Как конвертировать модель из TensorFlow в PyTorch
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2019-08-15 15:46

Разработчики из HuggingFace опубликовали тьюториал по конвертированию предобученных моделей из TensorFlow в PyTorch. Это может пригодиться при попытке внедрить предобученную модель на TF в пайплайн на PyTorch. В качестве примера была взята архитектура GPT-2 от OpenAI.
Посмотреть на структуру модели
Первый шаг — это достать код модели на TensorFlow и чекпоинт предобученной модели. Для GPT-2 это можно получить из официального репозитория OpenAI.
Чекпоинты в TensorFlow обычно состоят из трех файлов с названиями XXX.ckpt.data-YYY, XXX.ckpt.index и XXX.ckpt.meta.
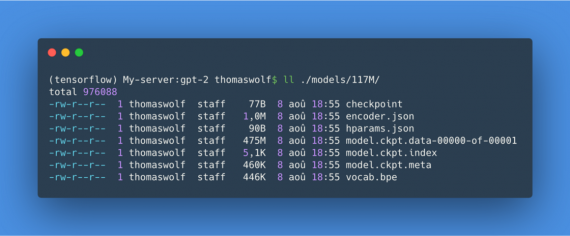
Обученная NLP модель нуждается в словаре, чтобы сопоставлять токены эмбеддингам по индексу. В примере словари лежат в файлах encoder.json and vocab.bpe.
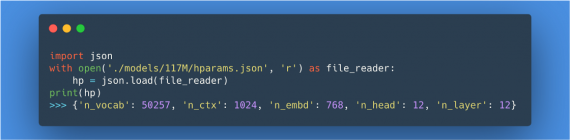
Сначала необходимо посмотреть в файл с гиперпараметрами модели, — hparams.json. Он содержит такие параметры, как количество слоев, механизмов внимание и подобные.
Следующий шаг — посмотреть на структуру модели. Для этого должен быть предустановлен TensorFlow. Необходимо загрузить файл с чекпоинтом и посмотреть на сохраненные переменные. Результат, лист с переменными в чекпоинте, хранится как Numpy array. Эти переменные можно получить с помощью метода tf.train.load_variable(name). В TF переменные организованы как скоупы. В названии переменной содержится тот скоуп, к которому она принадлежит.
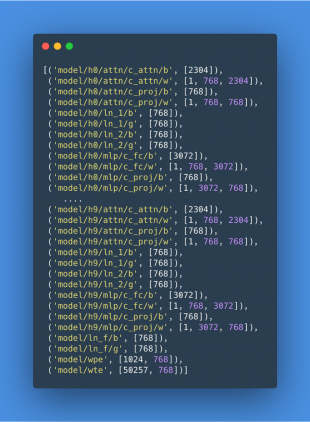
Чтобы собрать PyTorch модель как можно быстрее, можно воспользоваться такой же организацией скоупов: для каждого под-скоупа в TF модели, необходимо создать подкласс с тем же именем в PyTorch.
Это позволит загрузить веса модели через последовательную итерацию над скоупами и классами. GPT-2 имеет 3 модуля в корне модели (в конце листа): model/wte, model/wpe and model/ln_f. Остальная модель составлена из последовательности идентичных модулей hXX, каждый из которых имеет свой модуль с вниманием, полносвязный модуль и 2 модуля с нормализацией слоя.
На этом этапе, когда известна структура модели, можно приступить к построению модели на PyTorch.
Скелет модели на PyTorch
Для начала необходимо повторить основной код модели на PyTorch. Этот этап подразумевает переписывание основного класса модели с TF на PyTorch. Подмодули модели на PyTorch (wte, wpe, h, ln_f) называются идентично скоупам модели в TF. Точно так же переписывается forward pass.
После конвертации модели следует шаг с загрузкой весов. Необходимо обращать внимание на то, что разные функции в TF и PyTorch могут работать с транспонированными весами.
В связи с этим важно проверять результаты обеих моделей на несоответствия. В оригинальном посте исследователи подробно расписывают процесс проверки моделей.
Телеграм: t.me/ainewsline
Источник: neurohive.io