Дискретная математика для WMS: алгоритм сжатия товаров в ячейках (часть 2)
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2019-08-23 00:58
Проведем вычислительный эксперимент по анализу времени работы и точности алгоритма. Обобщим и резюмируем ценный опыт, полученный в ходе решения такой задачи оптимизации и внедрения «интеллектуальных технологий» в бизнес-процессы заказчика.
Статья будет полезна тем, кто внедряет внедряет интеллектуальные технологии, работает в отрасли складской или производственной логистики, а также программистам, которые интересуются приложениями математики в бизнесе и оптимизацией процессов на предприятии.
Часть вводная
Эта публикация продолжает цикл статей, в которых мы делимся своим успешным опытом внедрения алгоритмов оптимизации в складские процессы. Предыдущие публикации:
Как читать статью. Если вы читали предыдущие статьи, то можете сразу переходить к главе «Разработка алгоритма решения задачи», если нет, то описание решаемой проблемы в спойлере ниже.Узкое место в процессах
В 2018 году мы сделали проект по внедрению WMS-системы на складе компании «Торговый дом «ЛД» в г. Челябинске. Внедрили продукт «1С-Логистика: Управление складом 3» на 20 рабочих мест: операторы WMS, кладовщики, водители погрузчиков. Склад средний около 4 тыс. м2, количество ячеек 5000 и количество SKU 4500. На складе хранятся шаровые краны собственного производства разных размеров от 1 кг до 400 кг. Запасы на складе хранятся в разрезе партий из-за необходимости отбора товара по FIFO и «рядной» специфики укладки продукции (пояснение далее).
При проектировании схем автоматизации складских процессов мы столкнулись с существующей проблемой неоптимального хранения запасов. Укладка и хранения кранов имеет, как мы уже сказали, «рядную» специфику. То есть, продукция в ячейке укладывается рядами один на другой в высоту, а возможность поставить штуку на штуку зачастую отсутствует (просто упадут, а вес не маленький). Из-за этого получается, что в одной ячейке штучного хранения может находиться только номенклатура одной партии, иначе старую номенклатуру не вытащить из под новой без «перелапачивания» целой ячейки.
Продукция приходит на склад ежедневно и каждый приход – это отдельная партия. Итого, в результате 1 месяца работы склада создаются 30 отдельных партий, притом, что каждая должна хранится в отдельной ячейке. Товар зачастую отбирается не целыми палетами, а штуками, и в результате в зоне штучного отбора во многих ячейках наблюдается такая картина: в ячейке объемом более 1м3 лежит несколько штук кранов, которые занимают менее 5-10% от объема ячейки (см. рис. 1).

На лицо неоптимальное использование складских мощностей. Чтобы представить масштаб бедствия могу привести цифры: в среднем таких ячеек объемом более 1м3 с «мизерными» остатками в разные периоды работы склада насчитывается от 100 до 300 ячеек. Так как склад относительно небольшой, то в сезоны загрузки склада этот фактор становится «узким горлышком» с сильно тормозит складские процессы приемки и отгрузки.
Идея решения проблемы
Возникла идея: партии остатков с наиболее близкими датами приводить к одной единой партии и такие остатки с унифицированной партией размещать компактно вместе в одной ячейке, или в нескольких, если места в одной не будет хватать на размещение всего количества остатков. Пример такого «сжатия» изображен на рисунке 2.
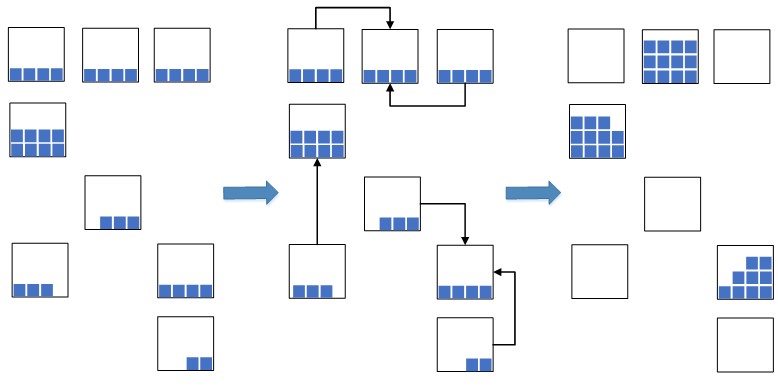
Это позволяет значительно сократить занимаемые складские площади, которые будут использоваться под новый размещаемый товар. В ситуации с перегрузкой складских мощностей такая мера является крайне необходимой, в противном случае свободного места под размещение нового товара может попросту не хватить, что приведет к стопору складских процессов размещения и подпитки и, как следствие, к стопору приемки и отгрузки. Раньше до внедрения WMS-системы такую операцию выполняли вручную, что было не эффективно, так как процесс поиска подходящих остатков в ячейках был достаточно долгим. Сейчас с внедрением WMS-системы решили процесс автоматизировать, ускорить и сделать его интеллектуальным.
Процесс решения такой задачи разбивается на 2 этапа:
- на первом этапе мы находим близкие по дате группы партий для сжатия (этой задаче посвящения первая статья);
- на втором этапе мы для каждой группы партий вычисляем максимально компактное размещение остатков товара в ячейках.
В текущей статье мы закончим с описанием второго этапа процесса решения и рассмотрим непосредственно сам алгоритм оптимизации.
Разработка алгоритма решения задачи
Перед тем как приступать к непосредственному описанию алгоритма оптимизации необходимо сказать об основных критериях разработки такого алгоритма, которые ставились в рамках проекта внедрения WMS-системы.
- Во-первых, алгоритм должен быть прост для понимания. Это естественное требование, так как предполагается, что алгоритм в будущем будет поддерживаться и дорабатываться IT-службой заказчика, которая зачастую далека от математических тонкостей и премудростей.
- Во-вторых, алгоритм должен быть быстрый. В процедуре сжатия участвуют практически все товары на складе (это порядка 3000 позиций) и для каждого товара необходимо решать задачу размерности, примерно, 10х100.
- В-третьих, алгоритм должен вычислять решения близкие к оптимальным.
- В-четвертых, время на проектирование, реализацию, отладку, анализ и внутреннее тестирование алгоритма сравнительно небольшое. Это существенное требование, так как бюджет проекта, в том числе и на эту задачу, был ограничен.
Стоит сказать, что на сегодняшний день математиками для решения задачи Single-Source Capacitated Facility Location Problem было разработано множество эффективных алгоритмов. Рассмотрим основные разновидности имеющихся алгоритмов.
Одни из самых эффективных алгоритмов основаны на подходе так называемых Лагранжевых релаксаций. Как правило, это достаточно сложные алгоритмы, трудные для понимания человека, не погруженного в тонкости дискретной оптимизации. «Черный ящик» со сложными, но эффективными алгоритмами Лагранжевых релаксаций заказчика не устраивал.
Есть достаточно эффективные метаэвристики (что такое метаэвристика читать здесь, что такое эвристика читать здесь), например, генетические алгоритмы, алгоритмы имитации отжига, алгоритмы муравьиной колонии, алгоритмы Табу-поиска и другие (обзор таких метаэвристик на русском можно найти здесь). А вот такие алгоритмы уже устраивали заказчика, так как:
- Способны рассчитывать решения задачи, очень близкие к оптимальным.
- Достаточно просты для понимания, дальнейшей поддержки, отладки и доработки.
- Могут достаточно быстро вычислять решение задачи.
Было решено использовать метаэвристики. Теперь оставалось выбрать один «фреймворк» среди большого «зоопарка» известных метаэвристик для решения задачи Single-Source Capacitated Facility Location Problem. После ознакомления с рядом статей, в которых анализировалась эффективность различных метаэвристик, наш выбор пал на алгоритм GRASP, так как по сравнению с другими метаэвристиками он показывал достаточно неплохие результаты по точности вычисляемых решений задачи, был одним из самых быстрых и, главное, обладал самой простой и прозрачной логикой.
Схема работы алгоритма GRASP применительно к задаче Single-Source Capacitated Facility Location Problem подробна описана в статье. Общая схема работы алгоритма следующая.
- Этап 1. Сгенерировать некоторое допустимое решение задачи жадным рандомизированным алгоритмом.
- Этап 2. Улучшить полученное решение на этапе 1 с помощью алгоритма локального поиска по ряду окрестностей.
- Если условие остановки выполнено, то завершить работу алгоритма, иначе перейти на этап 1. Решение с наименьшим значением общих затрат среди всех найденных решений и будет результатом работы алгоритма.
Условие остановки алгоритма может быть простое ограничение на количество итераций или же ограничение на количество итераций без какого-либо улучшения решения.
Код общей схемы работы алгоритма
int computeProblemSolution(int **aCellsData, int **aMatDist, int cellsNumb, int **aMatSolution, int **aMatAssignmentSolution) { // Матрицы текущего решения на некоторой итерации // Используем int для величин вместимости и объемов. Данные объемов хранятся в базе WMS с точностью 3 знака (кубические дм., кубик со сторонами 10 см), так что мы ничего не потеряем при преобразовании // aMatSolutionIteration - массив контейнеров в решении: // [i][0] номер контейнера, [i][1] текущий объем товара в контейнере, [i][2] текущие затраты и штраф на выбор контейнера и прикрепление к нему ячеек // [i][3] отдельно величина штрафа за превышение объема контейнера int **aMatSolutionIteration = new int*[cellsNumb]; for (int count = 0; count < cellsNumb; count++) aMatSolutionIteration[count] = new int[4]; // aMatAssignmentSolutionIteration - матрица привязки доноров к контейнерам. [i][j] = 1 - если j привязан к i, 0 в противном случае int **aMatAssignmentSolutionIteration = new int*[cellsNumb]; for (int count = 0; count < cellsNumb; count++) aMatAssignmentSolutionIteration[count] = new int[cellsNumb]; const int maxIteration = 10; int iter = 0, recordCosts = 1000000; // определим общий объем товаров, которые необходимо разместить в контейнерах int totalDemand = 0; for (int i = 0; i < cellsNumb; i++) totalDemand += aCellsData[i][1]; while (iter < maxIteration) { // Обнулим массивы временного решения setValueIn2Array(aMatAssignmentSolutionIteration, cellsNumb, cellsNumb, 0); // заполняем нулями матрицу setClearSolutionArray(aMatSolutionIteration, cellsNumb, 4); // Строим решение рандомизированным жадным алгоритмом int *aFreeContainersFitnessFunction = new int[cellsNumb]; // пока пустой массив, так как решение строим с нуля findGreedyRandomSolution(aCellsData, aMatDist, cellsNumb, aMatSolutionIteration, aMatAssignmentSolutionIteration, aFreeContainersFitnessFunction, false); // Улучшаем решение алгоритмом локального поиска по ряду окрестностей improveSolutionLocalSearch(aCellsData, aMatDist, cellsNumb, aMatSolutionIteration, aMatAssignmentSolutionIteration, totalDemand); // Проверяем решение на допустимость (чтобы все ограничения по вместимости контейнеров соблюдались) bool feasible = isSolutionFeasible(aMatSolutionIteration, aCellsData, cellsNumb); // Если решение не допустимо, то исправить решение if (feasible == false) { getFeasibleSolution(aCellsData, aMatDist, cellsNumb, aMatSolutionIteration, aMatAssignmentSolutionIteration); } // Если затраты найденного решения на текущей итерации меньше, чем рекорд, то обновим рекорд и запишем это решение в итоговое int totalCostsIteration = getSolutionTotalCosts(aMatSolutionIteration, cellsNumb); if (totalCostsIteration < recordCosts) { recordCosts = totalCostsIteration; copy2Array(aMatSolution, aMatSolutionIteration, cellsNumb, 3); } iter++; } delete2Array(aMatSolutionIteration, cellsNumb); delete2Array(aMatAssignmentSolutionIteration, cellsNumb); return recordCosts; }- Шаг 1. Для каждой не выбранной на текущий момент ячейки-контейнера вычисляется значение затрат по формуле
где – сумма затрат на выбор контейнера и общих затрат на перемещение товаров из ячеек, которые еще не закреплены ни за каким контейнером, в контейнер . Такие ячеек выбираются так, чтобы суммарный объем товара в них не превышал вместимость контейнера . Ячейки-доноры последовательно выбираются к перемещению в контейнер контейнер в порядке возрастания затрат на перемещение количества товара в контейнер . Выбор ячеек осуществляется пока вместимость контейнера не превышена.
- Шаг 2. Формируется множество контейнеров со значением функции не превосходящих порогового значения , где в нашем случае равно 0,2.
- Шаг 3. Случайным образом из множества выбирается контейнер . ячеек, которые были предварительно выбраны в контейнер на шаге 1, окончательно закрепляются за таким контейнером и в расчетах жадного алгоритма далее не участвуют.
- Шаг 4. Если все ячейки-доноры закреплены за контейнерами, жадный алгоритм прекращает свою работу, иначе переходит снова на шаг 1.
Рандомизированный алгоритм на каждой итерации старается построить решение таким образом, чтобы был баланс между качеством конструируемых им решений, а также их разнообразием. Именно эти два требования для стартовых решений является ключевыми условиями успешной работы алгоритма, поскольку:
- если решения будут плохого качества, то последующее улучшение на этапе 2 не даст существенных результатов, так как даже улучшая плохое решения, мы будем очень часто получать в итоге так же решения плохого качества;
- eсли все решения будут хорошие, но одинаковые, тогда процедуры локального поиска будут сходиться к одному и тому же решению, не далеко не факт, что к оптимальному. Этот эффект называется попаданием в локальный минимум и его следует всегда избегать.
Код жадного рандомизированного алгоритма
void findGreedyRandomSolution(int **aCellsData, int **aMatDist, int cellsNumb, int **aMatSolutionIteration, int **aMatAssignmentSolutionIteration, int *aFreeContainersFitnessFunction, bool isOldSolution) { // количество ячеек в решении int numCellsInSolution = 0; if (isOldSolution) { // если это уже существующее решение, то перезаполним aFreeContainersFitnessFunction // переопределим numCellsInSolution так, чтобы она содержала количество прикрепленных ячеек for (int i = 0; i < cellsNumb; i++) { for (int j = 0; j < cellsNumb; j++) { if (aMatAssignmentSolutionIteration[i][j] == 1) numCellsInSolution++; } } } // множество ячеек, которые планируется прикрепить к контейнеру из массива aFreeContainersFitnessFunction, в случае его выбора // [i][j] = 1, если ячейка j прикрепляется к контейнеру i, 0 иначе int **aFreeContainersAssigntCells = new int*[cellsNumb]; for (int count = 0; count < cellsNumb; count++) aFreeContainersAssigntCells[count] = new int[cellsNumb]; while (numCellsInSolution != cellsNumb) { setValueIn2Array(aFreeContainersAssigntCells, cellsNumb, cellsNumb, 0); // заполняем нулями матрицу // вычислим для каждого не выбранного контейнера значение функции его привлекательности для включение в решение setFreeContainersFitnessFunction(aCellsData, aMatDist, cellsNumb, aFreeContainersFitnessFunction, aFreeContainersAssigntCells); // формируем множество контейнеров, удовлетворяющих пороговому критерию // и случайным образом выбираем контейнер из множества, сформированного по пороговому критерию и включаем его в решение int selectedRandomContainer = selectGoodRandomContainer(aFreeContainersFitnessFunction, cellsNumb); // включим контейнер и прикрепленные к нему ячейки в решение aMatSolutionIteration[selectedRandomContainer][0] = selectedRandomContainer; aMatSolutionIteration[selectedRandomContainer][1] = 0; aMatSolutionIteration[selectedRandomContainer][2] = aCellsData[selectedRandomContainer][2]; for (int j = 0; j < cellsNumb; j++) { if (aFreeContainersAssigntCells[selectedRandomContainer][j] == 1) { aMatAssignmentSolutionIteration[selectedRandomContainer][j] = 1; aMatSolutionIteration[selectedRandomContainer][1] += aCellsData[j][1]; aMatSolutionIteration[selectedRandomContainer][2] += aMatDist[selectedRandomContainer][j]; aMatSolutionIteration[selectedRandomContainer][3] = 0; aFreeContainersFitnessFunction[j] = 10000; numCellsInSolution++; } } } delete2Array(aFreeContainersAssigntCells, cellsNumb); delete[] aFreeContainersFitnessFunction; } void setFreeContainersFitnessFunction(int **aCellsData, int **aMatDist, int cellsNumb, int *aFreeContainersFitnessFunction, int **aFreeContainersAssigntCells) { // массив ячеек, упорядоченных по возрастанию удаленности от текущего контейнера i // [0][k] - расстояние от ячейки до текущего контейнера, [1][k] - номер ячейки int **aCurrentDist = new int*[2]; for (int count = 0; count < 2; count++) aCurrentDist[count] = new int[cellsNumb]; for (int i = 0; i < cellsNumb; i++) { // 10000 - если ячейка уже выбрана в решение, то она не перевыбирается на этом этапе if (aFreeContainersFitnessFunction[i] >= 10000) continue; // текущий общий объем товаров в контейнере int containerCurrentVolume = aCellsData[i][1]; // общие затраты на выбор контейнера int containerCosts = aCellsData[i][2]; // число ячеек-доноров, прикрепленных к контейнеру i int amountAssignedCell = 0; setCurrentDist(aMatDist, cellsNumb, aCurrentDist, i); for (int j = 0; j < cellsNumb; j++) { int currentCell = aCurrentDist[1][j]; if (currentCell == i) continue; if (aFreeContainersFitnessFunction[currentCell] >= 10000) continue; if (aCellsData[i][0] < containerCurrentVolume + aCellsData[currentCell][1]) continue; aFreeContainersAssigntCells[i][currentCell] = 1; containerCosts += aCurrentDist[0][j]; containerCurrentVolume += aCellsData[currentCell][1]; amountAssignedCell++; } //товар в контейнере в любом случае назначаем в тот же контейнер (то есть он остается где был) if (aCellsData[i][1] > 0) { aFreeContainersAssigntCells[i][i] = 1; amountAssignedCell++; } // если количество потенциально прикрепляемых ячеек больше 1 (то есть мы уменьшаем количество ячеек), то тогда увеличим привлекательность такого решения // по сравнению с теми решениями где количество прикрепляемых ячеек равно 1. // таким образом мы сначала отбираем контейнеры с наибольшим количеством ячеек. В противном случае может получиться ситуация, когда выбор маленького контейнера // где уже находится товар (прикрепляется сам к себе) будет более привлекательным чем выбор большого контейнера к которому прикрепляются несколько ячеек. // Если выбрать такой маленький контейнер в самом начале (и исключить его из дальнейшего рассмотрения), то мы исключаем возможность дальнейшее назначение его // в другие контейнеры, а значит исключаем возможность уменьшения количество контейнеров и построения более качественного жадного решения. if (amountAssignedCell > 1) amountAssignedCell *= 10; if (amountAssignedCell > 0) aFreeContainersFitnessFunction[i] = containerCosts / amountAssignedCell; else aFreeContainersFitnessFunction[i] = 10000; } delete2Array(aCurrentDist, 2); } int selectGoodRandomContainer(int *aFreeContainersFitnessFunction, int cellsNumb) { int minFit = 10000; for (int i = 0; i < cellsNumb; i++) { if (minFit > aFreeContainersFitnessFunction[i]) minFit = aFreeContainersFitnessFunction[i]; } int threshold = minFit * (1.2); // 20 % увеличение стоимости решение это порог // массив номеров контейнеров удовлетворяющих пороговому критерию int *aFreeContainersThresholdFitnessFunction = new int[cellsNumb]; int containerNumber = 0; for (int i = 0; i < cellsNumb; i++) { if (threshold >= aFreeContainersFitnessFunction[i] && aFreeContainersFitnessFunction[i] < 10000) { aFreeContainersThresholdFitnessFunction[containerNumber] = i; containerNumber++; } } int randomNumber = rand() % containerNumber; int randomContainer = aFreeContainersThresholdFitnessFunction[randomNumber]; delete[] aFreeContainersThresholdFitnessFunction; return randomContainer; }- Шаг 1. Для текущего решения строятся все «соседние» решения по некоторому виду окрестности , , ..., и для каждого «соседнего» решения вычисляется значение общих затрат.
- Шаг 2. Если среди соседних решений нашлось более лучшее решение , чем изначальное решение , то полагается равным и алгоритм переходит на шаг 1. Иначе, если среди соседних решений не нашлось лучшего решения, чем изначальное, тогда вид окрестности меняется на новый, ранее не рассмотренный, и алгоритм переходит на шаг 1. Если же все доступные виды окрестности рассмотрены, но не удалось найти решение лучше, чем изначальное, алгоритм завершает свою работу.
Виды окрестностей выбираются последовательно из следующего стека: , , , , . Виды окрестной делятся на 2 типа: первый тип (окрестности , , ), где множество контейнеров не меняется, а только меняются варианты прикрепления ячеек-доноров; второй тип (окрестности , ), где меняются не только варианты прикрепления ячеек к контейнерам, но и само множество контейнеров.
Обозначим — количество элементов в множестве . Ниже на рисунках изображены варианты окрестностей первого типа.

Окрестность (или shift окрестность): содержит все варианты решения задачи, которые отличаются от исходного изменением прикрепления только одной ячейки-донора к контейнеру. Размер окрестности не более вариантов.
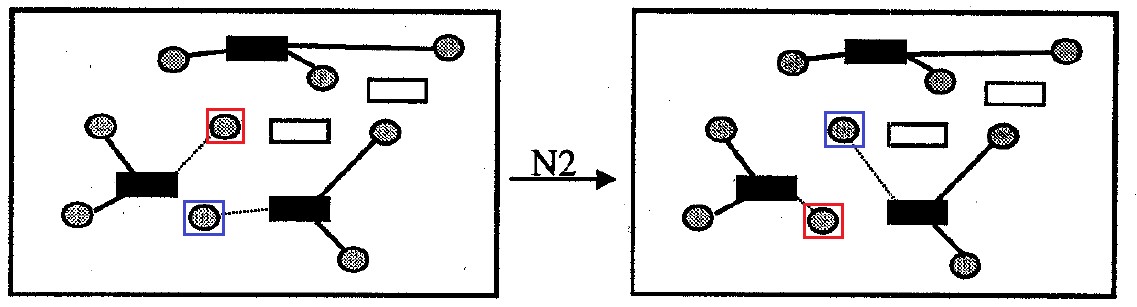
Код алгоритма локального поиска по окрестности N1
void findBestSolutionInNeighborhoodN1(int **aCellsData, int **aMatDist, int cellsNumb, int **aMatSolutionIteration, int **aMatAssignmentSolutionIteration, int totalDemand, bool stayFeasible) { // Значения для найденного рекордного решения в окрестности int recordDeltaCosts, recordCell, recordNewContainer, recordNewCosts, recordNewPenalty, recordOldContainer, recordOldCosts, recordOldPenalty; do { recordDeltaCosts = 10000; int totalContainersCapacity = 0; for (int i = 0; i < cellsNumb; i++) if (aMatSolutionIteration[i][1] > 0) totalContainersCapacity += aCellsData[i][0]; // перебираем все ячейки-доноры for (int j = 0; j < cellsNumb; j++) { // Получим текущий контейнер, к которому прикреплена ячейка j int currentContainer; for (int i = 0; i < cellsNumb; i++) { if (aMatAssignmentSolutionIteration[i][j] == 1) { currentContainer = i; break; } } // получим число ячеек, которые прикреплены к контейнеру j (если прикреплены вообще) int numbAssignedCells = 0; if (aMatSolutionIteration[j][0] >= 0) { for (int i = 0; i < cellsNumb; i++) { if (aMatAssignmentSolutionIteration[j][i] == 1) { numbAssignedCells = i; } } } else { numbAssignedCells = 0; } // Если остатки ячейки j размещаются сами в себя и есть другие ячейки, которые прикреплены к контейнеру j, то такую ячейку исключаем из рассмотрения // это необходимо чтобы избежать "чехорды" по словам заказчика и упрощает физическое выполнение складского процесса сжатия остатков, когда есть сжатие партий if (j == currentContainer && numbAssignedCells > 1) { continue; } // текущее значение общей вместимости контейнеров с учетов перестановок int currentTotalContainersCapacity = totalContainersCapacity - aCellsData[currentContainer][0]; // Получаем затраты, которые мы экономим, если не будем перемещать остатки из ячейки j в тукущий контейнер int currentCosts = aMatDist[currentContainer][j]; // Если после отмены перемещения остатков из ячейки j в текущий контейнер у нас текущий контейнер стал пустой, то учтем эту экономию затрат if (aMatSolutionIteration[currentContainer][1] - aCellsData[j][1] == 0) currentCosts += aCellsData[currentContainer][2]; // если после отмены перемещения остатков из ячейки j в текущий контейнер у нас величина штрафа уменьшилась, то учтем эту экономию затрат int currentPenelty = getPenaltyValueForSingleCell(aCellsData, aMatSolutionIteration, currentContainer, j, 0); currentCosts += currentPenelty; for (int i = 0; i < cellsNumb; i++) { if (i == currentContainer) continue; if (stayFeasible) { if (max(0, aMatSolutionIteration[i][1]) + aCellsData[j][1] > aCellsData[i][0]) continue; } else { if (currentTotalContainersCapacity + aCellsData[i][0] < totalDemand) continue; } // новые затраты на перемещение int newCosts = aMatDist[i][j]; // новые затраты на выбор контейнера if (aMatSolutionIteration[i][0] == -1) newCosts += aCellsData[i][2]; // новые затраты на штраф за превышение объема int newPenalty = getPenaltyValueForSingleCell(aCellsData, aMatSolutionIteration, i, j, 1); newCosts += newPenalty; int deltaCosts = newCosts - currentCosts; if (deltaCosts < 0 && deltaCosts < recordDeltaCosts) { recordDeltaCosts = deltaCosts; recordCell = j; recordNewContainer = i; recordNewCosts = newCosts; recordNewPenalty = newPenalty; recordOldContainer = currentContainer; recordOldCosts = currentCosts; recordOldPenalty = currentPenelty; } } } // если улучшение произошло, то заменим текущее решение на рекордное if (recordDeltaCosts < 0) { // уберем из текущего решения информацию о назначении старой ячейки в старый контейнер aMatSolutionIteration[recordOldContainer][1] -= aCellsData[recordCell][1]; aMatSolutionIteration[recordOldContainer][2] -= recordOldCosts; if (aMatSolutionIteration[recordOldContainer][1] == 0) aMatSolutionIteration[recordOldContainer][0] = -1; aMatSolutionIteration[recordOldContainer][3] -= recordOldPenalty; aMatAssignmentSolutionIteration[recordOldContainer][recordCell] = 0; // добавим в текущее решение информацию о назначении новой ячейки в новый контейнер aMatSolutionIteration[recordNewContainer][1] += aCellsData[recordCell][1]; aMatSolutionIteration[recordNewContainer][2] += recordNewCosts; if (aMatSolutionIteration[recordNewContainer][0] == -1) aMatSolutionIteration[recordNewContainer][0] = recordNewContainer; aMatSolutionIteration[recordNewContainer][3] += recordNewPenalty; aMatAssignmentSolutionIteration[recordNewContainer][recordCell] = 1; //checkCorrectnessSolution(aCellsData, aMatDist, aMatAssignmentSolutionIteration, aMatSolutionIteration, cellsNumb); } } while (recordDeltaCosts < 0); }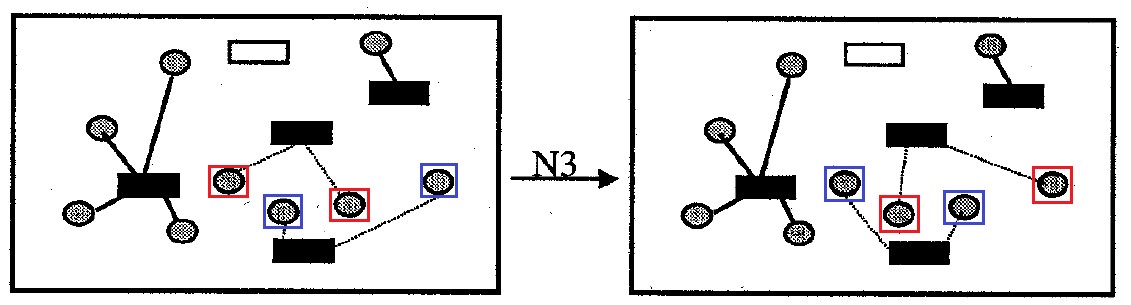
Окрестность : содержит все варианты решения задачи, которые отличаются от исходного взаимной заменой прикрепления всех ячеек для одной пары контейнеров. Размер окрестности не более вариантов.
Второй тип окрестностей рассматривается как механизм «диверсификации» решений, когда уже невозможно получить улучшения поиском по «близким» окрестностям первого типа.
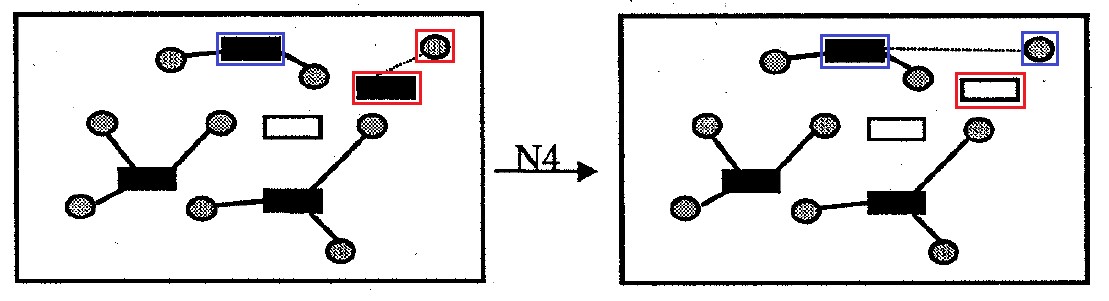
Окрестность : содержит все варианты решения задачи, которые отличаются от исходного удалением одной ячейки-контейнера из решения. Ячейки-доноры, которые были прикреплены к такому контейнеру, который был удален из решения, прикрепляются к другим контейнерам с целью минимизации суммы затрат на перемещения и штрафа за превышение вместимости контейнера. Размер окрестности не более вариантов.

Окрестность : содержит все варианты решения задачи, которые отличаются от исходного откреплением ячеек от одного контейнера и прикреплением таких ячеек к другому пустому контейнеру для произвольной одной пары контейнеров. Размер окрестности не более вариантов.
Авторы статьи говорят, что, исходя из результатов вычислительных экспериментов, наилучшим вариантом является сначала поиск по «ближним» окрестностям первого типа, а потом уже поиск по «дальним» окрестностям.
Отметим, что авторы статьи рекомендуют делать поиск по окрестностям без учета ограничений на вместимость каждого контейнеров. Вместо этого, если вместимость контейнера превышена, тогда добавлять к общим затратам решения некоторую положительную величину «штрафа», которая будет ухудшать привлекательность такого решения по сравнению с другими решениями. Единственное ограничение делается на общий объем контейнеров, то есть общий объем товара, перемещаемого из ячеек-доноров не должен превосходить общей вместимости контейнеров. Это снятие ограничений делается потому, что если ограничения учитывать, то зачастую окрестности не будут содержать в себе ни одного допустимого решения и алгоритм локального поиска будет заканчивать свою работу сразу после своего начала, не делая никаких улучшений. На рисунке 12 показан пример работы локального поиска без учета ограничений на вместимость каждого контейнера.

На данном рисунке полагается, что красные и зеленые остатки из некоторых ячеек-доноров не выгодно перемещать ни в какой другой контейнер, кроме второго. Это значит, что дальнейшее улучшение решения невозможно, так как любое другое новое допустимое решение задачи, где ограничения на вместимость соблюдаются, будет хуже изначального по затратам на перемещение. Как видно, алгоритм за 2 итерации строит допустимое решение гораздо лучше изначального, не смотря на то что первая итерация строит недопустимое решение с превышением вместимости.
Отметим, что такой подход ввода «штрафа» за недопустимость решения является достаточно распространенным в дискретной оптимизации и применяется часто в таких алгоритмах как генетические алгоритмы, табу поиск и др.
После завершения работы алгоритма локального поиска, если найденное решение оказалось все еще недопустимым, то есть ограничения вместимости контейнеров где-то были превышены, мы должны привести найденное решение к допустимому виду, где все ограничения на вместимость контейнеров соблюдаются. Алгоритм устранения недопустимости решения следующий.
- Шаг 1. Осуществить локальный поиск по окрестностям shift и swap. В данном случае переход осуществлять только в те решения, которые уменьшают именно величину «штрафа». Если уменьшение штрафа невозможно, то выбирается решение с меньшими общими затратами. Если же дальнейшее улучшение локальным поиском никак невозможно, перейти на шаг 2, иначе, если полученное решение допустимо, тогда завершить работу алгоритма.
- Шаг 2. Если решение все еще недопустимо, тогда из каждого контейнера, где было превышение вместимости, открепляются ячейки-доноры в порядке возрастания объема товара до тех пор, пока ограничение на вместимость не будет выполняться. Для таких открепленных ячеек все этапы алгоритма начиная с первого повторяются, притом, что множество имеющихся выбранных контейнеров и способ прикрепления к ним остальных ячеек фиксируются и не подлежат изменению. Отметим, что такой шаг 2, как показывает вычислительный эксперимент, требуется выполнять крайне редко.
Вычислительный эксперимент и анализ эффективности алгоритма
Алгоритм GRASP был реализован с нуля на языке С++, так как исходников алгоритма, описанного в статье, мы не нашли. Код программы был скомпилирован с помощью g++ с опцией оптимизации -O2. Код проекта в Visual Studio выложен на GitHub. Единственное, заказчик попросил удалить несколько наиболее сложных процедур локального поиска из соображений интеллектуальной собственности, коммерческой тайны и проч. В статье, где описывается алгоритм GRASP была заявлена его высокая эффективность, где под эффективностью подразумевается то, что он стабильно вычисляет решения очень близкие к оптимальным притом, что работает достаточно быстро. Для того чтобы убедиться в реальной эффективности такого алгоритма GRASP мы провели свой собственный вычислительный эксперимент. Входные данные задачи генерировались нами случайно с равномерным распределением. Вычисленные алгоритмом решения сравнивались с оптимальными решениями, который рассчитывались точным алгоритмом, предложенным в статье. Исходники такого точного алгоритма находятся на GitHub в свободном доступе по ссылке. Размерность задачи, например, 10х100 будет означать, что мы имеем 10 ячеек-доноров и 100 ячеек-контейнеров. Вычисления проводились на персональном компьютере с характеристиками: CPU 2.50 GHz, Intel Core i5-3210M, 8 GB RAM, операционная система Windows 10 (х64).
| Размерность задачи | Количество сгенерированных примеров | Среднее время работы алгоритма GRASP | Среднее время работы точного алгоритма | Средняя ошибка алгоритма GRASP, % |
|---|---|---|---|---|
| 5х50 | 50 | 0,08 | 1,22 | 0,2 |
| 10х50 | 50 | 0,14 | 3,75 | 0,4 |
| 10х100 | 50 | 0,55 | 15,81 | 1,4 |
| 10х200 | 25 | 2,21 | 82,73 | 1,8 |
| 20х100 | 25 | 1,06 | 264,15 | 2,3 |
| 20х200 | 25 | 4,21 | 797,39 | 2,7 |
Как видно из таблицы 3, алгоритм GRASP действительно вычисляет решения близкие к оптимальным, причем с ростом размерности задачи качество решений алгоритма ухудшается незначительно. Также из результатов эксперимента видно, что алгоритм GRASP достаточно быстрый, например, задачу размерности 10х100 он решает в среднем за 0,5 секунды. Стоит напоследок отметить, что результаты нашего вычислительного эксперимента согласуются с результатами в статье.
Запуск алгоритма в продакшн
После того, как алгоритм был разработан, отлажен и протестирован в вычислительном эксперименте, наступил момент запуска его в эксплуатацию. Алгоритм был реализован на языке С++ и был помещен в DLL, которая подключалась к приложению 1С как внешняя компонента типа Native. О том, что такое внешние компоненты 1С и как их правильно разрабатывать и подключать к приложению 1С читайте здесь. В программе «1С: Управление складом 3» была разработана форма обработки, в которой пользователь может запускать процедуру сжатия остатков с требуемыми ему параметрами. Скриншот формы приведен ниже.

Пользователь может в форме выбирать параметры сжатия остатков:
- Режим сжатия: с кластеризацией партий (смотри первую статью) и без нее.
- Склад, в ячейках которого необходимо провести сжатие. В одном помещении может быть несколько складов для разных организаций. Как раз такая ситуация была у нашего клиента.
- Также пользователь может интерактивно корректировать количество товара, перемещаемого из ячейки-донора в контейнер и удалять номенклатуру из списка на сжатие, если по каким-либо причинам он хочет, чтобы она в процедуре сжатия не участвовала.
Заключение
В конце статьи хочется резюмировать опыт, полученный в результате внедрения такого алгоритма оптимизации.
- В решении задач оптимизации процессов есть реальная потребность в независимости от отрасли предприятия. Причем решение таких задач может принести существенный эффект: сократить издержки, экономить время, устранить узкие места в процессах. Эта потребность остается у клиента лишь проблемой и не формулируется в четкую задачу зачастую из-за отсутствия:
- кадров, которые могли бы сформулировать такую задачу перед программистом;
- знаний и навыков у программистов разрабатывать эффективные алгоритмы оптимизации.
- Без знаний базовой теории методов оптимизации и дискретной математики (про основы теории алгоритмов и структур данных я вообще не говорю), думаю, невозможно разрабатывать эффективные алгоритмы оптимизации. Здесь ключевое слово «эффективные», так как простенький алгоритм с более-менее рациональной умозрительной логикой могут написать многие программисты. Но здесь не факт, что он будет вычислять хорошие решения, близкие к оптимальным и будет работать быстро. Хотя, возможно, на первое время это закроет потребность, так как что-то лучше, чем ничего.
- Перед тем как сразу садиться кодить алгоритм оптимизации, необходимо его не просто заранее спроектировать (что само собой разумеется), необходимо провести анализ уже существующих разработок по этой теме. С большой вероятностью, что над такой задачей уже задумывались, потратили время на ее изучение и уже разработали и протестировали алгоритмы решения. Целесообразней воспользоваться имеющимся опытом, чем изобретать свой велосипед с квадратными колесами. Здесь разработчик должен уметь читать математические статьи и ориентироваться в математической терминологии. Причем нужно уметь свободно читать технические тексты на английском языке, поскольку большинство статей на английском.
- Лучшая последовательность разработки алгоритмов оптимизации на наш взгляд следующая:
- Строгая математическая формулировка изначальной практической задачи.
- Поиск известной математической модели задачи с похожей формулировкой.
- Анализ уже существующих алгоритмов для решения подобных задач. Выбор алгоритма решения и его модификация, если требуется.
- Подготовка и преобразование входных данных для алгоритма. Как показывает практика, трудоемкость такого этапа часто недооценена. В этой статье мы специально уделили много внимания такому этапу, чтобы показать, что только качественно и с умом подготовленные входные данные могут сделать решения, вычисляемые алгоритмом, действительно ценными для клиента.
- Разработка, отладка и внутреннее тестирование алгоритма. Проведение вычислительного эксперимента по сравнению такого алгоритма с точным алгоритмом (если его исходники удалось найти) или модификаций алгоритма между собой и с другими известными алгоритмами. В любом случае необходимо разрабатывать несколько модификаций алгоритма и проверять их эффективность в вычислительном эксперименте, а не полагаться на свою интуицию.
- Тестирование алгоритма заказчиком и деплой на продакшн.
И, думаю, самое главное. Процесс оптимизации на предприятии зачастую должен следовать после завершения процесса информатизации. Оптимизация без предварительной информатизации малополезна, так как не откуда брать данные и некуда данные решения алгоритма записывать. Думаю, что большинство средних и крупных отечественных предприятий закрыли базовые потребности в автоматизации и информатизации и готовы к более «тонким настройкам» оптимизации процессов.
Поэтому мы практикуем после внедрения информационной системы, будь то ERP, WMS, TMS и т.д. делать небольшие доп. проекты по оптимизации тех процессов, которые выявились в ходе внедрения информационной системы как проблемные и важные для клиента. Думаю, это перспективная практика, которая в последующие годы будет набирать обороты.
Статью подготовил
Роман Шангин, программист департамента проектов,
компания Первый Бит, г. Челябинск
Телеграм: t.me/ainewsline
Источник: habr.com