Нейросеть от Google AI распознает жесты в реальном времени
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2019-08-22 12:30

Goole AI опубликовали подход для распознавания жестов в реальном времени с камеры телефона. Модель реализована в MediaPipe, открытом фреймворке для обработки видео- и аудиоданных. Текущие state-of-the-art решения нуждаются в вычислительной мощности ПК, а подход от Google выдает результаты в реальном времени на телефоне и масштабируется на несколько рук.
Возможность распознавать форму и движение рук может быть катализатором к улучшению пользовательского опыта для множества приложений. Например, для приложений дополненной реальности. Разработка устойчивой легковесной модели для распознавания рук в реальном времени является нетривиальной задачей.
Предложенный исследователями подход был анонсирован на CVPR 2019 в июне. Этот подход использует нейросетевые модели для предсказания расположения 21 3D точек руки на основе одного кадра.
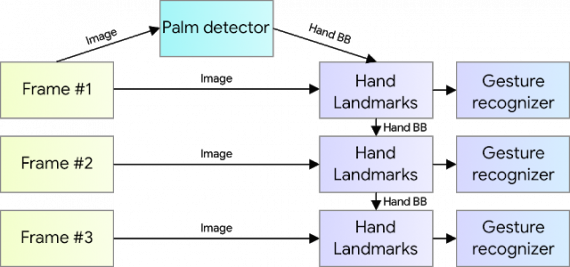
Пайплайн для распознавания рук и жестов
Пайплайн состоит из нескольких моделей, которые работают совместно:
- Модель для распознавания ладони (BlazePalm), которая принимает на вход изображение и выдает границы ладони;
- Модель для разметки ладони, которая принимает на вход обрезанное по границам изображение ладони и выдает 3D точки ладони;
- Детектор жестов, который классифицирует полученную на прошлом этапе последовательность точек ладони по заранее размеченным классам
Исследователи замечают, что правильно обрезанная фотография ладони позволяет значительно сократить необходимость в увеличении размерности данных. Так сеть фокусируется на предсказании координатов точек ладони.
BlazePalm
Чтобы распознать изначальное положение руки на изображении применяется модель BlazePalm. Сначала обучается детектор ладони. Затем используется кодировщик-декодировщик, чтобы учитывать контекст изображения. Focal функция потерь минимизируется во время обучения.
Использование таких техник позволяет достичь точности в 95.7% в предсказании границ ладони.
Распознавание точек ладони
После детектора границ ладони оригинальное изображение обрезается. Детектор точек ладони работает с обрезанным изображением. Модель распознает положение 21 точки ладони и выдает их координаты на выходе. Сеть устойчива к частично видимым рукам и скрещиваниям рук.
Распознавание жестов
Поверх распознанному скелету ладони применяется модель для классификации жестов. Изначально в классы были записаны такие жесты, как палец вверх, кулак, “OK”, “Rock” и “Spiderman”.
Телеграм: t.me/ainewsline
Источник: neurohive.io