Балто-славянские языки: генетика и лингвистика
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2019-09-07 15:40

Недавно в электронном научном журнале PLOS One было опубликовано масштабное генетическое исследование народов, говорящих на балтийских и славянских языках. Особенный интерес представляет, что данные генетики в этом случае сопоставляются с результатами лингвистического исследования балтийских и славянских языков, выполненного методом лексикостатистики.
Над исследованием работали более тридцати ученых из Белоруссии, Боснии и Герцеговины, Великобритании, Литвы, России, Украины, Франции, Хорватии и Эстонии, а также представители международного объединения Genographic Consortium. Руководили работой Рихард Виллемс (Richard Villems, Эстонский биоцентр и Институт молекулярной и клеточной биологии Тартуского университета) и Олег Балановский (Институт общей генетики РАН и Медико-генетический научный центр РАН).
Напомним, что как славянские, так и балтийские языки входят в индоевропейскую языковую семью. Специалисты по сравнительно-историческому языкознанию давно отметили тесную близость двух этих языковых групп, создав теорию балто-славянского родства, согласно которой из общего праязыка индоевропейцев выделился балто-славянский праязык, который потом разделился на прабалтийский и праславянский. Славянские языки разделяются на три основных ветви: южные, западные и восточные. Традиционная область обитания носителей славянских и балтийских языков – Восточная и отчасти Центральная Европа. На славянских языках сейчас говорят более 400 миллионов человек, на балтийских – более 4,5 миллионов.
Основной целью исследования было выявить генетические сходства и различия генофонда славян и балтов в сопоставлении с окружающими их народами, а также между различными группами внутри них. Полученную в итоге картину сравнили с генеалогическим древом балто-славянских языков, построенным при помощи лексикостатистики. Сравнение генетических профилей славян с данными о других народов позволило определить следы тех иноязычных популяций, которые были поглощены при распространении славян.
Генетики использовали данные трех типов: митохондриальная ДНК (наследуется по материнской линии), Y-хромосома (наследуется по отцовской линии), а также так называемые однонуклеотидные полиморфизмы (SNP, single nucleotide polymorphism) в ядерном геноме. SNP – это различия в один нуклеотид, появившиеся в результате мутации. Их анализ, как и исследование митохондриальной ДНК и Y-хромосомы, позволяет группировать геномы в классы с общими SNP (гаплогруппы). Поскольку вероятность возникновения точечных мутаций известна, исследователи могут по количеству SNP определять приблизительное время расхождения разных линий их носителей. Изучение SNP последние годы становится все более популярным методом исследований, в которых данные генетики применяются для установления путей древних миграций и родства различных этносов. О некоторых таких работах можно прочитать в наших очерках «Генетика подтверждает Геродота», «Гены в Новом Свете» и «Генетическая география Великобритании».
Авторы работы рассмотрели 6876 митохондриальных ДНК, 6079 Y-хромосом и 296 полногеномных SNP-профилей, взятых у представителей всех существующих сейчас балтийских и славянских народов.
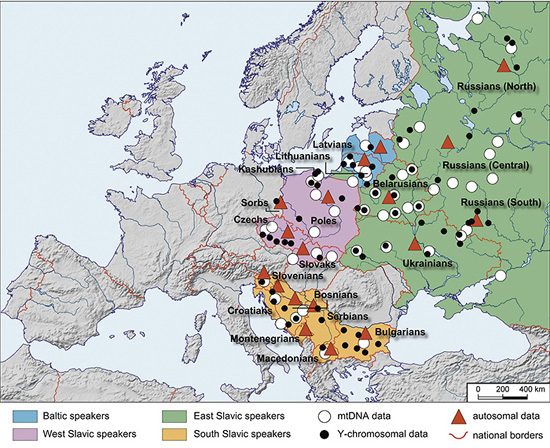
Карта показывает места получения генетического материала (белый круг – митохондриальная ДНК, черный круг – Y-хромосома, красный треугольник – SNP в аутосомах).
Тесную группу образуют восточные славяне (русские, украинцы и белорусы). Только у жителей северных областей России обнаруживается ряд общих генетических признаков с финно-угорскими народами. Геномы западных славян (чехов, словаков, поляков, кашубов, лужичан) более дифференцированы. Чехи и в меньшей степени словаки демонстрируют следы влияния немцев, тогда как поляки ближе к восточным славянам. Поляков даже можно рассматривать в составе единого кластера с русскими, украинцами и белорусами. Южные славяне генетически заметно отличаются от западных и восточных. Среди южных славян в геноме словенцев отмечаются следы взаимодействия с венграми, а в геноме болгар и македонцев – с румынами и греками.
Литовцы и латыши по Y-хромосоме обнаружили сходство со своими соседями эстонцами, а по аутосомальным SNP-профилям – с белорусами. Также в их геноме нашли общие признаки с мордвой – поволжским народом, говорящим на языке финно-угорской группы. Возможно, это объясняется тем, что ранее балтийские языки были распространены гораздо восточнее и легко могли контактировать с поволжскими финскими языками (об этом говорит, например, балтийское происхождение многих топонимов Подмосковья).
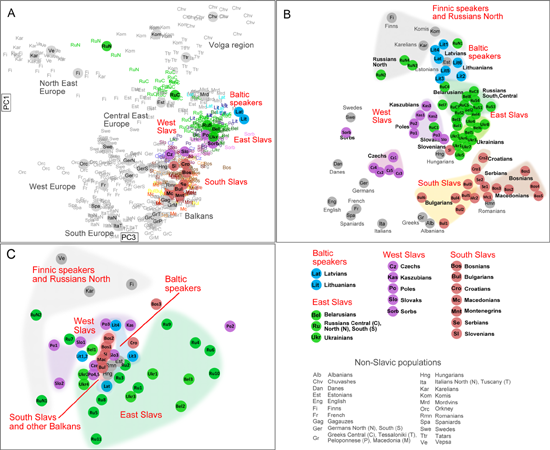
Генофонд носителей балтийских и славянских языков в сравнении с другими народами Европы (A – по SNP-маркерам, B – по Y-хромосоме, C – по митохондриальной ДНК)
Сравнивая данные, полученные на разном генетическом материале, авторы пришли к выводу, что наиболее четко популяции группируются по Y-хромосоме, несколько менее – по однонуклеотидным полиморфизмам, и наименее выражено – по митохондриальной ДНК, хотя и в этом случае можно проследить такие же закономерности.
Стремясь уточнить взаимоотношения восточных и западных славян с одной стороны и южных славян с другой, ученые сравнили степень их близости по фрагментам генома, унаследованным от общего предка (IBD – identical by descent), одновременно они сравнили их и с окружающими народами Европы. В итоге им удалось обнаружить значительную степень генетического сходства этих двух групп славян, но одновременно было выявлено значительное влияние на генофонд западных и восточных славян других народов севера Восточной Европы. Были определены также два типа субстрата – генетических следов дославянского населения в генофонде славян. У западных и восточных славян, например, высока частота гаплогруппы R1a по Y-хромосоме, а у южных – гаплогруппы I2a.
Лингвистическая часть работы, как уже говорилось, основана на лексикостатистическом исследовании балтийских и славянских языков. Лексикостатистика основывается на представлении, что во всех языках существуют слова, которые в ходе эволюции языков сохраняются дольше остальных. К ним относятся названия частей тела (рука, нос, глаз), термины родства (отец, мать), простые действия (идти, есть) и так далее. Список из 110 значений таких слов называют списком Сводеша – в честь основателя метода американского лингвиста Мориса Сводеша. При исследовании для каждого из сопоставляемых языков составляется список слов с этими значениями, а потом для каждой пары языков выясняется доля слов из списка, которые имеют общее происхождение. Например, для украинского и русского языков совпадут слова один, два, три, четыре/чотири, пять / п’ять, широкий, короткий, ухо/вухо, нос/нic, зуб и многие другие, но не совпадут слова много – багато, видеть – бачити, держать – тримати. На основании числа совпадений можно построить генеалогическое древо сравниваемых языков, в котором языки с большим числом общих слов в сводешевских списках окажутся более близко родственными. Поскольку скорость замены лексики из списка считается постоянной, можно определить и время расхождения изучаемых языков (эта часть метода известна под названием глоттохронология). О методе лексикостатистики можно прочитать подробнее в стенограмме лекции Георгия Старостина «Как создается единая классификация языков мира», прочитанной в рамках проекта «Публичные лекции Полит.ру».
Важную роль при лексикостатистике играет отбор материала. Например, в русском языке в качестве «сводешевского» слова нужно брать слово глаз, а не око, так как первое слово будет основным обозначением глаза. Если же исследователь, который мало знаком с русским языком, найдет в словаре слово око и использует при подсчетах его, он получит несколько большее число совпадений с другими языками. Большое число слов в списке позволяет скорректировать ошибку, если она одна, но чем больше их, тем менее надежны итоговые результаты. Другая опасность состоит в том, что значения в списке Сводеша были описаны по-английски, и многие использованные английские слова многозначны и могут иметь несколько альтернативных переводов в исследуемых языках – нужно определить, какие именно слова выбирать для получения сопоставимых списков.
Для решения этих проблем некоторое время назад был создан проект «Глобальной лексикостатистической базы данных» (ГЛБД), участники которого собирают унифицированную и упорядоченную систему списков для различных языков. Именно эти списки были использованы в нынешнем исследовании.
Работавшие над статьей лингвисты использовали 110-словные списки литературных языков: русского, украинского, белорусского, болгарского, македонского, сербохорватского, польского, кашубского, чешского, словацкого, верхнелужицкого, нижнелужицкого, литовского, латышского. Также были проанализированы диалектные лексические списки: владимирских, архангельских и псковских говоров русского языка, галицкого и гуцульского говоров украинского языка, западного диалекта македонского языка. Для внешнего сравнения был взят лексический список немецкого языка.
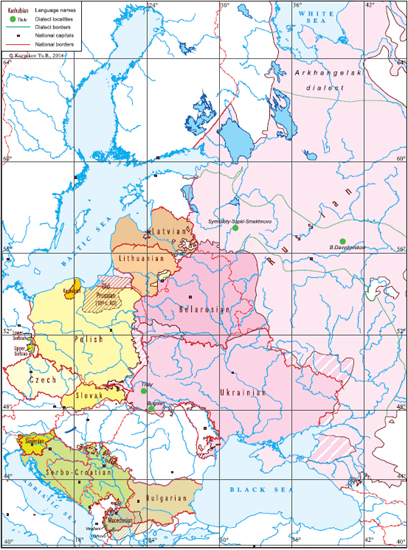
Лингвистическая карта балтийских и славянских языков (отмечены точки, откуда происходит диалектный материал)
Из исследования были исключены данные словенского языка, так как после анализа материала авторы пришли к выводу, что словенский язык, традиционно включаемый в южнославянскую подгруппу, на самом деле изначально относился к западнославянским языкам. Когда в Европу переселились венгры, словене были отрезаны от западнославянских диалектов, и со временем их язык подвергся влиянию соседей – южных славян. Предположение о западнославянской природе словенского языка и ранее высказывались рядом славистов. Для корректного использования данных словенского языка в лексикостатистическом анализе требуется получить надежные данные по словенским диалектам, которые пока отсутствуют.
Существует несколько математических методов, предназначенных для построения родословного древа языков по полученным при лексикостатистическом сопоставлении данным о доле совпадающей лексики в сводешевском списке: метод ближайших соседей, метод максимальной бережливости, метод невзвешенного среднего, метод Монте-Карло с цепями Маркова. Ранее в этом году PLOS One опубликовал статью одного из авторов нынешней публикации Алексея Касьяна (Институт языкознания РАН, РГГУ), посвященную сопоставлению этих методов на материале лезгинских языков. В нынешней статье также были использованы несколько методов построения деревьев, и в итоге было создано «консенсусное» родословное древо, которое авторы посчитали максимально надежным. Были также проведены глоттохронологические подсчеты, позволившие датировать моменты, когда расходились ветви этого древа, то есть происходил распад балто-славянского праязыка, на прабалтийский и праславянский, праславянского на западную, восточную и южную ветви и так далее.
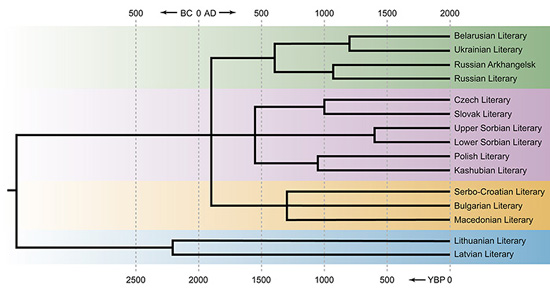
Генеалогическое древо балтийских и славянских языков по данным лексикостатистики
В лингвистической части статьи также анализируются недавние попытки лексикостатистического анализа языков, а именно проекты Automated Similarity Judgment Program и Indo-European Lexical Cognacy Database. Полученные участниками этих проектов результаты настораживали специалистов по сравнительно-историческому изучению славянских языков рядом моментов. Например, в Indo-European Lexical Cognacy Database распад праславянского языка датировался 700 годом – то есть был подозрительно поздним. Рассмотрение славянского лексического материала, использовавшегося в двух этих проектов, показало, что он содержал немалое количество ошибок. Так, в русском списке Indo-European Lexical Cognacy Database в значении «человек» было использовано слово лицо, в значении «мужчина» - слово человек, в значении «год» – слово лета (множественное число от лето). Были найдены также ошибки в белорусском, польском, литовском материале. Иногда в качестве основного слова брался архаизм, почти исчезнувший из данного языка. В результате, например, для белорусского и польского языков на 110 слов списка появилось 18 ложных совпадений. Изучив опыт предшественников, авторы пришли к выводу, что итог лексикостатистического анализа в большей степени зависит от надежности исходного материала, а не от применяемых для его обработки математических методов.
Наконец, в статье проанализирована степень близости результатов лингвистического и генетического исследований балто-славянских популяций. Авторы приводят корреляции между матрицами генетических (по митохондриальной ДНК, Y-хромосоме и аутосомальным SNP), лексикостатистических и географических дистанции среди исследованных популяций. Во всех случаях корреляция весьма высока. Например, корреляция между лингвистическими и генетическими данными составила от 0,74 до 0,78.
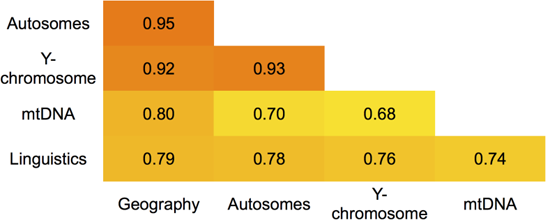
Таблица корреляций
Значение опубликованного исследования не только в новых данных об истории генофонда славян и балтов, полученных на максимальном материале, но и в подтверждении возможности использовать для изучения истории народов как генетические, так и лингвистические методы.
Телеграм: t.me/ainewsline
Источник: polit.ru