Состояние трансферного обучения в НЛП
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2019-08-27 18:20

Этот пост расширяет учебник NAACL 2019 по трансфертному обучению в НЛП .
Этот урок был организован Мэтью Питерсом, Швабха Сваямдиптой, Томасом Вулфом и мной. В этом посте я выделяю ключевые идеи и выводы и предоставляю обновления, основанные на недавней работе. Вы можете посмотреть структуру этого поста ниже:
Слайды, Колабораторный блокнот и код учебника доступны в интернете.
Введение
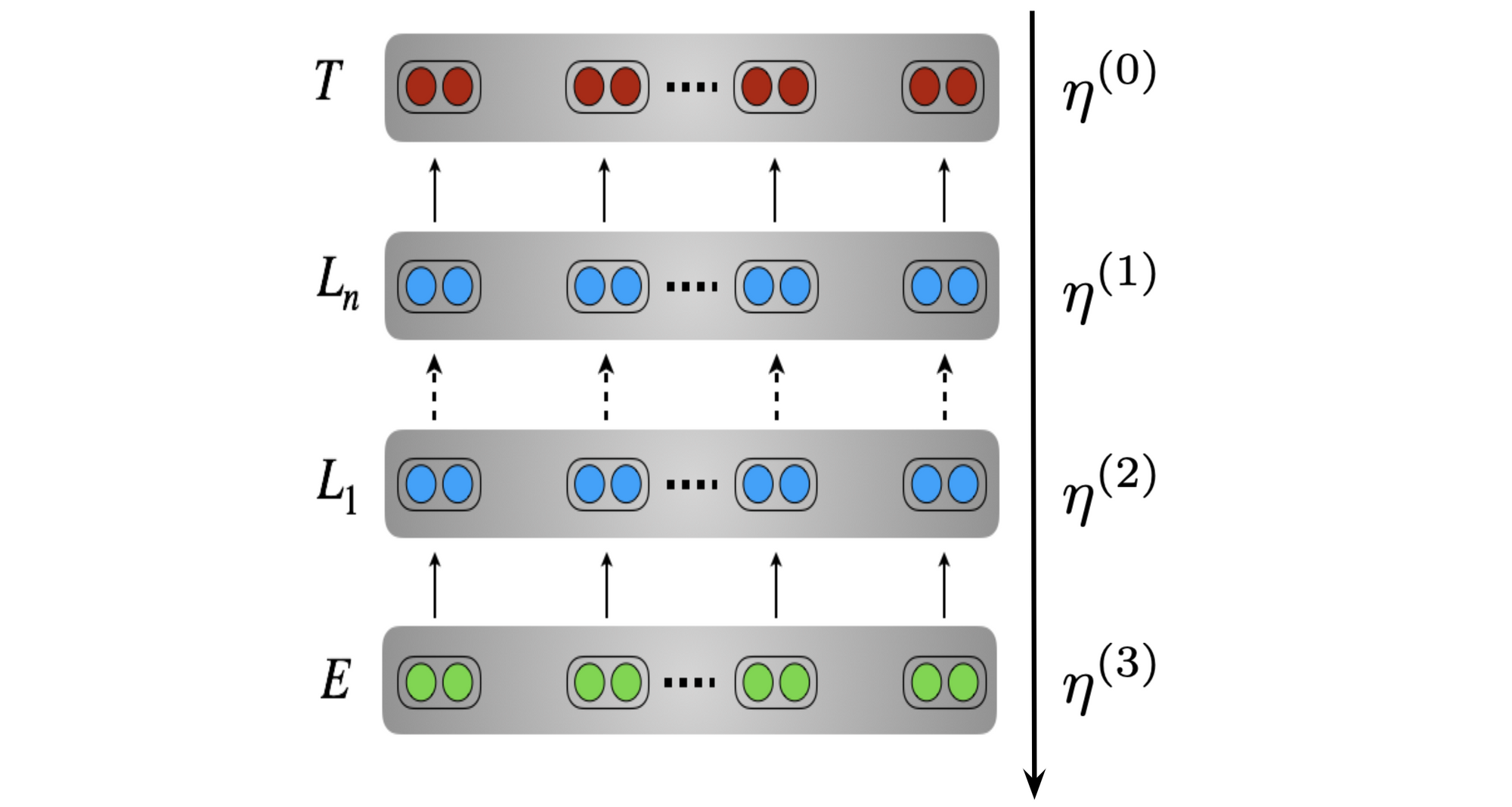
Для получения общего представления о том, что такое обучение по переводу, ознакомьтесь с этим сообщением в блоге . Наше определение перехода на протяжении всего этого поста будет следующим, что иллюстрируется на диаграмме ниже:
Перенос обучения-это средство извлечения знаний из исходной установки и применения их к другой целевой установке.
![]()
За период немногим более года трансфертное обучение в форме предварительно подготовленных языковых моделей стало повсеместным явлением в НЛП и внесло свой вклад в современное состояние по широкому кругу задач. Однако трансфертное обучение не является новым явлением в НЛП. Одним из наглядных примеров является прогресс в решении задачи распознавания именованных сущностей (NER), который можно увидеть ниже.
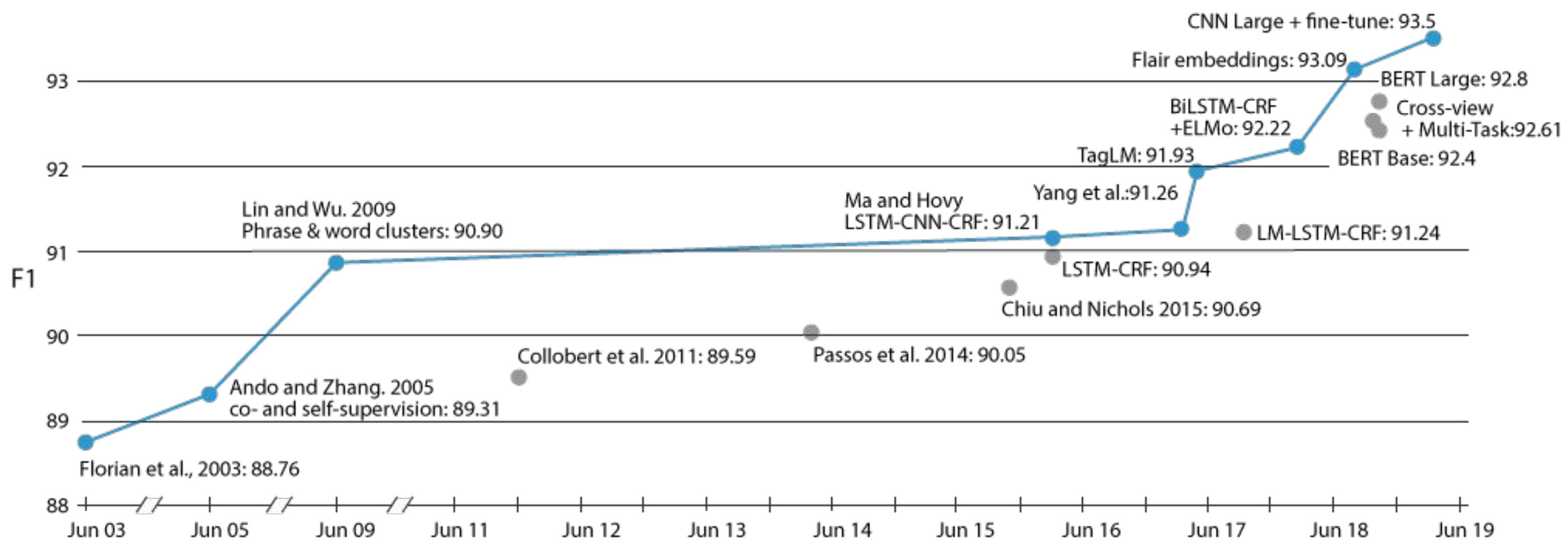
На протяжении всей своей истории большинство крупных улучшений в этой задаче были вызваны различными формами обучения передаче: от раннего самоконтроля обучения с вспомогательными задачами ( Ando and Zhang, 2005 ) и кластерами фраз и слов ( Lin and Wu, 2009 ) до внедрения языковой модели (Peters et al., 2017 ) и претренированные языковые модели ( Peters et al., 2018; Akbik et al., 2018 ; Баевский и др., 2019) последних лет.
Существуют различные типы трансферного обучения, распространенные в современном НЛП. Они могут быть грубо классифицированы по трем измерениям на основе а) того, относятся ли исходные и целевые настройки к одной и той же задаче; и Б) характера исходных и целевых доменов; и в) порядка, в котором изучаются задачи. Таксономия, которая выделяет вариации можно увидеть ниже:
![]()
Последовательное обучение передаче является формой, которая привела к самым большим улучшениям до сих пор. Общая практика заключается в том, чтобы предварительно обучить представления на большом немаркированном текстовом корпусе, используя свой метод выбора, а затем адаптировать эти представления к контролируемой целевой задаче с использованием помеченных данных, как это видно ниже.
Главная тема
Несколько основных тем можно наблюдать в том, как эта парадигма была применена:
От слов к словам-в-контексте с течением времени представления включают больше контекста. Ранние подходы, такие как word2vec ( Миколов и др., 2013) узнал одно представление для каждого слова независимо от его контекста. Более поздние подходы затем масштабировали эти представления до предложений и документов ( Le and Mikolov, 2014 ; Conneau et al., 2017). Современные подходы изучают представления слов, которые изменяются в зависимости от контекста слова ( McCann et al., 2017; Peters et al., 2018).
LM pretraining многие успешные подходы к подготовке кадров основаны на вариантах языкового моделирования (LM). Преимущества LM заключаются в том, что он не требует каких-либо человеческих аннотаций и что многие языки имеют достаточно текста, доступного для изучения разумных моделей. Кроме того, LM является универсальным и позволяет изучать как предложения, так и словесные представления с различными целевыми функциями.
В течение последних лет современные модели НЛП постепенно становились все глубже и глубже. До двух лет назад состояние техники по большинству задач было 2-3-слойным глубоким BiLSTM, с машинным переводом, являющимся выбросом с 16 слоями ( Wu et al., 2016). В отличие от этого, текущие модели, такие как BERT-Large и GPT-2, состоят из 24 трансформаторных блоков, а последние модели еще глубже.
Предварительный тренинг против целевой задачи выбор предварительного тренинга и целевых задач тесно переплетены. Например, представления предложений не полезны для предсказаний на уровне слов, в то время как предварительное обучение на основе интервалов важно для предсказаний на уровне интервалов. В целом, для достижения наилучших целевых показателей, полезно выбрать аналогичную тренировочную задачу.
Предтренировка
Почему языковое моделирование работает так хорошо?
Поразителен поразительный успех предварительно обученных языковых моделей. Одной из причин успеха языкового моделирования может быть то, что это очень трудная задача, даже для людей. Чтобы иметь хоть какой-то шанс на решение этой задачи, от модели требуется изучить синтаксис, семантику, а также определенные факты о мире. При наличии достаточного количества данных, большого количества параметров и достаточного количества вычислений модель может выполнять разумную работу. Эмпирически, языковое моделирование работает лучше, чем другие задачи предварительного обучения, такие как перевод или Автокод ( Zhang et al. 2018; Wang et al., 2019).
Недавний анализ искажения прогностической скорости (PRD) человеческого языка (Hahn and Futrell, 2019 ) предполагает, что человеческий язык—и языковое моделирование—имеет бесконечную статистическую сложность, но его можно хорошо аппроксимировать на более низких уровнях. Это наблюдение имеет два следствия: 1) мы можем получить хорошие результаты со сравнительно небольшими моделями; и 2) существует большой потенциал для масштабирования наших моделей. Как мы увидим в следующих разделах, для обоих выводов у нас есть эмпирические доказательства.
Эффективность образца
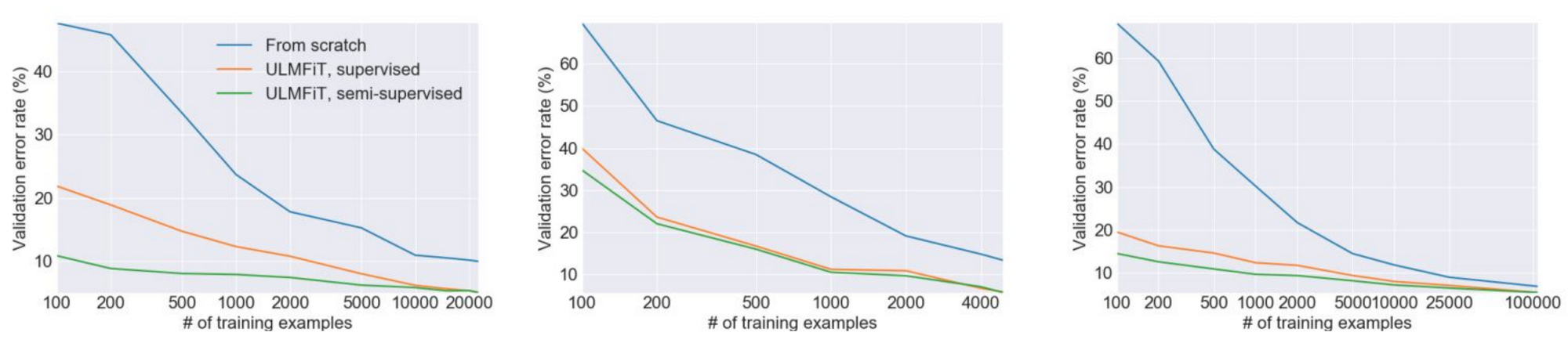
Одним из главных преимуществ предварительного обучения является то, что оно уменьшает потребность в аннотированных данных. На практике часто было показано, что трансфертное обучение обеспечивает аналогичную производительность по сравнению с нетренированной моделью с 10-кратным меньшим количеством примеров или более, как это видно ниже для ULMFiT ( Howard and Ruder, 2018 ).
Scaling up pretraining
Предварительно подготовленные представления, как правило, могут быть улучшены путем совместного увеличения числа параметров модели и количества данных предварительного обучения. Отдача начинает уменьшаться по мере того, как объем данных предварительного тренинга становится огромным. Однако текущие кривые производительности, такие как приведенная ниже, не указывают на то, что мы достигли плато. Таким образом, мы можем ожидать увидеть еще более крупные модели, обученные на большем количестве данных.
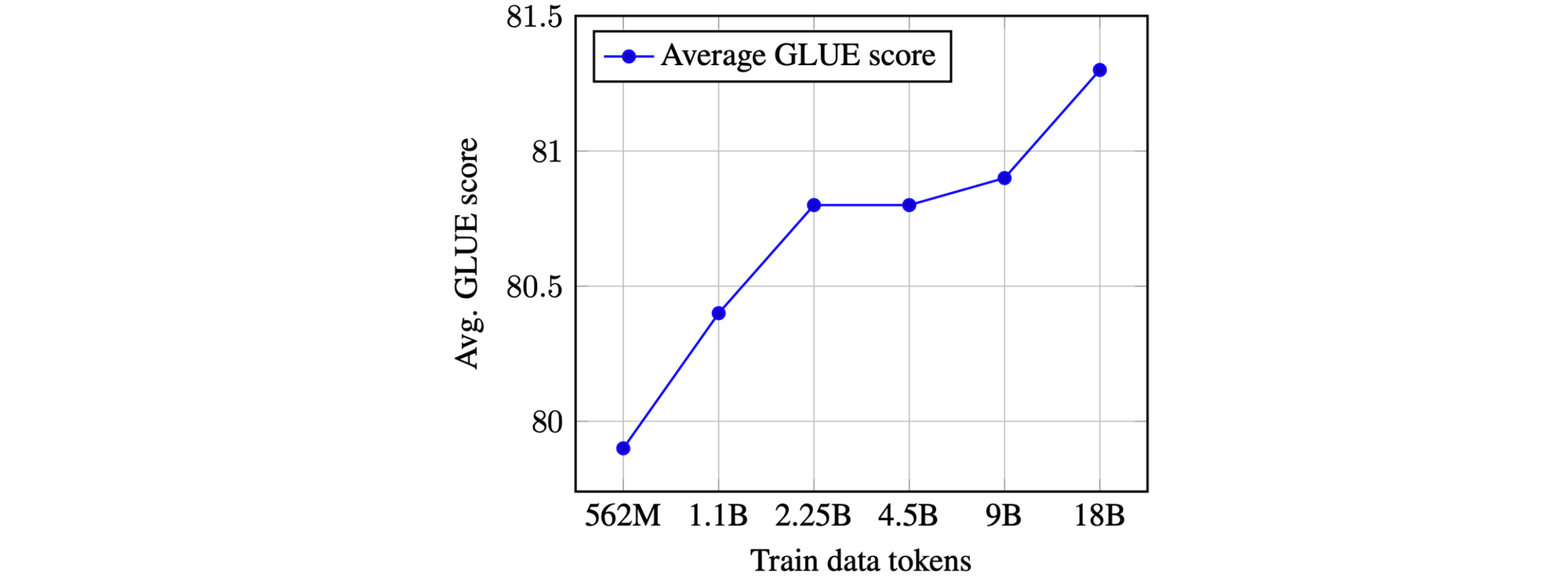
Недавние примеры этой тенденции-ERNIE 2.0, XLNet, GPT-2 8B и RoBERTa . Последний, в частности, считает, что простое обучение BERT для более длительного и большего количества данных улучшает результаты, в то время как GPT-2 8B уменьшает недоумение по набору данных языкового моделирования (хотя и только в сравнительно небольшом коэффициенте).
Кросс-лингвальный тренинг
Одним из главных обещаний предварительного обучения является то, что оно поможет нам преодолеть цифровой языковой разрыв и позволит нам изучать модели НЛП для более чем 6000 языков мира. Большая работа по межъязыковому обучению была сосредоточена на обучении отдельных словесных вложений в разных языках и обучении их выравниванию ( Ruder et al., 2019). Точно так же мы можем научиться выравнивать контекстуальные представления ( Schuster et al., 2019). Другим распространенным методом является совместное использование словаря подслова и обучение одной модели на многих языках ( Devlin et al., 2019 ; Artetxe and Schwenk, 2019; Mulcaire et al., 2019; Lample and Conneau, 2019). Хотя это легко реализовать и является сильной межъязыковой основой, это приводит к недопредставлению языков с низким ресурсом ( Heinzerling and Strube, 2019 ). Многоязычный Берт, в частности, был предметом пристального внимания в последнее время ( Pires et al., 2019 ; Wu and Dredze, 2019). Несмотря на свою сильную нулевую производительность, выделенные одноязычные языковые модели часто конкурентоспособны, будучи при этом более эффективными ( Eisenschlos et al., 2019).
Практическое соображение
Предварительное обучение является экономически интенсивным. Предварительная подготовка модели Transformer-XL style, которую мы использовали в учебнике, занимает 5 ч–20 ч на 8 графических процессорах V100 (несколько дней с 1 V100), чтобы достичь хорошего недоумения. Таким образом, обмен предварительно подготовленными моделями очень важен. Предварительный тренинг является относительно надежным для выбора гиперпараметров-помимо того, что он нуждается в разогреве скорости обучения для трансформаторов. Как правило, ваша модель не должна иметь достаточную емкость для подгонки, если ваш набор данных достаточно велик. Моделирование маскированного языка (как и в BERT) обычно в 2-4 раза медленнее обучается, чем стандартный LM, поскольку маскировка только части слов дает меньший сигнал.
Что же такое в представлении?
Было показано, что репрезентации являются предикативными для некоторых языковых явлений, таких как выравнивания в переводе или синтаксические иерархии. Лучшая производительность была достигнута при предварительной подготовке с синтаксисом; даже когда синтаксис не закодирован явно, представления все еще изучают некоторое понятие синтаксиса ( Williams et al. 2018). Кроме того, недавние работы показали, что знание синтаксиса может быть эффективно перегонено в современные модели ( Kuncoro et al., 2019). Сетевые архитектуры обычно определяют, что находится в представлении. Например, было замечено, что Берт захватывает синтаксис (Tenney et al., 2019 ; Goldberg, 2019). Различные архитектуры демонстрируют различные послойные тенденции с точки зрения того, какую информацию они захватывают ( Liu et al., 2019).
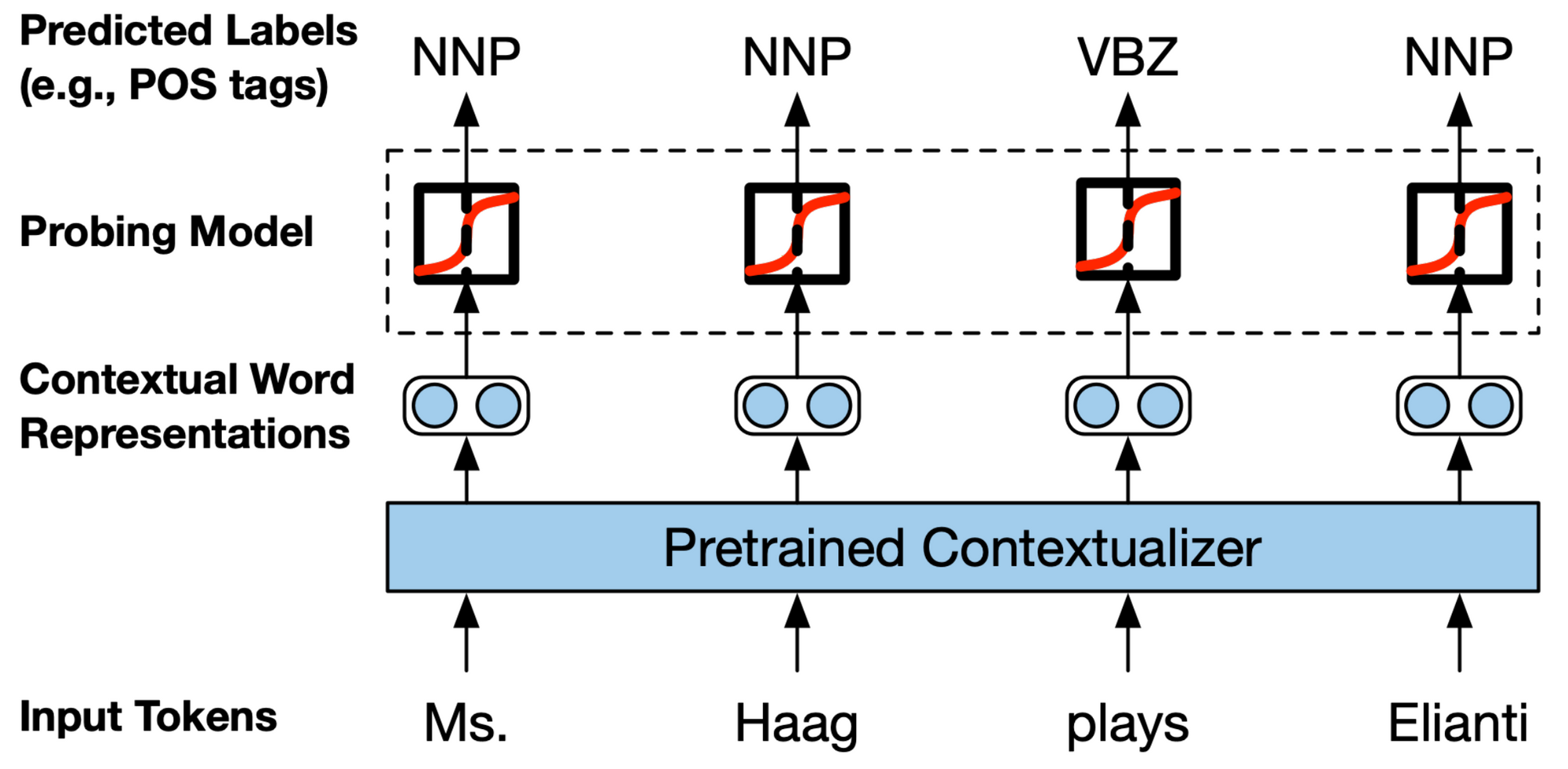
Информация, которую захватывает модель, также зависит от того, как вы смотрите на нее: визуализация активаций или Весов внимания обеспечивает обзор знаний модели с высоты птичьего полета, но фокусируется на нескольких образцах; зонды, которые обучают классификатор поверх изученных представлений, чтобы предсказать определенные свойства (как можно видеть выше), обнаруживают корпусные специфические характеристики, но могут вводить свои собственные предубеждения; наконец, сетевые абляции отлично подходят для улучшения модели, но могут быть специфичными для конкретных задач.
Адаптация
Для адаптации предварительно подготовленной модели к целевой задаче существует несколько ортогональных направлений, по которым мы можем принимать решения: архитектурные модификации, схемы оптимизации и получение большего количества сигнала.
Архитектурные изменения
Для архитектурноакустических изменений, 2 общих варианта мы имеем:
a) сохранить неизменными внутренние части предварительно подготовленной модели это может быть так же просто, как добавить один или несколько линейных слоев поверх предварительно подготовленной модели, что обычно делается с помощью BERT. Вместо этого мы также можем использовать выходные данные модели в качестве входных данных для отдельной модели, что часто полезно, когда целевая задача требует взаимодействия, которые недоступны в предварительно подготовленном внедрении, например представления span или моделирование отношений кросс-предложений.
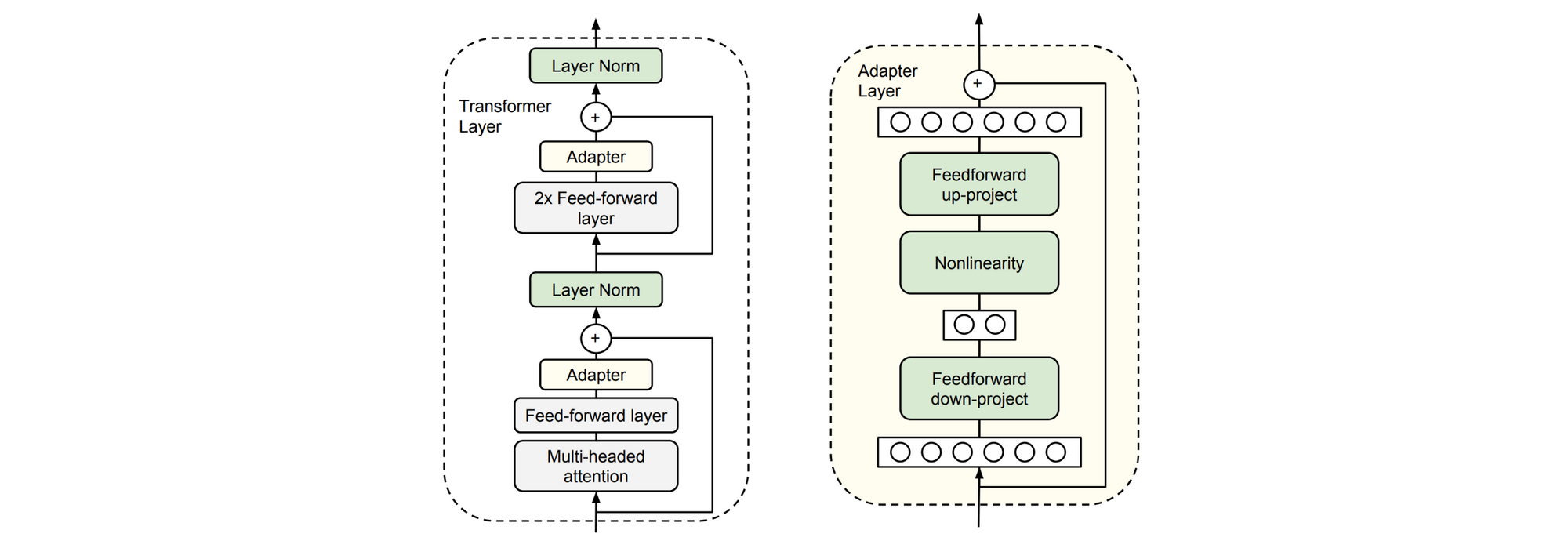
b) изменить внутреннюю архитектуру предварительно подготовленной модели Одна из причин, по которой мы могли бы сделать это, заключается в том, чтобы адаптироваться к структурно отличной целевой задаче, такой как одна с несколькими входными последовательностями. В этом случае мы можем использовать предварительно обученную модель для инициализации как можно большего количества структурно различных моделей целевых задач. Мы также можем захотеть применить специфические для задачи изменения, такие как добавление пропусков или остаточных соединений или внимания. Наконец, изменение параметров целевой задачи может уменьшить число параметров, которые необходимо точно настроить, добавив модули bottleneck ("адаптеры") между слоями предварительно подготовленной модели (Houlsby et al., 2019 ; Stickland and Murray, 2019).
Схемы оптимизации
С точки зрения оптимизации модели, мы можем выбрать, какие веса мы должны обновить и как и когда обновить эти веса.
Какие веса нужно обновить
Для обновления весов мы можем либо настроить, либо не настраивать (предварительно подготовленные веса):
а) не меняйте предварительно подготовленные веса (извлечение признаков) на практике линейный классификатор обучается поверх предварительно подготовленных представлений. Наилучшая производительность обычно достигается при использовании представления не только верхнего слоя, но и при изучении линейной комбинации представлений слоев ( Peters et al., 2018, Ruder et al., 2019). Кроме того, предварительно подготовленные представления могут использоваться в качестве объектов в нисходящей модели. При добавлении адаптеров обучаются только слои адаптеров.
b) изменение предварительно подготовленных Весов (точная настройка) предварительно подготовленные весы используются в качестве инициализации для параметров нисходящей модели. Вся предварительно подготовленная архитектура затем обучается на этапе адаптации.
Как и когда обновить веса
Основная мотивация для выбора заказа и способа обновления весов заключается в том, что мы хотим избежать перезаписи полезной предварительно подготовленной информации и максимизировать положительный перенос. С этим связана концепция катастрофического забывания ( McCloskey & Cohen, 1989 ; French, 1999 ), которая возникает, если модель забывает задачу, на которой она первоначально обучалась. В большинстве настроек мы заботимся только о производительности целевой задачи, но это может отличаться в зависимости от приложения.
Руководящим принципом для обновления параметров нашей модели является их постепенное обновление сверху вниз по времени, интенсивности или по сравнению с предварительно подготовленной моделью:
а) постепенно во времени (замораживание) основная интуиция заключается в том, что обучение всех слоев одновременно на данных различного распределения и задачи может привести к нестабильности и плохим решениям. Вместо этого мы обучаем слои индивидуально, чтобы дать им время адаптироваться к новой задаче и данным. Это восходит к послойному обучению ранних глубоких нейронных сетей ( Hinton et al., 2006; Bengio et al., 2007). Последние подходы ( Felbo et al., 2017 ; Howard and Ruder, 2018; Chronopoulou et al., 2019) главным образом меняют в комбинациях слоев которые натренированы совместно; все тренируют все параметры совместно в конце концов. Для трансформаторных моделей размораживание подробно не исследовалось.
b) постепенно в интенсивности (более низкие показатели обучения) мы хотим использовать более низкие показатели обучения, чтобы избежать перезаписи полезной информации. Более низкие показатели обучения особенно важны на более низких уровнях (поскольку они охватывают более общую информацию), на ранних этапах обучения (поскольку модель все еще нуждается в адаптации к целевому распределению) и на поздних этапах обучения (когда модель близка к конвергенции). Для этого мы можем использовать различительную тонкую настройку ( Howard and Ruder, 2018), что снижает скорость обучения для каждого слоя, как видно ниже. Для поддержания более низких темпов обучения на ранних этапах обучения можно использовать треугольный график скорости обучения, который также известен как разминка скорости обучения в трансформаторах. Liu et al. (2019) недавно предположили, что разминка уменьшает дисперсию на ранней стадии обучения.
c) прогрессивно по сравнению с предварительно подготовленной моделью ( регуляризация) один из способов минимизации катастрофического забывания состоит в том, чтобы поощрять целевые параметры модели оставаться близкими к параметрам предварительно подготовленной модели с использованием термина регуляризации (Wiese et al., Conl 2017, Kirkpatrick et al., PNAS 2017).
Компромиссы и практические соображения
В общем, чем больше параметров вам нужно тренироваться с нуля, тем медленнее будет ваша тренировка. Извлечение признаков требует добавления большего количества параметров, чем точная настройка ( Peters et al., 2019 ), поэтому, как правило, медленнее тренироваться. Однако извлечение функций является более эффективным, когда модель необходимо адаптировать ко многим задачам, так как для этого требуется хранить в памяти только одну копию предварительно подготовленной модели. Адаптеры находят баланс, добавляя небольшое количество дополнительных параметров для каждой задачи.
С точки зрения производительности, ни один метод адаптации не является явно превосходящим в каждой обстановке. Если исходные и целевые задачи отличаются, извлечение объектов представляется предпочтительным ( Peters et al., 2019). В противном случае извлечение функций и их точная настройка часто выполняются аналогично, хотя это зависит от бюджета, доступного для настройки гиперпараметров (точная настройка часто требует более обширного поиска гиперпараметров). Как ни странно, трансформаторы легче поддаются тонкой настройке (менее чувствительны к гиперпараметрам), чем LSTMs, и могут достичь лучшей производительности при тонкой настройке.
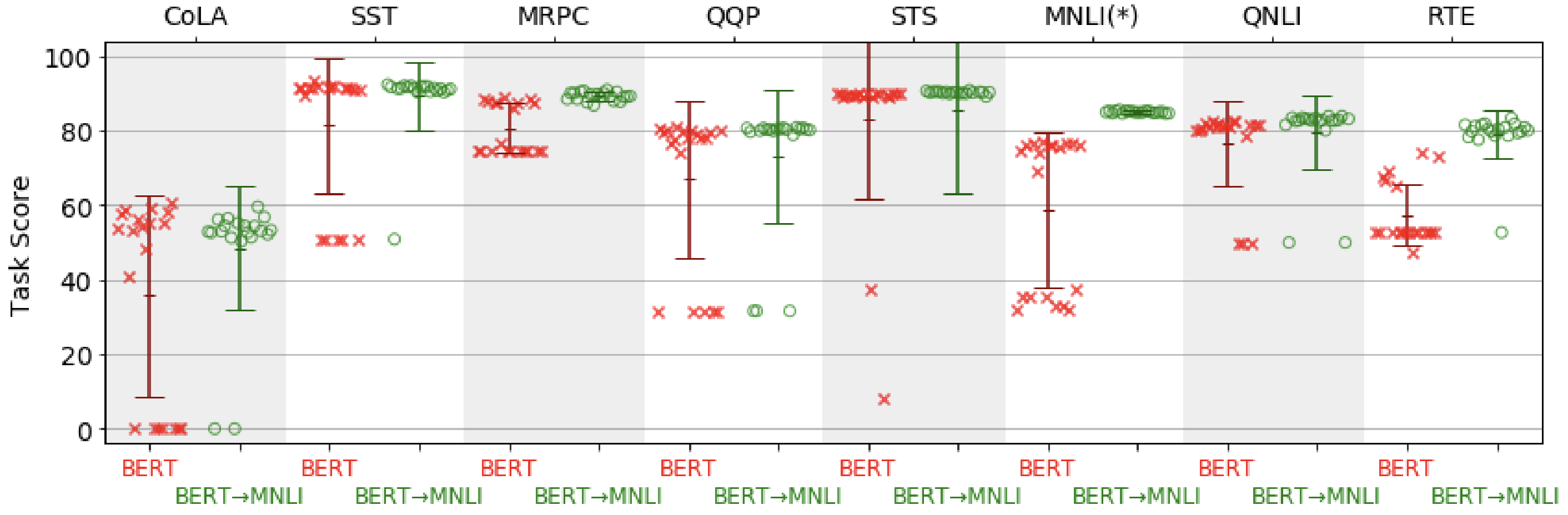
Однако большие предварительно обученные модели (например, BERT-Large) склонны к ухудшению производительности при тонкой настройке на задачах с небольшими наборами обучения. На практике наблюдаемое поведение часто является "включенным-выключенным": модель либо работает очень хорошо, либо не работает вообще, как видно на рисунке ниже. Понимание условий и причин такого поведения является открытым исследовательским вопросом.
Получение большего сигнала
Целевая задача часто является задачей с низким ресурсом. Мы часто можем улучшить производительность обучения передаче, комбинируя разнообразный набор сигналов:
Последовательная адаптация если доступны связанные задачи, мы можем сначала настроить нашу модель на связанную задачу с большим количеством данных, прежде чем настраивать ее на целевую задачу. Это
особенно полезно для задач с ограниченными данными и аналогичных задач (Phang et al., 2018) и повышает эффективность выборки на целевой задаче ( Yogatama et al., 2019).
Многозадачная точная настройка альтернативно, мы также можем совместно настроить модель на связанные задачи вместе с целевой задачей. Связанная с ней задача также может быть неконтролируемой вспомогательной задачей. Языковое моделирование является хорошим выбором для этого и, как было показано, помогает даже без предварительного обучения ( Rei et al., 2017). Соотношение задач может быть дополнительно отожжено, чтобы снять акцент со вспомогательной задачи к концу обучения ( Chronopoulou et al., NAACL 2019). Тонкая настройка языковой модели используется в качестве отдельного шага в ULMFiT ( Howard and Ruder, 2018). В последнее время многозадачная точная настройка привела к улучшениям даже со многими целевыми задачами ( Liu et al., 2019, Wang et al., 2019).
Срез набора данных вместо точной настройки с помощью вспомогательных задач мы можем использовать вспомогательные головки, которые обучаются только на определенных подмножествах данных . С этой целью мы сначала проанализируем ошибки модели, используем эвристику для автоматического определения сложных подмножеств обучающих данных, а затем обучим вспомогательные головки совместно с основной головкой.
Полууправляемое обучение мы также можем использовать методы полууправляемого обучения, чтобы сделать прогнозы нашей модели более согласованными, возмущая немаркированные примеры. Возмущение может быть шумом, маскировкой ( Clark et al., 2018), или увеличение данных, например обратный перевод ( Xie et al., 2019).
Ансамблирование для повышения производительности прогнозы моделей, настроенных с различными гиперпараметрами, настроенными с различными предварительно подготовленными моделями или обученными на разных целевых задачах или разбиениях набора данных, могут быть объединены.
Дистилляция наконец, большие модели или ансамбли моделей могут быть дистиллированы в одну, меньшую модель. Модель также может быть намного проще (Tang et al., 2019) или имеют другое индуктивное смещение ( Kuncoro et al., 2019). Многозадачная тонкая настройка может также сочетаться с дистилляцией ( Clark et al., 2019).
Нисходящие приложения
Предварительная подготовка крупномасштабных моделей является дорогостоящей не только с точки зрения вычислений, но и с точки зрения воздействия на окружающую среду ( Strubell et al., 2019). Когда это возможно, лучше всего использовать модели с открытым исходным кодом. Если вам нужно обучить свои собственные модели, пожалуйста, поделитесь своими предварительно обученными моделями с сообществом.
Фреймворки и библиотеки
Для совместного использования и доступа к предварительно подготовленным моделям доступны различные варианты:
Концентраторы концентраторы-это центральные репозитории, которые предоставляют общий API для доступа к предварительно подготовленным моделям. Два наиболее распространенных концентратора-это концентратор TensorFlow и концентратор PyTorch . Концентраторы, как правило, просты в использовании; однако они действуют больше как черный ящик, поскольку исходный код модели не может быть легко доступен. Кроме того, изменение внутренних компонентов предварительно подготовленной архитектуры модели может быть затруднено.
Автор выпустил файлы контрольных точек Checkpoint, как правило, содержат все веса предварительно подготовленной модели. В отличие от модулей концентратора, график модели все еще должен быть создан, и веса модели должны быть загружены отдельно. Таким образом, файлы контрольных точек сложнее использовать, чем модули концентратора, но обеспечивают полный контроль над внутренними компонентами модели.
Сторонние библиотеки некоторые сторонние библиотеки, такие как AllenNLP , fast.ai , и pytorch-трансформаторы обеспечивают легкий доступ к pretrained моделям. Такие библиотеки, как правило, позволяют быстро экспериментировать и охватывают множество стандартных вариантов использования для обучения передаче.
Для получения примеров того, как такие модели и библиотеки могут быть использованы для последующих задач, посмотрите фрагменты кода в слайдах , Colaboratory notebook и коде .
Открытые проблемы и будущие направления
Есть много открытых проблем и интересных будущих направлений исследований. Ниже приведен только обновленный выбор. Для получения дополнительных указателей, взгляните на слайды .
Недостатки предварительно подготовленных языковых моделей
Предварительно обученные языковые модели все еще плохо справляются с мелкозернистыми лингвистическими задачами ( Liu et al., 2019), иерархическое синтаксическое рассуждение ( Kuncoro et al., 2019 ), и здравый смысл (когда вы на самом деле затрудняете его; Zellers et al., 2019). Они все еще терпят неудачу в создании естественного языка, в частности, поддерживая долгосрочные зависимости, отношения и когерентность. Они также имеют тенденцию перестраиваться для поверхностной формы информации при тонкой настройке и все еще могут рассматриваться в основном как "быстрые поверхностные учащиеся".
Как мы уже отмечали выше, особенно крупные модели, которые точно настроены на небольших объемах данных, трудно оптимизировать и страдают от высокой дисперсии. Современные претренированные языковые модели также очень велики. Дистилляция и обрезка-это два способа справиться с этим.
Предтренировочные задания
Хотя задача моделирования языка показала свою эффективность эмпирически, она имеет свои недостатки. В последнее время мы увидели, что двунаправленный контекст и моделирование непрерывных последовательностей слов особенно важны. Возможно, самое главное, что языковое моделирование поощряет акцент на синтаксисе и словесных ко-вхождениях и только дает слабый сигнал для захвата семантики и долгосрочного контекста. Мы можем черпать вдохновение из других форм самонаблюдения. Кроме того, мы можем разработать специализированные задачи предварительного обучения, которые явно изучают определенные отношения ( Joshi et al., 2019, Sun et al., 2019).
В целом, трудно выучить определенные типы информации из сырого текста. Последние подходы включают структурированные знания ( Zhang et al., 2019; Logan IV et al., 2019) или использовать несколько модальностей (Sun et al., 2019; Lu et al., 2019 ) как два потенциальных способа смягчения этой проблемы.
Телеграм: t.me/ainewsline
Источник: ruder.io