Распознавание эмоций с помощью сверточной нейронной сети
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2019-07-26 22:29
реализация нейронной сети, распознавание образов, искусственный интеллект

Распознавание эмоций всегда было захватывающей задачей для ученых. В последнее время я работаю над экспериментальным SER-проектом (Speech Emotion Recognition), чтобы понять потенциал этой технологии – для этого я отобрал наиболее популярные репозитории на Github и сделал их основой моего проекта. Прежде чем мы начнем разбираться в проекте, неплохо будет вспомнить, какие узкие места есть у SER.
Главные препятствия
- эмоции субъективны, даже люди интерпретируют их по-разному. Трудно определить само понятие «эмоции»;
- комментировать аудио – трудно. Должны ли мы как-то помечать каждое отдельное слово, предложение или все общение целиком? Набор каких именно эмоций использовать при распознавании?
- собирать данные тоже непросто. Много аудиоданных может быть собрано из фильмов и новостей. Однако оба источника «необъективны», потому что новостей обязаны быть нейтральными, а эмоции актеров – сыгранные. Трудно найти «объективный» источник аудиоданных.
- разметка данных требует больших человеческих и временных ресурсов. В отличие от рисования рамок на изображениях, здесь требуется специально обученный персонал, чтобы прослушивать целые аудиозаписи, анализировать их и снабжать комментариями. А затем эти комментарии должны быть оценены множеством других людей, потому что оценки субъективны.

Описание проекта
Использование сверточной нейронной сети для распознавания эмоций в аудиозаписях. И да, владелец репозитория не ссылался ни на какие источники.
Описание данных
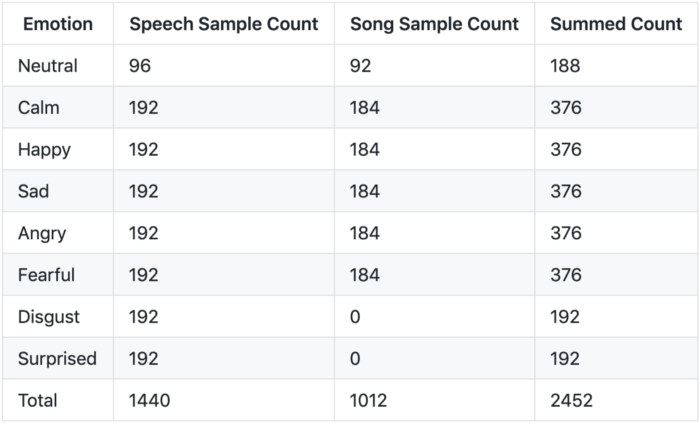
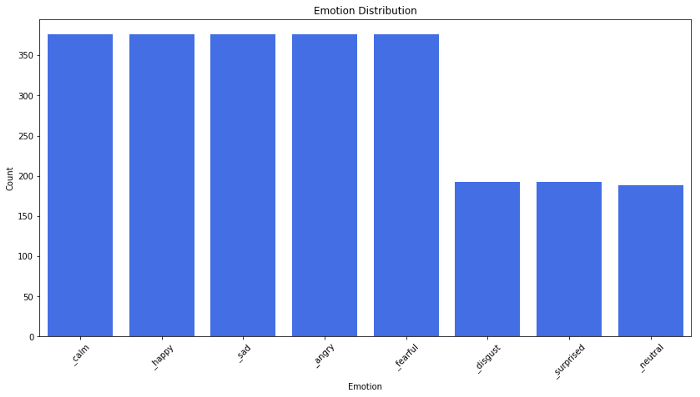
Есть два датасета, которые использовались в репозиториях RAVDESS и SAVEE, я только лишь адаптировал RAVDESS в своей модели. В контекста RAVDESS есть два типа данных: речь (speech) и песня (song).
Датасет RAVDESS (The Ryerson Audio-Visual Database of Emotional Speech and Song):
- 12 актеров и 12 актрис записали свою речь и песни в своем исполнении;
- у актера #18 нет записанных песен;
- эмоции Disgust (отвращение), Neutral (нейтральная) и Surprises (удивленние) отсутствуют в «песенных» данных.
Разбивка по эмоциям:
Извлечение признаков
Когда мы работаем с задачами распознавания речи, мел-кепстральные коэффициенты (MFCCs) – это передовая технология, несмотря на то, что она появилась в 80-х. Цитата из туториала по MFCC:
Эта форма определяет, каков звук на выходе. Если мы можем точно обозначить форму, она даст нам точное представление прозвучавшей фонемы. Форма речевого тракта проявляет себя в огибающей короткого спектра, и работы MFCC – точно отобразить эту огибающую.
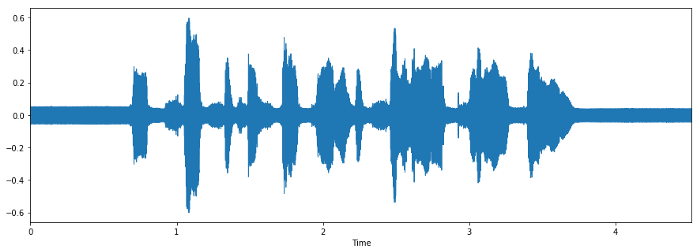
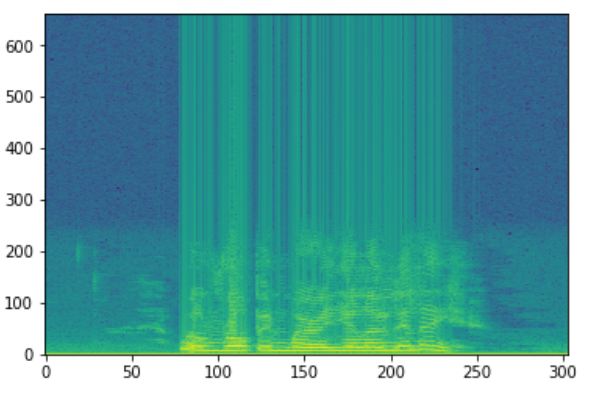
Мы используем MFCC как входной признак. Если вам интересно разобраться подробнее, что такое MFCC, то этот туториал – для вас. Загрузку данных и их конвертацию в формат MFCC можно легко сделать с помощью Python-пакета librosa.
Архитектура модели по умолчанию
Автор разработал CNN-модель с помощь пакет Keras, создав 7 слоев – шесть Con1D слоев и один слой плотности (Dense).
model = Sequential() model.add(Conv1D(256, 5,padding='same', input_shape=(216,1))) #1 model.add(Activation('relu')) model.add(Conv1D(128, 5,padding='same')) #2 model.add(Activation('relu')) model.add(Dropout(0.1)) model.add(MaxPooling1D(pool_size=(8))) model.add(Conv1D(128, 5,padding='same')) #3 model.add(Activation('relu')) #model.add(Conv1D(128, 5,padding='same')) #4 #model.add(Activation('relu')) #model.add(Conv1D(128, 5,padding='same')) #5 #model.add(Activation('relu')) #model.add(Dropout(0.2)) model.add(Conv1D(128, 5,padding='same')) #6 model.add(Activation('relu')) model.add(Flatten()) model.add(Dense(10)) #7 model.add(Activation('softmax')) opt = keras.optimizers.rmsprop(lr=0.00001, decay=1e-6)Автор закомментировал слои 4 и 5 в последнем релизе (18 сентября 2018 года) и итоговый размер файла этой модели не подходит под предоставленную сеть, поэтому я не смогу добиться такого же результат по точности – 72%.
Модель просто натренирована с параметрами
batch_size=16 и epochs=700, без какого-либо графика обучения и пр.# Compile Model model.compile(loss='categorical_crossentropy', optimizer=opt,metrics=['accuracy']) # Fit Model cnnhistory=model.fit(x_traincnn, y_train, batch_size=16, epochs=700, validation_data=(x_testcnn, y_test))Здесь
categorical_crossentropy это функция потерь, а мера оценки – точность.Мой эксперимент
Разведочный анализ данных
В датасете RAVDESS каждый актер проявляет 8 эмоций, проговаривая и пропевая 2 предложения по 2 раза каждое. В итоге с каждого актера получается 4 примера каждой эмоции за исключением вышеупомянутых нейтральной эмоции, отвращения и удивления. Каждое аудио длится примерно 4 секунды, в первой и последней секундах чаще всего тишина.
Типичные предложения:

Наблюдение
После того как я выбрал датасет из 1 актера и 1 актрисы, а затем прослушал все их записи, я понял, что мужчины и женщины выражают свои эмоции по-разному. Например:
- мужская злость (Angry) просто громче;
- мужские радость (Happy) и расстройство (Sad) – особенность в смеющемся и плачущем тонах во время «тишины»;
- женские радость (Happy), злость (Angry) и расстройство (Sad) громче;
- женское отвращение (Disgust) содержит в себе звук рвоты.
Повторение эксперимента
Автор убрал классы neutral, disgust и surprised, чтобы сделать 10-классовое распознавание датасета RAVDESS. Пытаясь повторить опыт автора, я получил такой результат:
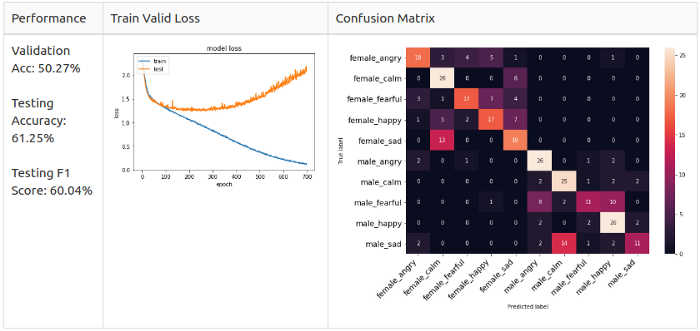
- актеры с 1 по 20 используются для сетов Train / Valid в соотношении 8:2;
- актеры с 21 по 24 изолированы от тестов;
- параметры Train Set: (1248, 216, 1);
- параметры Valid Set: (312, 216, 1);
- параметры Test Set: (320, 216, 1) — (изолировано).
Я заново обучил модель и вот результат:

Тест производительности
Из графика Train Valid Gross видно, что не происходит схождение для выбранных 10 классов. Поэтому я решил понизить сложность модели и оставить только мужские эмоции. Я изолировал двух актеров в рамках test set, а остальных поместил в train/valid set, соотношение 8:2. Это гарантирует, что в датасете не будет дисбаланса. Затем я тренировал мужские и женские данные отдельно, чтобы провести тест.
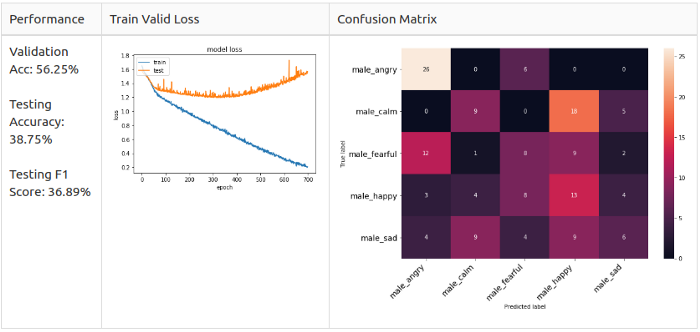
Мужской датасет
- Train Set – 640 семплов от актеров 1-10;
- Valid Set – 160 семплов от актеров 1-10;
- Test Set – 160 семплов от актеров 11-12.
Опорная линия: мужчины
- Train Set – 608 семплов от актрис 1-10;
- Valid Set – 152 семпла от актрис 1-10;
- Test Set – 160 семплов от актрис 11-12.
Опорная линия: женщины
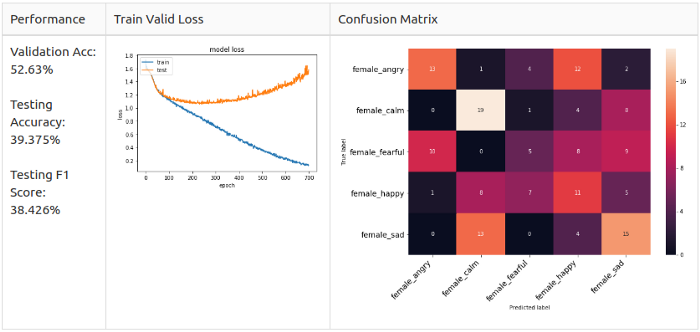
Женщины: расстройство (Sad) и радость (Happy) – основыне предугаданные классы в модели; злость (Angry) и радость (Happy) легко спутать.
Вспоминая наблюдения из Разведочного анализа данных, я подозреваю, что женские злость (Angry) и радость (Happy) похожи до степени смешения, потому что их способ выражения заключается просто в повышении голоса.
Вдобавок ко всему, мне интересно, что если я еще больше упрощу модель, остави только классы Positive, Neutral и Negative. Или только Positive и Negative. Короче, я сгруппировал эмоции в 2 и 3 класса соответственно.
2 класса:
- Позитивные: радость (Happy), спокойствие (Calm);
- Негативные: злость (Angry), страх (fearful), расстройство (sad).
3 класса:
- Позитивные: радость (Happy);
- Нейтральные: спокойствие (Calm), нейтральная (Neutral);
- Негативные: злость (Angry), страх (fearful), расстройство (sad).
До начала эксперимента я настроил архитектуру модели с помощью мужских данных, сделав 5-классовое распознавание.
# Указываем нужное кол-во классов target_class = 5 # Модель model = Sequential() model.add(Conv1D(256, 8, padding='same',input_shape=(X_train.shape[1],1))) #1 model.add(Activation('relu')) model.add(Conv1D(256, 8, padding='same')) #2 model.add(BatchNormalization()) model.add(Activation('relu')) model.add(Dropout(0.25)) model.add(MaxPooling1D(pool_size=(8))) model.add(Conv1D(128, 8, padding='same')) #3 model.add(Activation('relu')) model.add(Conv1D(128, 8, padding='same')) #4 model.add(Activation('relu')) model.add(Conv1D(128, 8, padding='same')) #5 model.add(Activation('relu')) model.add(Conv1D(128, 8, padding='same')) #6 model.add(BatchNormalization()) model.add(Activation('relu')) model.add(Dropout(0.25)) model.add(MaxPooling1D(pool_size=(8))) model.add(Conv1D(64, 8, padding='same')) #7 model.add(Activation('relu')) model.add(Conv1D(64, 8, padding='same')) #8 model.add(Activation('relu')) model.add(Flatten()) model.add(Dense(target_class)) #9 model.add(Activation('softmax')) opt = keras.optimizers.SGD(lr=0.0001, momentum=0.0, decay=0.0, nesterov=False)Я добавил 2 слоя Conv1D, один слой MaxPooling1D и 2 слоя BarchNormalization; также я изменил значение отсева на 0.25. Наконец, я изменил оптимизатор на SGD со скоростью обучения 0.0001.
lr_reduce = ReduceLROnPlateau(monitor=’val_loss’, factor=0.9, patience=20, min_lr=0.000001) mcp_save = ModelCheckpoint(‘model/baseline_2class_np.h5’, save_best_only=True, monitor=’val_loss’, mode=’min’) cnnhistory=model.fit(x_traincnn, y_train, batch_size=16, epochs=700, validation_data=(x_testcnn, y_test), callbacks=[mcp_save, lr_reduce])Для тренировки модели я применил уменьшение «плато обучения» и сохранил только лучшую модель с минимальным значением
val_loss. И вот каковы результаты для разных целевых классов.Производительность новой модели
Мужчины, 5 классов
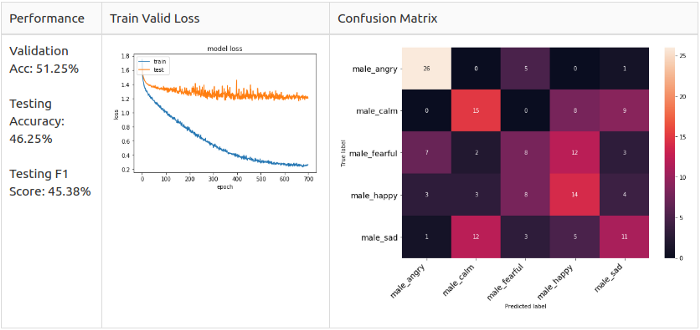

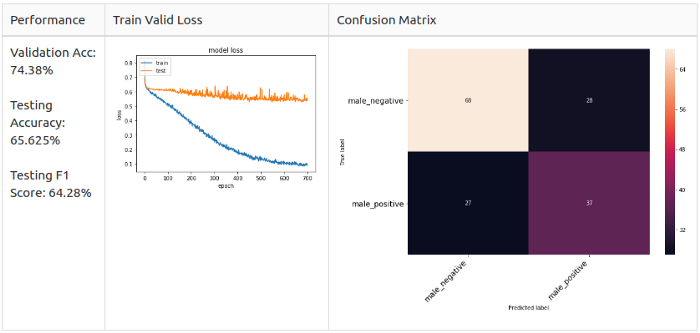
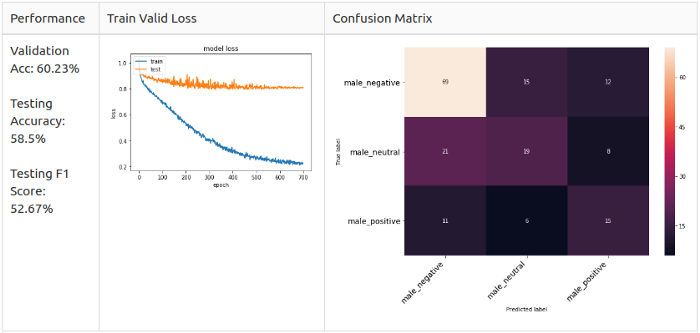
Увеличение (аугментация)
Когда я усилил архитектуру модели, оптимизатор и скорость обучения, выяснилось, что модель по-прежнему не сходится в режиме тренировки. Я предположил, что это проблема количества данных, так как у нас имеется только 800 семплов. Это привело меня к методам увеличения аудио, в итоге я увеличил датасеты ровно вдвое. Давайт взглянем на эти методы.
Мужчины, 5 классов
Динамическое увеличение значений
def dyn_change(data): """ Случайное изменение значений """ dyn_change = np.random.uniform(low=1.5,high=3) return (data * dyn_change)
def pitch(data, sample_rate): """ Настройка высоты звука """ bins_per_octave = 12 pitch_pm = 2 pitch_change = pitch_pm * 2*(np.random.uniform()) data = librosa.effects.pitch_shift(data.astype('float64'), sample_rate, n_steps=pitch_change, bins_per_octave=bins_per_octave)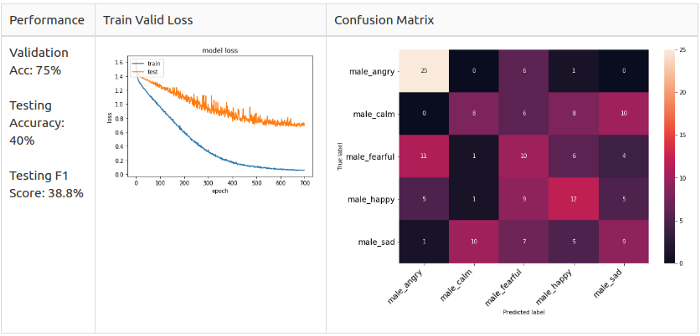
def shift(data): """ Случайное смещение """ s_range = int(np.random.uniform(low=-5, high = 5)*500) return np.roll(data, s_range)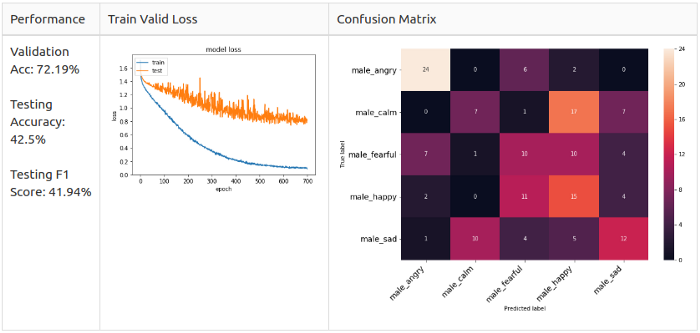
def noise(data): """ Добавление белого шума """ # можете взять любой дистрибутив отсюда: https://docs.scipy.org/doc/numpy-1.13.0/reference/routines.random.html noise_amp = 0.005*np.random.uniform()*np.amax(data) data = data.astype('float64') + noise_amp * np.random.normal(size=data.shape[0]) return data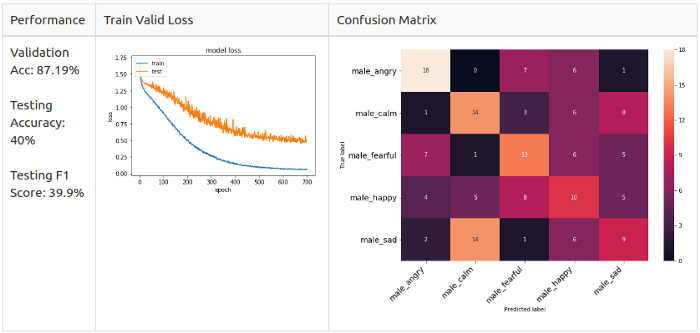
Объединяем несколько методов
Белый шум + смещение
Тестируем аугментацию на мужчинах
Мужчины, 2 класса
Белый шум + смещение
Для всех семплов
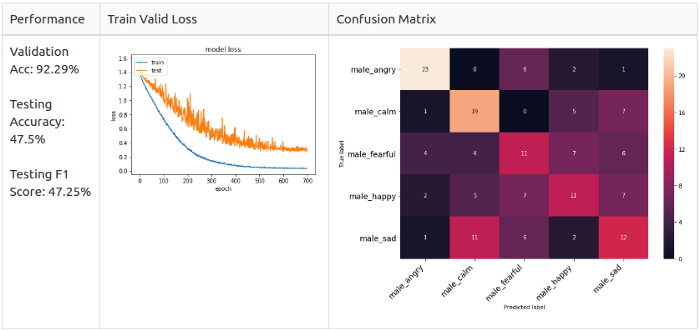
Только для позитивных семплов, так как 2-классовый сет дисбалансированный (в сторону негативных семплов).
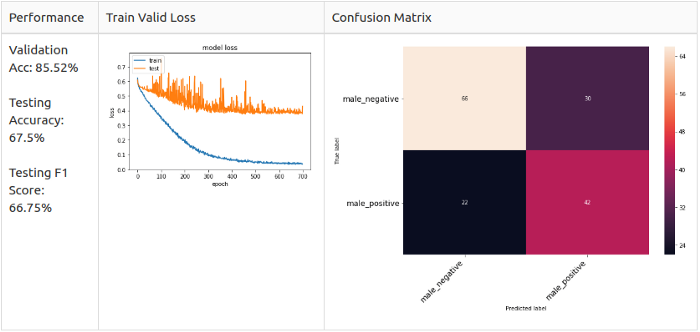
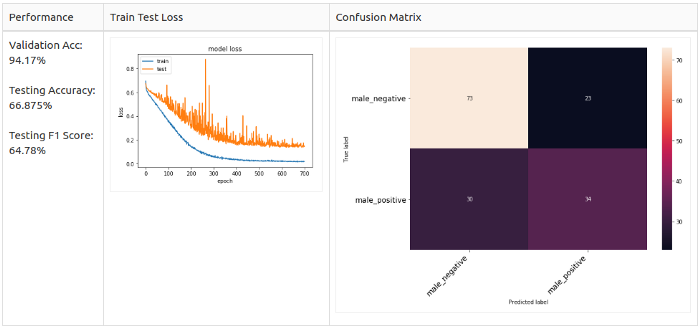
Для всех семплов
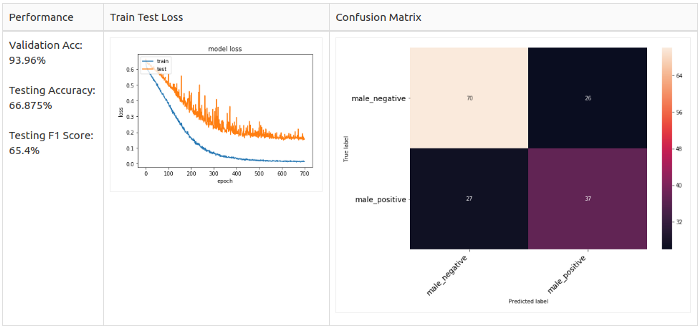
Только для позитивных семплов
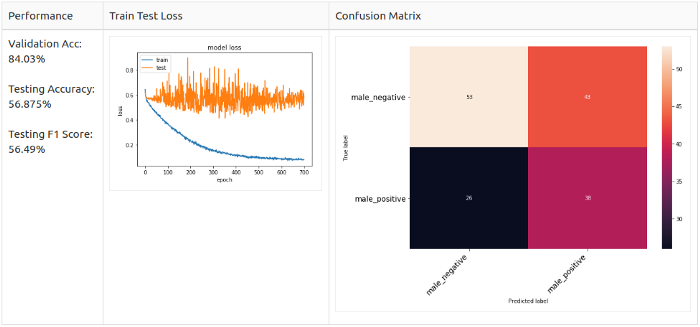
Заключение
В конце концов, я смог поэкспериментировать только с мужским датасетом. Я заново разделил данные так, чтобы избежать дисбаланса и, как следствие, утечки данных. Я настроил модель на эксперименты с мужскими голосами, так как я хотел максимально упростить модель для начала. Также я провел тесты, используя разные методы аугментации; добавление белого шума и смещение хорошо зарекомендовали себя на дисбалансированных данных.
Выводы
- эмоции субъективны и их сложно фиксировать;
- необходимо заранее определять, какие эмоции подходят для целей проекта;
- не стоит всегда доверять контенту с Github, даже если он имеет много звезд;
- разделение данных – имейте его в виду;
- разведочный анализ данных всегда дает хорошее представление, однако надо быть терпеливым, когда речь о работе с аудиоданными;
- определяйте, что будете давать на вход вашей модели: предложение, всю запись или восклицание?
- нехватка данных – это важный фактор успеха в SER, однако создать хороший датасет с эмоциями – это комплексная и дорогостоящая задача;
- упрощайте свою модель в случае нехватки данных.
Дальнейшее улучшение
- я использовал только первые 3 секунды в качестве входных данных, чтобы снизить общий размер данных – оригинальный проект использовал 2.5 секунды. Я бы хотел поэкспериментировать с полноразмерными записями;
- можно предварительно обработать данные: обрезать тишину, нормализовать длину с помощью дополнения нулями и т.д.;
- попробовать рекуррентные нейронные сети для этой задачи.
Телеграм: t.me/ainewsline
Источник: habr.com