений embedded устройств сводят к сравнению скоростей. Как вы поняли выше — данная характеристика очень условна. Для Jetson Nano можно запускать нейронки как чистом tensorflow, можно на tensorflow-tensorrt, а можно на чистом tensоrrt. Устройства с специальной тензорной архитектурой (movidius | coral | gyrfalcone) — может будут быстры, но в первую очередь могут работать только с стандартными архитектурами. Даже для Raspberry Pi не всё так однозначно. Нейронки от xnor.ai дают ускорение в полтора раза. Но я не знаю насколько они честные, а что выиграно за счёт перехода к int8 или другим приколам. При этом, ещё одной интересной штукой является такой момент. Чем сложнее нейронка, чем сложнее устройство для инференса — тем непредсказумее будет итоговое ускорение которое можно вытащить. Взять какой-нибудь OpenPose. Там нетривиальная сеть, сложная постобработка. И то и то можно оптимизировать за счёт:
- Перенос постобрабтки на GPU
- Отптимизация постобработки
- Оптимизация нейронной сети под особенности платформы, например:
- Использование сетей оптимизированных под платформу
- Использование модулей сетей под платформу
- Перенос на int8|int16|бинаризация
- Использование нескольких вычислителей (GPU|CPU|и.т.д.). Помнится на Jetson TX1 мы однажды хорошо ускорились когда перенесли весь функционал связанный с стримингом видео на встроенные ускорители проца для этих целей. Банально, но сети ускорились. При балансировке всплывает очень много интересных комбинаций
Иногда кто-то пробует оценить что-то такое для всех возможных комбинаций. Но реально, как мне кажется, это бесперспективно. Сперва надо определиться с платформой, а уже потом пробовать полностью вытащить всё что можно. К чему я это всё. К тому что тест “сколько времени работает MobileNet” — это очень плохой тест. Он может выдать что платформа X оптимальна. Но когда вы попробуете развернуть там свою нейронку и постобработку, то вас может ждать очень большое разочарование.
Но сравнение mobilnet’ов всё же даёт какую-то информацию о платформе. Для простых задач. Для ситуаций когда вы понимаете что всё равно задачу проще к стандартным подходам свести. Когда вы хотите оценить скорость именно вычислителя.
Таблица ниже взята из нескольких мест:
- Вот эти исследования: 1, 2, 3
- Для SSD есть такой параметр “число выходных классов”. И от этого параметра скорость инференса может сильно меняться. Я старался выбрать исследования с одинаковым числом классов. Но не везде это может быть так.
- Наш опыт работы с TensorRT. Знал какие сорсы работают какие нет.
- Для gyrfalcon вот эти видео из учёта того что там mobilnet v2 + оценка сколько стоит изменение площади. Вот это видео говорит что 2803 может быть в 3-4 раза быстрее. Но для 2803 нет никаких оценок по SSD. Вообще я наиболее сомневаюсь в скоростях в этом пункте.
- Я старался выбирать то исследование которое давало реальную максимальную скорость (не брал версию Nvidia без NMS, например)
- Для Jetson TX2 использовал вот эти оценки, но тут 5 классов, на том же числе классов что остальные будет медленнее. Я как-то прикинул по опыту/сравнению с Nano по ядрам, что там должно быть
- Я не учитывал приколы с битностью. Я не знаю на какой битности работали Movidius и Gyrfalcon.
Как результат имеем:

Сравнение платформ
Попробую подвести всё что я говорил выше к некоторой единой таблице. Жёлтым я выделил те места где моих знаний мало чтобы сделать однозначный вывод. И, собственно 1-6 — это некоторое сравнительная оценка платформ. Чем ближе к 1 — тем лучше.

Шаг в сторону
То о чём мы говорили — это лишь небольшая точка в огромном пространстве вариаций вашей системы. Наверное, общие слова которыми можно охарактеризовать эту область:
- Низкое энергопотребление
- Маленький размер
- Высокая вычислительная мощность
Но, глобально, если уменьшить значимость одного из критериев — в список можно вносить множество других устройств. Ниже я пройдусь по всем подходам которые встречал.
Intel
Как мы говорили, когда обсуждали Movidius, у Intel есть платформа OpenVino. Она позволяет очень эффективно обрабатывать нейронки на процессорах Intel. При этом платформа позволяет поддерживать даже всякие intel-gpu на чипе. Я сейчас боюсь точно утверждать о том какая там производительность под какие задачи. Но, как я понимаю, хороший камень с GPU на борту вполне ? производительности от 1080 выдаёт. По некоторым задачкам может даже быстрее.

Jetson AGX

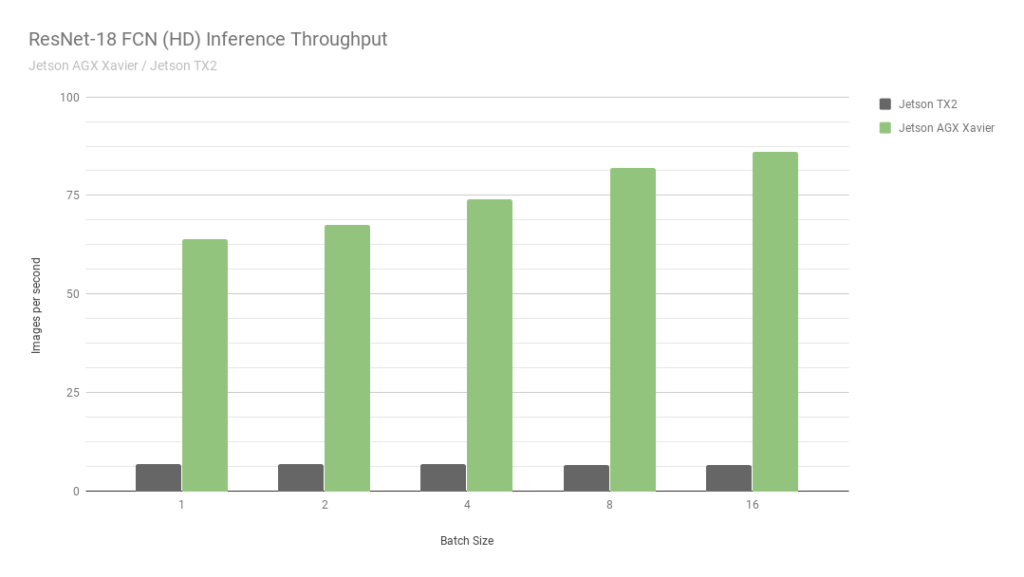
Мы сами с ними не работали, так что мне сложно сказать что-то более подробное, описать спектр задач где они самые оптимальные.
Nvidia gpu | laptop version
Если отменить жёсткое ограничение на энергопотребление, то Jetson TX2 уже не выглядит оптимальным. Как и AGX. Обычно люди пугаются использовать GPU в продакшне. Отдельная плата, всё такое.
Но есть миллионы фирм которые предлагают собрать вам кастомное решение на одной плате. Обычно это платы под ноутбуки/миникомпьютеры. Или, в конце концов вот такое:

Мобильники
Я не хочу вдаваться в эту тему глубоко. Чтобы рассказать всё что есть в современных мобильниках для нейронок/какие фреймворки/какое железо, и.т.д., понадобится не одна статья с эту размером. А с учётом того что мы тыкались в эту сторону всего 2-3 раза, я считаю себя некомпетентным для этого. Так что лишь пара наблюдений:
- Существует очень много аппаратных ускорителей на которых можно оптимизировать нейронки.
- Не существует общего решения которое хорошо зайдёт везде. Сейчас есть какая-то попытка сделать Tensorflow lite таким решением. Но, как я понимаю, оно пока им не стало.
- У некоторых производителей есть свои специальные ферймворки. Мы год назад помогали оптимизировать под Snapdragon фреймворк. И это было ужасно. Качество нейронок там сильно ниже чем на всём о чём я сегодня говорил. Отсутствует поддержка 90% слоёв, даже базовых, таких как “сложение”.
- Так как нет питона — инференс сетей весьма странный, нелогичный и неудобный.
- По производительности — бывает что всё очень неплохо (например на каком-нибудь iphone).
Мне кажется, что для embedded мобилки не лучшее решение (исключение — какие-нибудь низкобюджетные системы face recognition). Но видел пару случаев когда их использовали как ранние прототипы.
GAP8
Недавно был на конференции Usedata. И там один из докладов был про инференс нейронок на самых дешёвых процах (GAP8). И, как говориться, голь на выдумки хитра. В рассказе пример был весьма притянут за уши. Но автор рассказывал как они смогли добиться инференса по лицам примерно за секунду. На очень простой сетке, по сути без детектора. Путём безумных и долгих оптимизаций и экономии на спичках. Мне такие задачи всегда не нравятся. Никакого исследования, только кровь. Но, стоит признать, что я могу представить себе задачки где низкопотребляющие процы дают классный результат. Наверное не для распознавания лиц. Но где-то где можно распознавать по 5-10 секунд входное изображение…
Grove AI HAT

Сервер/удалённое распознавание
Каждый раз когда к нам приходят за консультацией по embedded платформе — мне хочется крикнуть “бегите, глупцы!”. Надо очень аккуратно оценивать необходимость такого решения. Проверять любые другие варианты. Всем и всегда я советую делать прототип с серверной архитектурой. И уже при его эксплуатации решать — нужно ли делать реальное embedded. Ведь embedded это:
- Увеличение сроков разработки, зачастую в 2-3 раза.
- Сложная поддержка и отладка в продакшне. Любая разработка с ML — это постоянная доработка, апдейт нейронок, обновления системы. Embedded — всё ещё сложнее. Как перезаливать прошивку? А если у вас и так есть доступ на все юниты — то зачем вычислять на них, когда можно вычислять на одном девайсе?
- Усложнение системы/повышение рисков. Больше точек отказов. При этом пока система не заработает целиком — можно и не понять: подходит ли платформа для данной задачи?
- Увеличение цены. Одно дело поставить простенькую плату типа nano pi. А другое — закупать TX2.
Да, я знаю, что есть задачи где нельзя делать серверные решения. Но, как ни странно, их сильно меньше чем принято считать.
Выводы
В статье я старался обойтись без явных выводов. Это скорее повествование про то что сейчас есть. Чтобы делать выводы — надо исследовать в каждом конкретном случае. И не только платформы. Но и саму задачу. Любую задачу можно немного упростить/немного изменить/немного заточить под устройство.
Проблема этой темы в том, что тема меняется. Приходят новые устройства/фреймворки/подходы. Например, если завтра NVIDIA включит поддержку int8 для Jetson Nano — то ситуация сильно изменится. Когда я пишу эту статья — я не могу быть уверенным, что информация уже не поменялась два дня назад. Но, надеюсь, что мой небольшой рассказ поможет вам лучше ориентироваться в вашем следующем проекте.
Было бы классно, если у вас есть дополнительная информация/я что то пропустил/что-то сказал не так — напишите тут подробности.
п.с.
Уже когда дописал статью почти, snakers4 скинул недавний пост из своего телеграмм канала Spark in me, который почти про те же проблемы с Jetson. Но, как я выше писал, — в условиях любого энергопотребления — я бы ставил что-то типо zotac'ов или IntelNUC. А как embedded джетсон не самая плохая платформа.

Телеграм: t.me/ainewsline
Источник: habr.com