Угадай меня, если сможешь: прогнозирование рейтинга фильма до его выхода
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2019-09-11 09:22
Итак, набор данных содержит следующую информацию:
- Данные о фильме: время выхода, бюджет, язык, компания и страна-производитель, и т.п. А также средний рейтинг (его и будем прогнозировать)
- Ключевые слова (тэги) о сюжете
- Имена актеров и съемочной группы
- Собственно рейтинги (оценки)
Использованный в статье код (python) доступен на github.
Предварительная фильтрация данных
Полный массив содержит данные о более чем 45 тысячах фильмов, но так как задача — спрогнозировать рейтинг, нужно убедиться в объективности оценок конкретного фильма. Например, в том что его оценили достаточно много людей.
У большинства фильмов довольно мало оценок:

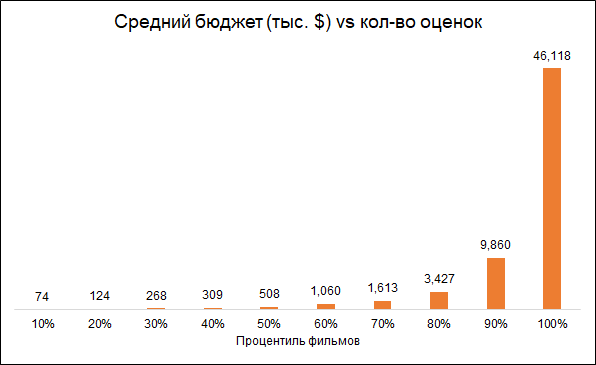
Кроме того, удалим фильмы, вышедшие до начала работы рейтингового сервиса (1996 год). Тут проблема в том, что современные фильмы оцениваются в среднем хуже, чем старые, просто потому что среди старых фильмов смотрят и оценивают лучшее, а среди современных — всё.
В итоге финальный массив содержит около 6 тыс. фильмов.
Используемые фичи
Будем использовать несколько групп фич:
- Метаданные о фильмах: принадлежит ли фильм “коллекции” (серии фильмов), страна выпуска, компания-производитель, язык фильма, бюджет, жанр, год и месяц выхода фильма, его длительность
- Ключевые слова: для каждого фильма есть список тэгов, описывающих его сюжет. Поскольку слов много, они были обработаны следующим образом: сгруппированы в группы по схожести (например, accident и car accident), на основе этих групп и отдельных слов сделан РСА-анализ, а из его результатов отобраны наиболее важные компоненты. Это уменьшило размерность пространства фич.
- Предыдущие “заслуги” актеров, снимавшихся в фильме. Для каждого актера был сформирован список фильмов, в которых он снимался ранее и посчитан рейтинг этих фильмов. Так для каждого фильма сформировался показатель, агрегирующий успешность фильмов, в которых снимались актеры ранее.
- “Оскары”. Если актеры, режиссер, продюсер, сценарист или оператор ранее участвовали в фильме, который был номинирован либо получил “Оскар” за лучший фильм, режиссуру или сценарий — это учитывалось в модели. Кроме того, если актеры были номинантами или победителями премии “Оскар” за лучшую роль первого или второго плана — это тоже было учтено. Информация о премиях “Оскар” взята с википедии.
Некоторая занимательная статистика
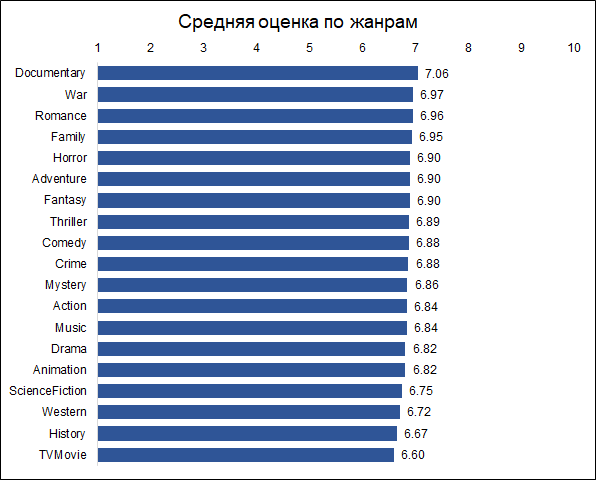
Документальные фильмы получают самые высокие оценки. Это хороший повод заметить, что разные фильмы оценивают разные люди, и если бы документальные фильмы оценивали любители экшна, то возможно результаты были бы другие. То есть оценки смещены из-за изначальных предпочтений публики. Но для нашей задачи это не принципиально, так как мы хотим прогнозировать не условно объективную оценку (как если бы каждый зритель посмотрел все фильмы), а именно ту, которую фильму даст его аудитория.
Кстати, интересно что исторические фильмы при этом оценены гораздо ниже документальных.
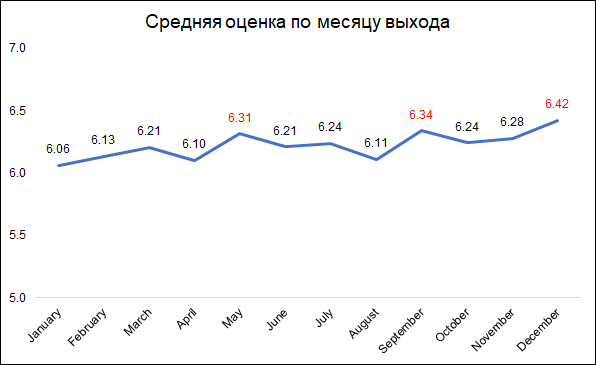
Вероятно, это можно объяснить так:
- в декабре компании выпускают лучшие фильмы, чтобы собрать кассу за время рождественских каникул
- в сентябре выходят фильмы, которые будут участвовать в борьбе за “Оскар”
- май — время релиза для блокбастеров, идущих в летнее время.
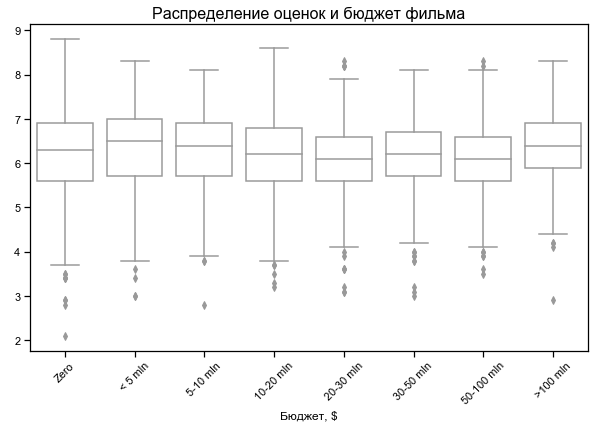
Самые высокие оценки у самых коротких и самых длинных фильмов
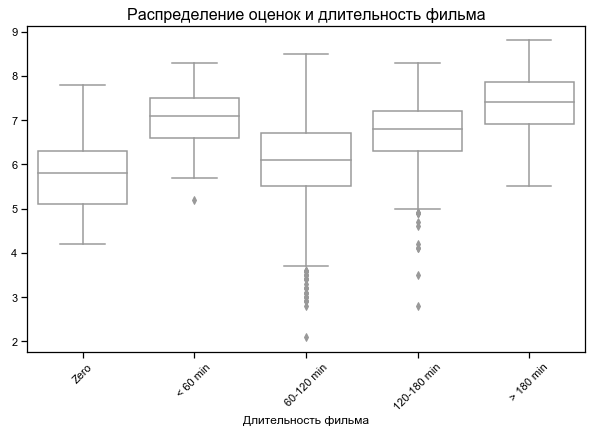
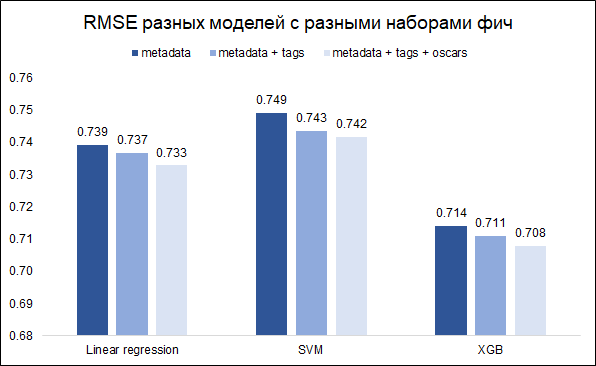
Результаты на разных наборах фич
Наша задача — прогнозирование рейтинга — задача регрессии. Протестируем три модели — линейная регрессия (как baseline), SVM и XGB. В качестве метрики качества выберем RMSE. На графике ниже показаны значения RMSE на валидационном сете для разных моделей и разных наборов фич (хотелось понять, стоило ли морочиться с ключевыми словами и с Оскарами). Все модели построены с базовыми значениями гиперпараметров.
Как видим, наилучший результат у XGB с полным набором фич (метаданные о фильме + ключевые слова + данные об Оскарах).
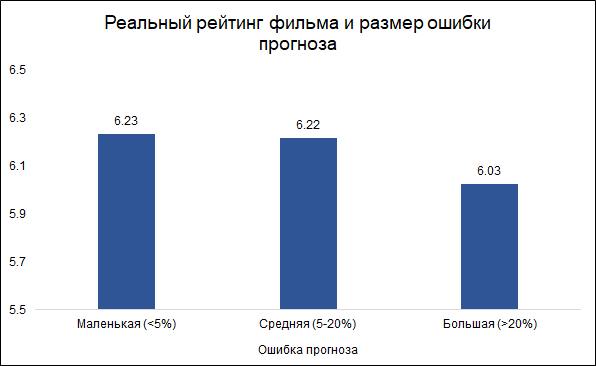
Анализ ошибок и заключительные комментарии
Будем считать ошибки меньше 5% маленькими (таких около трети), а ошибки больше 20% — большими (таких примерно 10%). В остальных случаях (чуть больше половины) будем считать ошибку средней.
Интересно, что размер ошибки и рейтинг фильма связаны: модель реже ошибается на хороших фильмах и чаще на плохих. Выглядит логично: хорошие фильмы, как и любая другая работа, скорее делаются более опытными и профессиональными людьми. Про фильм Тарантино с участием Бреда Питта можно и заранее сказать, что скорее всего он получится хорошим. В то же время, малобюджетный фильм с малоизвестными актерами может быть как хорошим, так и плохим, и тяжело судить, не видев его.

Поэтому возникла идея построить две отдельные модели: одну для фильмов, у которых актеры или команда номинировались на “Оскар”, и вторую для остальных. Идея была в том, что это может уменьшить общую ошибку. Однако эксперимент не удался: общая модель давала RMSE 0.706, а две отдельные — 0.715.
Поэтому оставим изначальную модель. Показатели ее точности по итогу такие: RMSE на тренинговой выборке — 0.688, на валидационной — 0.706, и на тестовой — 0.732.
То есть, наблюдается некоторый оверфиттинг. В самой модели уже были установлены параметры регуляризации. Еще одним способом уменьшения оверфиттинга мог бы стать сбор большего количества данных. Чтобы понять, поможет ли это, построим график ошибок для разных размеров тренинговой выборки — от 100 до максимально доступных 3 тыс. Из графика видно, что начиная примерно с 2,5 тыс точек в тренинговом сете, ошибки на тренинговом, валидационном и тестовом сете меняются мало, то есть увеличение выборки не окажет значительного эффекта.
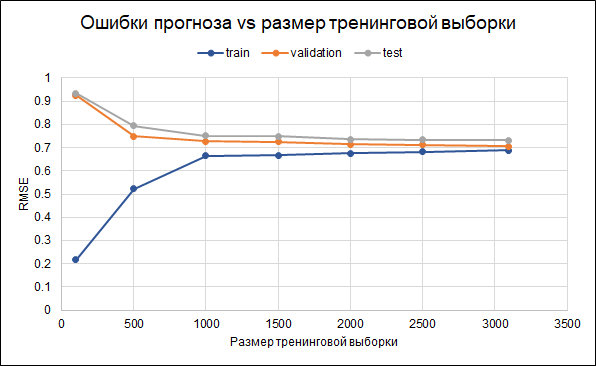
- Изначально по-другому отобрать фильмы (другой лимит количества голосов, дополнительные лимиты по другим переменным)
- Для подсчета рейтинга использовать не все оценки — возможно, отобрать более активных пользователей или удалить тех, кто выставляет только плохие оценки
- Попробовать разные способы замены отсутствующих данных (missing replacement)
Интересно, что самая большая ошибка прогноза (7 прогнозных баллов вместо 4.2 реальных) — у фильма “Бэтмэн и Робин” 1997 года. Фильм с Арнольдом Шварцнеггером, Джорджем Клуни и Умой Турман получил 11 номинаций (и одну победу) премии “Золотая малина”, возглавил список 50 худших фильмов за всю историю от киножурнала Empire и привел к отмене сиквела и перезапуску всей серии. Ну что же, тут модель, пожалуй, ошиблась совсем как человек :)
Телеграм: t.me/ainewsline
Источник: habr.com