NODE: нейросеть, которая работает на табличных данных
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2019-09-19 12:55

Neural Oblivious Decision Ensembles (NODE) — это нейросетевая архитектура, которая специально адаптирована для обработки табличных данных. Сейчас нейросети хорошо решают задачи из компьютерного зрения или обработки естественного языка. Однако не было доказано, что нейросеть лучше справляется с предсказанием переменной по табличным данным, чем ML-модели, основанные на деревьях. Разработкой NODE занимались исследователи из Яндекс. Модель обходит ML-альтернативы на 4 из 6 задачах. Имплементация модели на PyTorch доступна в открытом доступе.
Табличные данные — это данные, которые представлены в виде таблицы с предикторами и целевой переменной. Сейчас для решения задачи на табличных данных стандартным решением является использовать GBDT. Проблема подходов, основанных на деревьях, в том, что они не позволяют использовать end-to-end оптимизацию. Обычно такие подходы используют жадный поиск параметров и локальную оптимизацию процедур построения дерева. NODE отличается тем, что функция дерева дифференцируема. Модель использует метод обратного распространения ошибки для оптимизации поиска параметров.
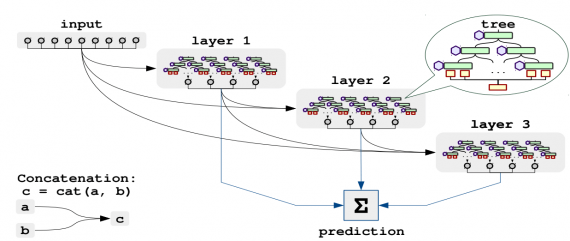
Что внутри
NODE архитектура, как и стандартные нейросетевые модели, состоит из слоев. На каждом слое модели находится дифференцируемые oblivious decision trees (ODT). learning models. Деревья решений обучаются end-to-end с использованием метода обратного распространения ошибки. Разделяющие фичи и трешхолды равны у внутренних узлов, которые находятся на одной глубине. Выход дерева — это взвешенная сумма выходов листьев.
Слой NODE может быть обучен сам по себе или внутри более комплексной модели. Это схоже с полносвязными слоями в стандартных нейросетях. Архитектура полной модели NODE базируется на DenseNet. Каждый слой состоит из нескольких деревьев.
Градиентный бустинг vs. NODE
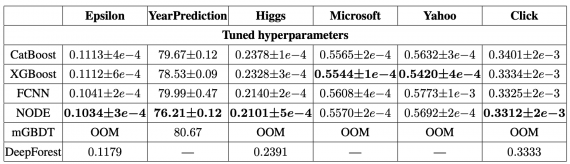
Исследователи сравнили модель с state-of-the-art подходами для решения задач на табличных данных. Среди тех деревянных моделей, которые они сравнивали: Catboost и XGBoost. Они также использовали для сравнения нейросеть из нескольких полносвязных слоев с нелинейностями (FCNN).
Ниже видно, что среди моделей с подкрученными параметрами NODE обходит все подходы на 4 из 6 задачах.
Телеграм: t.me/ainewsline
Источник: neurohive.io