Понимание показателей оценки ML-точности и отзыва
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2019-08-19 00:58
Жаргон мира машинного обучения имеет решающее значение, чтобы показать, насколько хорошо работает ваша модель
Прикосновение к базе, цитирование номера парка мяча, удар по нему из парка, это совершенно новая игра в мяч-все это примеры жаргона, заимствованного из мира бейсбола и широко используемого (или неправильно используемого в некоторых случаях) в корпоративном мире.
Мир машинного обучения аналогичным образом использует набор терминов регулярно, чтобы указать, насколько хорошо работают модели. Возникает вопрос-зачем нам нужно что-то еще, кроме термина точность? Точность просто определяется как
![]()
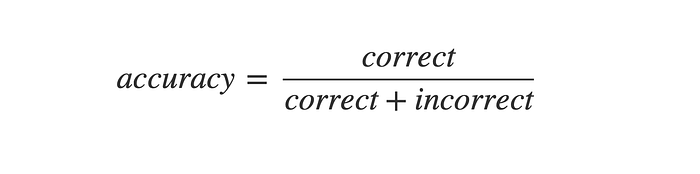
Нет. правильных прогнозов, деленных на общее количество прогнозов
Теперь представьте, что у онколога, специалиста по раку молочной железы, 1000 пациентов. Он решает объявить всех своих пациентов свободными от рака, но позже узнает, что у 3 из них действительно был рак. Для врача это все еще означает точность 99,7%, но для этих 3 пациентов результаты очень тяжелые. Таким образом, это ловушка для использования только точности в качестве показателя успеха.
Такие "наивные" результаты получаются, когда мы сталкиваемся с несбалансированным набором данных. Несбалансированный набор данных-это тот, который имеет слишком мало примеров одного вида.
Использование точности и отзыва в реальном мире
Точность, отзывчивость, чувствительность и специфичность-это термины, которые помогают нам распознать это наивное поведение. Обычно команды ML в таких компаниях, как Microsoft, Amazon, просят своих сотрудников цитировать номера PR (точность и отзыв) или цитировать чувствительность и специфичность результатов.
Эти цифры помогают нам понять, что актуально в данных
Давайте разберемся с примером. Допустим, наш онколог лечит 1000 пациентов.
Он заявляет, что 950 из них свободны от рака. При этом он делает 10 ошибок. 940 из них он правильно диагностирует, чтобы быть свободным от рака. Несчастные 10 имеют рак, но избежать внимания врача.
Он диагностирует оставшиеся 50, чтобы иметь рак. Из них только 5 пациентов действительно имеют рак. Остальные 45 пациентов не имеют рака, но были неправильно идентифицированы как раковые больные.
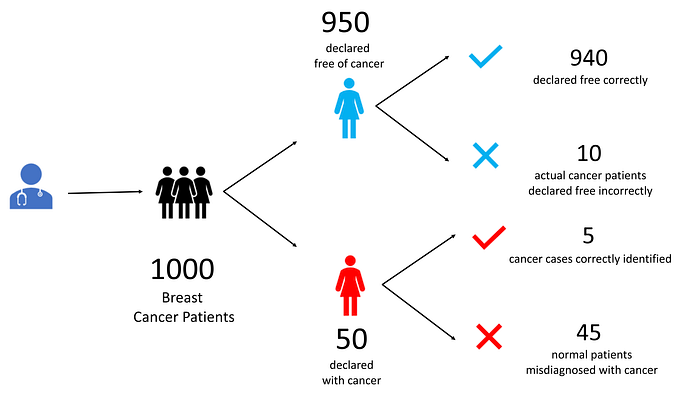
В конце концов у нас есть 4 набора пациентов. Давайте обозначим все эти 4 вида пациентов.
Истинно положительные (ТП) -5 пациентов, которые дали положительный результат на рак правильно
Ложные срабатывания (FP) -45 здоровых пациентов, которые тестируются положительно неправильно
Истинно отрицательные (Теннесси) — 940 здоровых пациентов, который испытал недостаток для Рака правильно
Ложные негативы (FN) — 10 пациентов, которые имели рак, но были объявлены отрицательными для Рака неправильно
Слово "позитивный" означает " да " на вопрос, который мы задаем. например, есть ли у этого человека рак? Положительным было бы, когда мы говорим: "Да, у этого человека рак". Отрицательный тогда будет означать, когда мы говорим, что "у этого человека нет рака".
Давайте рассмотрим эти 4 термина в наглядном виде
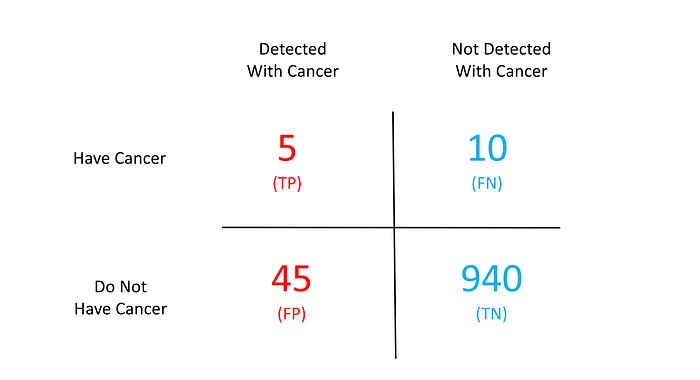
Приведенная выше таблица широко известна как матрица путаницы. Запутался, а? Не быть Эта матрица становится решением наших проблем. Учитывая эту матрицу, мы можем легко вычислить все термины, о которых мы говорили до сих пор.
Сначала давайте посмотрим, насколько точным был доктор. Количество правильных решений, принятых доктором, обозначено как «истинно».
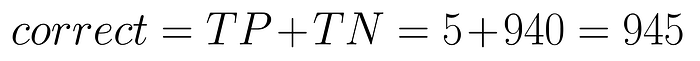
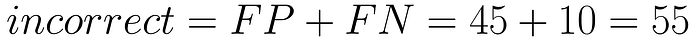
Учитывая эти цифры, наша точность составляет 94,5%
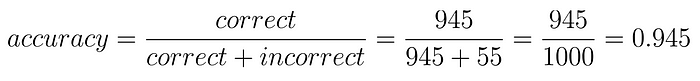
Несмотря на то, что это кажется большим числом, он все еще оставляет много пациентов, восприимчивых к экстремальным потерям. Возьмем, к примеру, ложноотрицательных (FN) пациентов. Эти 10 человек были бы освобождены, что врач дал им чистый чит, в то время как рак будет причинять вред в то же время.
Именно здесь приведенная выше терминология приходит нам на помощь.
Точность говорит нам, насколько важны положительные обнаружения. Чем выше точность, тем лучше наш механизм обнаружения. например, в нашем примере точность составляет всего 10%, что очень плохо. Мы неправильно классифицируем многих здоровых пациентов как больных раком.

Точность-это только часть картины. Другой способ взглянуть на наши данные - это вспомнить. Вспоминание-это то же самое, что и чувствительность.
Они говорят нам, какой процент фактических положительных результатов обнаружен. т. е. какой процент реальных онкологических больных выявляется. Он вычисляется путем взятия отношения правильно идентифицированных больных раком (истинные положительные) к общему числу больных раком (истинные положительные + ложные отрицательные).

Это означает, что мы можем правильно определить только 33% от общего числа онкологических больных. Это плохо!

Специфичность говорит нам, насколько хороша система при удалении ложных тревог. Он вычисляется путем взятия отношения пациентов, которые правильно обнаружены, чтобы не иметь рака (истинные негативы) ко всем пациентам, которые не имеют рака (истинные негативы + ложные положительные).

Мы можем отсеять ложные срабатывания в 99,5% случаев. Это очень хорошо.
Так что же говорят нам эти цифры?

Высокая точность + высокий отзыв-модель прогнозирования (т. е. врач в нашем случае) очень надежна. Модель не ошибается в классификации здоровых пациентов И не оставляет без внимания больных раком
Низкий отзыв + высокая точность-это просто означает, что модель очень придирчива. Он не генерирует много ложных срабатываний, но пропускает много реальных пациентов с раком. Такие модели не могут быть использованы для жизненно важных данных, таких как обнаружение рака, идентификация террористов, предотвращение несчастных случаев и т.д.
Высокий отзыв+ низкая точность-модель способна обнаружить большинство положительных моментов хорошо, но в конечном итоге создает много ложных тревог. Такие модели не должны использоваться в тех случаях, когда ложные тревоги имеют огромную стоимость - например, системы посадки самолетов, системы управления толпой, системы прогнозирования войны и т. д. Отметим, что такие модели могут работать в критических жизненных ситуациях. Все же лучше классифицировать несколько здоровых пациентов как больных раком, чем наоборот.
Излишне говорить, что когда оба они низки, модель довольно бесполезна.
Когда мы используем эти показатели?
Дорогостоящие ложные негативы
Допустим, у нас есть больные раком молочной железы. Мы не хотели бы оставить незамеченным ни одного пациента. Мы все еще можем позволить себе иметь некоторые из здоровых, обнаруженных для Рака. Дальнейшие испытания всегда выявляют истинную природу в таких случаях. Но специально для таких сценариев мы должны смотреть как на чувствительность, так и на специфичность и стараться иметь высокую чувствительность.
Дорогостоящие ложные срабатывания
С другой стороны, скажем, у нас есть судья, который решает, должен ли обвиняемый быть наказан или нет. В этом случае мы не можем позволить себе ложные срабатывания. Закон гласит, что”мы можем оставить 10 преступников безнаказанными, но мы не можем осудить невиновного человека". Такие случаи требуют высокой конкретизации.
Неактуально истинно отрицательные
Google показывает нам миллионы результатов для одного поискового запроса. Он очень заботится об истинных положительных результатах (т. е. веб-странице, которая соответствует нашему запросу), но также допускает некоторые ложные положительные результаты (т. е. Результаты поиска, которые не относятся к нашему запросу). Google, конечно, не заботится об истинных негативах (Результаты поиска, которые он не показывал и не имел значения.

TL;DR
Точность-процент правильных прогнозов
Точность - насколько релевантны положительные стороны
Напомним-то же, что и чувствительность
Чувствительность - % от обнаруженных фактических положительных результатов
Специфика — насколько хорошо мы можем избежать ложных тревог
X8 стремится организовать и построить сообщество для ИИ, которое не только является открытым исходным кодом, но и рассматривает этические и политические аспекты этого. Мы публикуем статью о таких упрощенных концепциях ИИ каждую пятницу. Если вам понравилось это или есть какие-то отзывы или последующие вопросы, пожалуйста, прокомментируйте ниже.
Спасибо за чтение!
Телеграм: t.me/ainewsline
Источник: medium.com