Brain2Char: нейросеть декодирует текст из показаний мозга
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2019-09-16 16:36
свёрточные нейронные сети, работа головного мозга, Нейроинтерфейс

Brain2Char — это нейросеть, которая из показаний мозга декодирует информацию в текст. Это первая модель, которая на основе электрокортикографии решает задачу посимвольного восстановления текста. Brain2Char объединяет в себе state-of-the-art модели: 3D Inception слои, двунаправленные рекуррентные слои, расширенные сверточные слои, CTC функцию потерь.
По результатам, процент ошибки модели при декодирования текста трех добровольцев составил 10.6%, 8.5% и 7.0%. Размер словаря при этом варьировался от 1200 до 1900 слов. Было отмечено, что Brain2Char хорошо работает, когда два участника беззвучно изображают с помощью мимики.
Декодирование представлений языка напрямую из мозга может способствовать разработке интерфейсов для взаимодействия мозга и компьютера (BCI). Такие интерфейсы можно было бы использовать для коммуникации между двумя людьми и между человеком и компьютером.
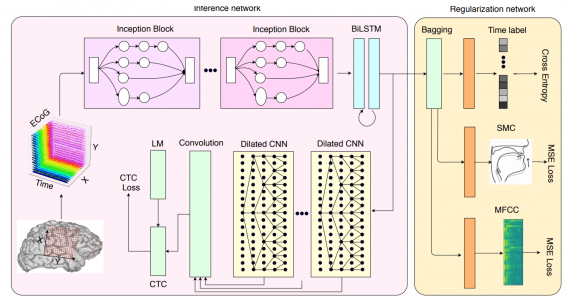
Архитектура модели
Brain2Char имеет модульную структуру и состоит из трех частей: нейронный кодировщик свойств, текстовый декодер и регуляризатор пространства скрытых представлений. Модульная структура позволяет обновлять компоненты нейросети без внесения изменений в структуру модели. Модель для предсказания состоит из кодировщика и декодировщика. Часть с регуляризацией используется только на этапе обучения.
Данные из мозга записываются с помощью электрокортикографии, когда доброволец произносит речь. На вход нейросети поступают 3D изображения мозга, а на выходе отдается текст, который был сгенерирован посимвольно.
Проверка работы модели
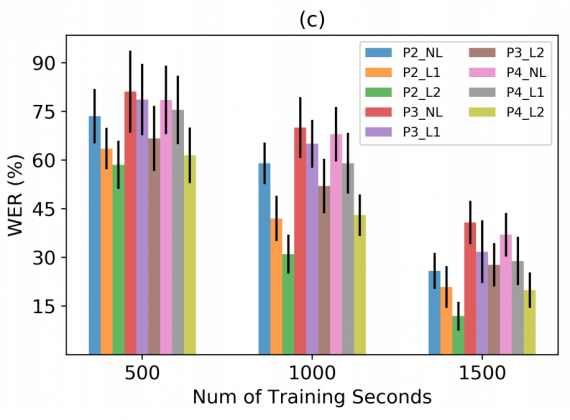
В исследовании принимали участие 4 добровольца, чья речь и мозговая активность синхронно фиксировались. Речь участников состояла из предложений из датасета MOCHA-TIMIT (для первых двух участников) и интервью в свободной форме (для вторых двух участников). Размер словаря в датасете составляет 1900 слов. Размер словаря при личных интервью составил 1200 слов.
Всего было собрано от 120 до 200 минут разговора для каждого участника. Участники 3 и 4 беззвучно с помощью мимики передали 20 предложений друг другу.
Ниже видно, что с увеличением времени обучения, процент ошибки сокращается более чем в два раза.
Телеграм: t.me/ainewsline
Источник: neurohive.io