Погружение в свёрточные нейронные сети. Часть 5 / 10 — 18
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2019-07-08 22:49

Полный курс на русском языке можно найти по этой ссылке. Оригинальный курс на английском доступен по этой ссылке.

Содержание
- Интервью с Себастьяном Труном
- Введение
- Набор данных собак и кошек
- Изображения различного размера
- Цветные изображения. Часть 1
- Цветные изображения. Часть 2
- Операция свёртки на цветных изображениях
- Операция подвыборки по максимальному значению на цветных изображениях
- CoLab: кошки и собаки
- Softmax и sigmoid
- Проверка
- Расширение изображений
- Исключение
- CoLab: собаки и кошки. Повторение
- Другие техники для предотвращения переобучения
- Упражнение: классификация изображений цветов
- Итоги
Softmax и Sigmoid
В прошлом практическом CoLab мы использовали следующую архитектуру свёрточной нейронной сети:
model = tf.keras.models.Sequential([ tf.keras.layers.Conv2D(32, (3,3), activation='relu', input_shape=(150, 150, 3)), tf.keras.layers.MaxPooling2D(2, 2), tf.keras.layers.Conv2D(64, (3,3), activation='relu'), tf.keras.layers.MaxPooling2D(2,2), tf.keras.layers.Conv2D(128, (3,3), activation='relu'), tf.keras.layers.MaxPooling2D(2,2), tf.keras.layers.Conv2D(128, (3,3), activation='relu'), tf.keras.layers.MaxPooling2D(2,2), tf.keras.layers.Flatten(), tf.keras.layers.Dense(512, activation='relu'), tf.keras.layers.Dense(2, activation='softmax') ]) Обратите внимание, что наш последний слой (наш классификатор) состоит из полносвязного слоя с двумя выходными нейронами и функцией активации softmax:
tf.keras.layers.Dense(2, activation='softmax') Другой популярный подход к решению задач бинарной классификации — использование классификатора, который состоит из полносвязного слоя с 1 выходным нейроном и функцией активации sigmoid:
tf.keras.layers.Dense(1, activation='sigmoid') Оба эти варианта будут хорошо работать в задаче бинарной классификации. Однако, что стоит иметь ввиду, если вы решите воспользоваться функцией активации sigmoid в своём классификаторе, то понадобится так же изменить и функцию потерь в методе model.compile() со sparse_categorical_crossentropy на binary_crossentropy как в примере ниже:
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])Валидация
На прошлых занятиях мы изучали точность работы наших свёрточных нейронных сетей используя метрику accuracy на тестовом наборе данных. Когда мы разрабатывали свёрточную нейронную сеть для классификации изображений из набора данных FASHION MNIST, то получили 97% точность на тренировочном наборе данных и всего лишь 92% точность на тестовом наборе данных. Всё это происходило потому, что наша модель переобучалась. Другими словами, наша свёрточная нейронная сеть начинала запоминать тренировочный набор данных. Однако о переобучении мы смогли узнать только после того, как провели обучение и тестирование модели на имеющихся данных сравнив точности работы на обучающем наборе данных и тестовом наборе данных.
Для избежания подобной проблемы мы, достаточно часто, используем набор данных для валидации:
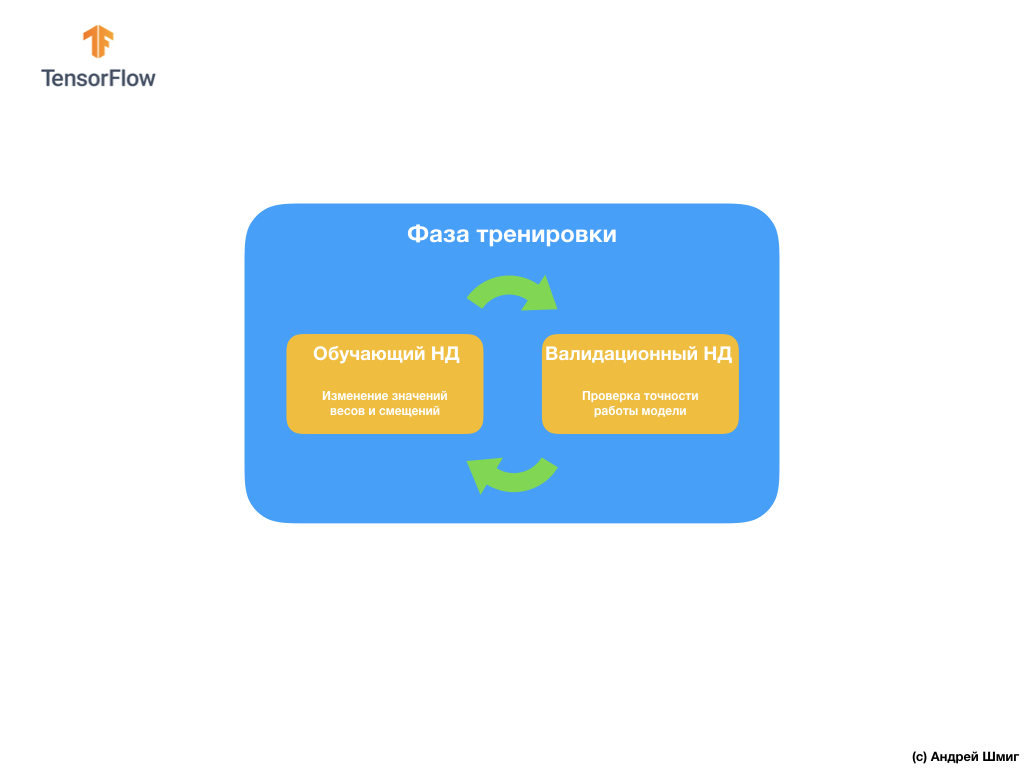
Во время тренировки наша свёрточная нейронная сеть "видит" только тренировочный набор данных и принимает решения, каким образом изменить значения внутренних параметров — весов и смещений. После каждой обучающей итерации мы проверяем состояние модели, вычисляя значение функции потерь на обучающем наборе данных и на валидационном наборе данных. Стоит отметить и обратить особое внимание на то, что данные из валидационного набора нигде не используются моделью для корректировки значений внутренних параметров. Проверка точности работы модели над валидационным набором данных всего лишь сообщает нам насколько хорошо наша модель работает над этим самым набором данных. Таким образом результаты работы модели на валидационном наборе данных сообщают нам насколько хорошо наша модель научилась обобщать полученные данные и применять это обобщение на новом наборе данных.
Идея заключается в том, что раз мы не используем валидационный набор данных при обучении модели, то тестирование работы модели на валидационном наборе позволит нам понять переобучилась ли модель или нет.
Давайте рассмотрим пример.
В CoLab, который мы выполнили несколькими пунктами выше, мы тренировали нашу нейронную сеть в течение 15 итераций.
Epoch 15/15 10/10 [===] - loss: 1.0124 - acc: 0.7170 20/20 [===] - loss: 0.0528 - acc: 0.9900 - val_loss: 1.0124 - val_acc: 0.7070 Если мы посмотрим на точность предсказаний на тренировочном и валидационном наборах данных на пятнадцатой обучающей итерации, то можно заметить, что мы добились высокой точности на тренировочном наборе данных и значительно низкого показателя на валидационном наборе данных — 0.9900 против 0.7070.
Это очевидный признак переобучения. Нейронная сеть запомнила тренировочный набор данных, поэтому с невероятной точностью работает по входным данным из него. Однако, как только дело переходит к проверке точности на валидационном наборе данных, которого модель не "видела", то результаты значительно снижаются.
Один из способов избежать переобучения является пристальное изучение графика значений функции потерь на тренировочном и валидационном наборах данных на протяжении всех обучающих итераций:
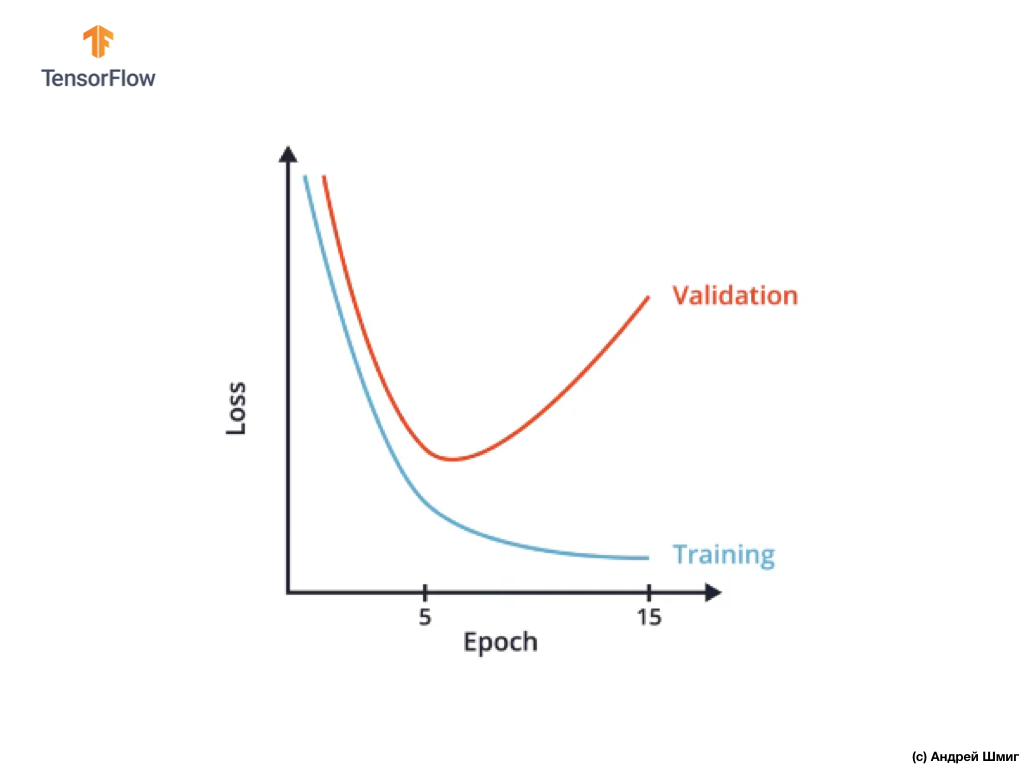
В CoLab мы строили подобный график и получили нечто похожее на приведённый выше график зависимости функции потерь от обучающей итерации.
Можно заметить, что после определённой обучающей итерации значение функции потерь на валидационном наборе данных начинает возрастать, в то время как значение функции потерь на тренировочном наборе данных продолжает снижаться.
В конце 15 обучающей итерации мы замечаем, что значение функции потерь на валидационном наборе данных крайне высоко, а значение функции потерь на обучающем наборе данных крайне мало. Собственно, это и есть тот самый индикатор переобученности нейронной сети.
Внимательно глядя на график можно понять, что буквально через несколько обучающих итераций наша нейронная сеть начинает просто-напросто запоминать тренировочные данные, а значит способность модели обобщать снижается, что ведёт к ухудшению точности на валидационном наборе данных.
Как вы уже наверняка поняли, валидационный набор данных позволяет нам определить количество обучающих итераций, которые необходимо провести, чтобы наша свёрточная нейронная сеть была точной и, в то же время, не переобучилась.
Подобный подход может быть крайне полезен в том случае, если у нас есть выбор из нескольких архитектур свёрточных нейронных сетей:

Например, если вы принимаете решение о количестве слоёв в свёрточной нейронной сети, вы можете создать несколько архитектур нейронных сетей, а затем сравнить их точность используя набор данных для валидации.
Архитектура нейронной сети, которая позволяет добиться минимального значения функции потерь и будет лучшей для решения поставленной вами задачи.
Следующий вопрос, который может у вас возникнуть — зачем создавать валидационный набор данных, если у нас уже есть тестовый набор данных? Можем ли мы использовать тестовый набор данных и для валидации?
Проблема заключается в том, что несмотря на то, что мы не используем валидационный набор данных в процессе обучения модели, мы используем результаты работы над тестовым набором данных для повышения точности работы модели, а это значит что тестовый набор данных влияет на веса и смещения в нейронной сети.
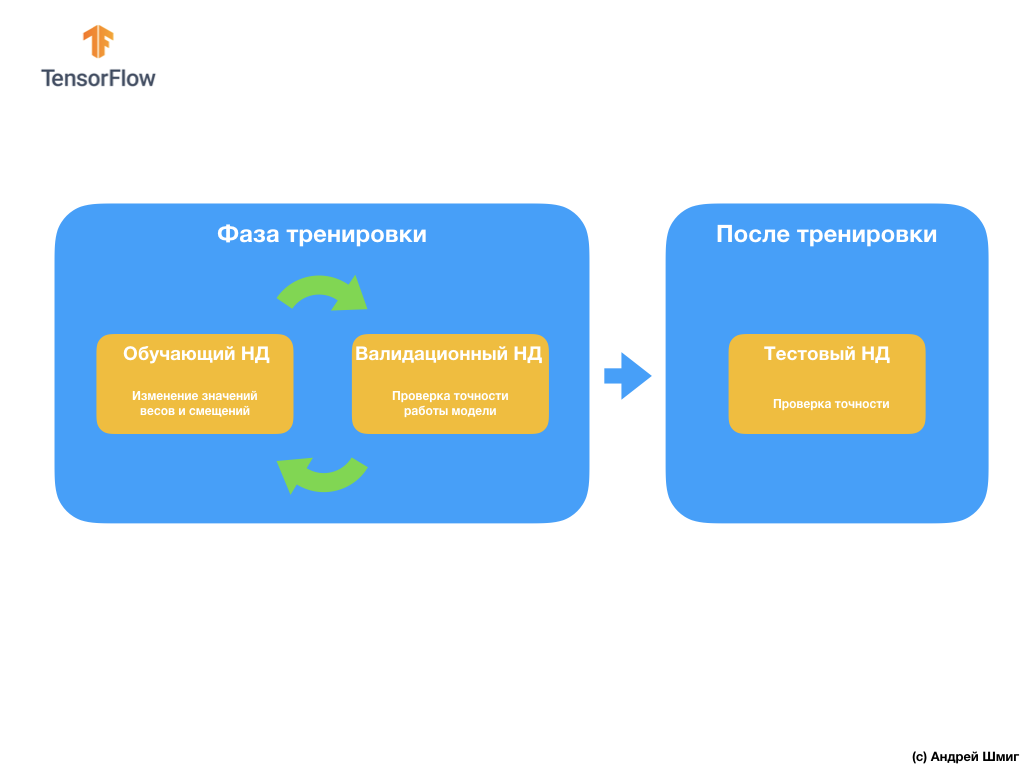
Именно по этой причина нам нужен валидационный набор данных, который наша модель ещё никогда не видела для точной проверки эффективности её работы.
Только что мы разобрались с тем, каким образом валидационный набор данных может помочь нам избежать переобучения. В следующих частях мы поговорим о расширении данных (т.н. augmentation) и об отключениях (т.н. dropout) нейронов — двух популярных техниках, который так же могут нам помочь избежать переобучения.
Расширение изображений (т.н. augmentation)
Тренируя нейронные сети определять объекты определенного класса мы хотим, чтобы наша нейронная сеть находила эти объекты вне зависимости от их местоположения и размера на изображении.
Например, представим, что мы хотим обучить нашу нейронную сеть распознавать собак на изображениях:

Таким образом мы хотим, чтобы наша нейронная сеть определяла наличие собаки на изображении вне зависимости от того, какого размера собака и в какой части изображения она находится, часть ли собаки видна или вся собака. Мы хотим сделать так, чтобы наша нейронная сеть могла обработать все эти варианты во время тренировки.
Если вам достаточно сильно повезло и у вас имеется большой набор обучающих данных, то можно с уверенностью сказать, что вам повезло и ваша нейронная сеть с малой вероятностью переобучится. Однако, что достаточно часто бывает, нам предстоит работать с ограниченным набором изображений (тренировочных данных), что, в свою очередь, приведёт нашу свёрточную нейронную сеть с большой вероятностью к переобучению и снизит её способность обобщать и выдавать нужный результат на данных, которая она не "видела" ранее.
Эту проблему можно решить воспользовавшись техникой называемой "расширением" (image augmentation). Расширение изображений (данных) работает путём создания (генерации) новых изображений для обучения посредством применения произвольных преобразований исходного набора изображений из обучающей выборки.
Например, мы можем взять одно из исходных изображений из нашего обучающего набора данных и применить к нему несколько произвольных преобразований — перевернуть на Х градусов, отзеркалить по горизонтали и произвести произвольное увеличение.

Добавляя сгенерированные изображения в наш обучающий набор данных мы, тем самым, убеждаемся в том, что наша нейронная сеть "увидит" достаточное количество различных примеров для обучения. В результате подобных действий наша свёрточная нейронная сеть будет лучше обобщать и работать на тех данных, которых она ещё не видела и нам удастся избежать переобучения.
В следующей части мы узнаем, что такое dropout (отключение) — другая техника для предотвращения переобучения модели.
Исключение (dropout)
В этой части мы изучим новую технику — отключение (dropout), которая так же поможет нам избежать переобучения модели. Как мы уже знаем из ранних частей нейронная сеть оптимизирует внутренние параметры (веса и смещения) для минимизации функции потерь.
Одна из проблем с которой можно столкнуться во время обучения нейронной сети — огромные значения в одной части нейронной сети и маленькие значение в другой части нейронной сети.

В результате получается, что нейроны с большими весами играют большую роль в процессе обучения, а нейроны с меньшими весами перестают быть значимыми и всё меньше подвергаются изменениям. Один из способов избежать подобного — использовать произвольное отключение нейронов (dropout).
Отключение (dropout) — процесс выборочного отключения нейронов в процессе обучения.
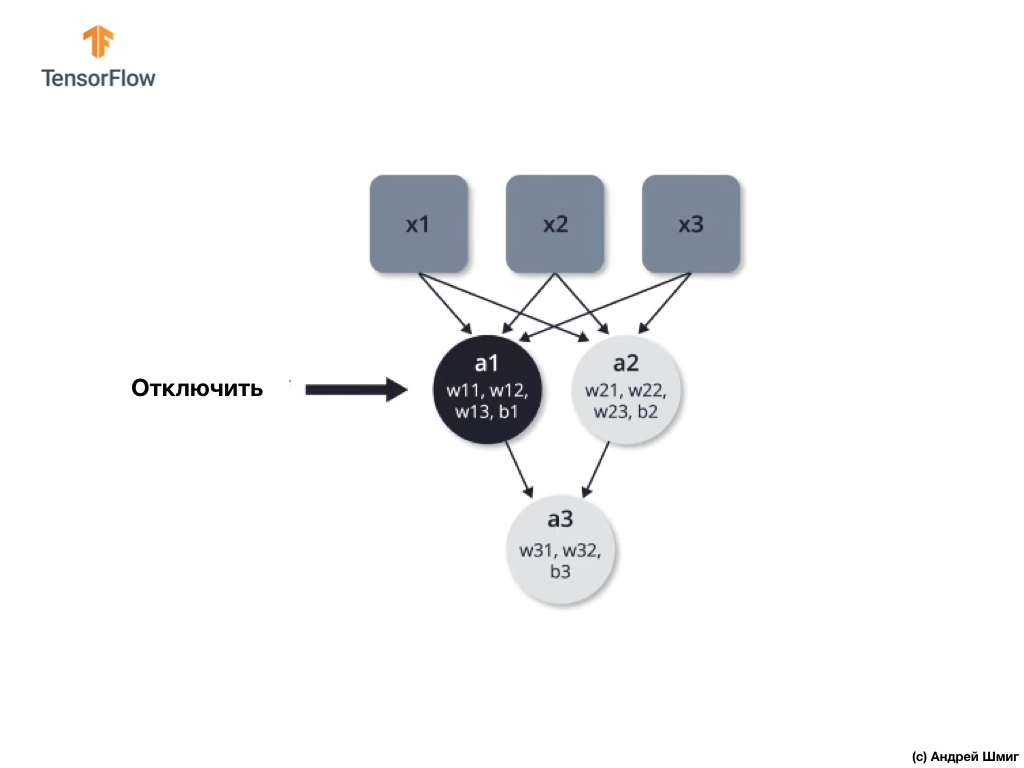
Выборочное отключение одних нейронов в процессе обучения позволяет активно задействовать другие нейроны в обучении. В процессе обучающих итераций мы произвольным образом отключаем некоторые нейроны.
Давайте рассмотрим на примере. Представим себе, что на первой обучающей итерации мы отключаем выделенные черным два нейрона:
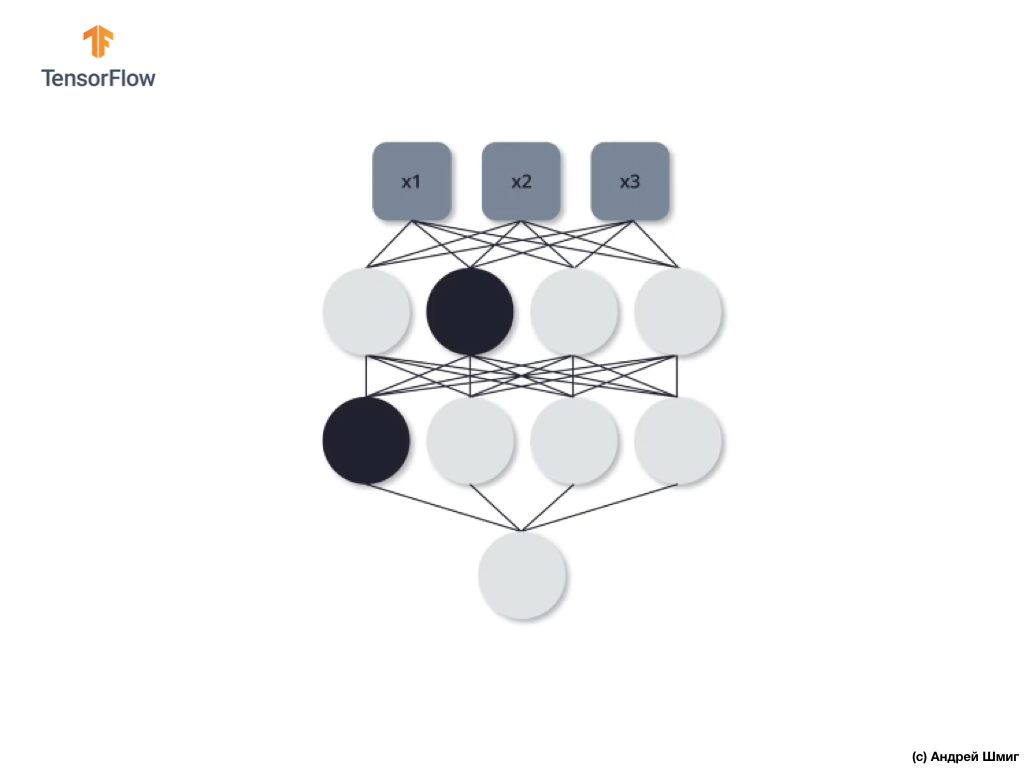
Процессы прямого распространения и обратного распространения происходят без использования выделенных двух нейронов.
На второй обучающей итерации мы решаем не задействовать следующие три нейрона — отключаем их:

Как и в предыдущем случае, в процессах прямого и обратного распространения мы не задействуем эти три нейрона. На последней, третьей обучающей итерации, мы решаем не задействовать эти два нейрона:
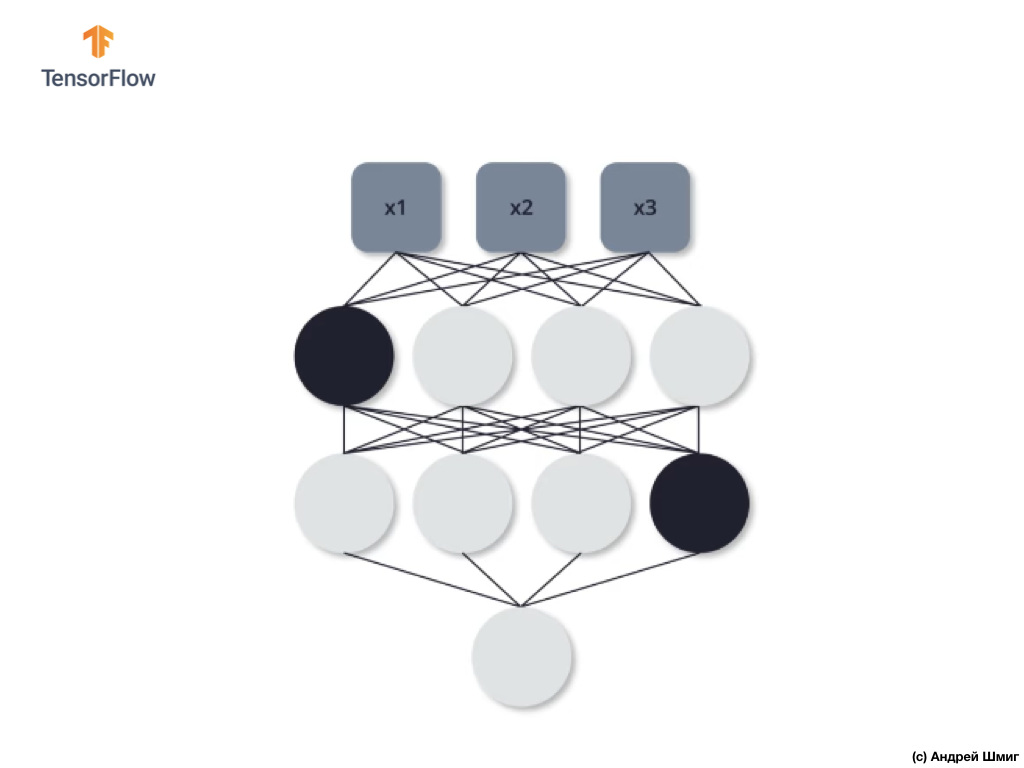
И в этом случае в процессах прямого и обратного распространения мы не используем отключенные нейроны. И так далее.
Тренируя нашу нейронную сеть таким образом мы можем избежать переобучения. Можно сказать, что наша нейронная сеть становится более устойчивой, потому что при таком подходе она не может полагаться абсолютно на все нейроны для решения поставленной задачи. Таким образом другие нейроны начинают принимать более активное участие в формировании требуемого выходного значения и так же начинают справляться с задачей.
На практике такой подход требует указания вероятности исключения каждого из нейронов на любой обучающей итерации. Обратите внимание, что указывая вероятность мы можем оказаться в ситуации, когда некоторые нейроны будут отключаться чаще остальных, а некоторые могут не быть отключенными вообще. Однако, это не является проблемой, потому что данный процесс выполняется множество раз и в среднем каждый нейрон с одинаковой вероятностью может быть отключен.
Теперь давайте применим полученные теоретические знания на практике и доработаем наш классификатор изображений кошек и собак.
CoLab: собаки и кошки. Повторение
CoLab на английском языке доступен по этой ссылке. CoLab на русском языке доступен по этой ссылке.
Кошки VS Собаки: классификация изображений с расширением
В этой обучающей части мы обсудим то, каким образом можно классифицировать изображения кошек и собак. Мы разработаем классификатор изображений с использованием tf.keras.Sequential-модели, а для загрузки данных воспользуемся tf.keras.preprocessing.image.ImageDataGenerator.
Идеи, которые будут затронуты в этой части:
Мы получим практический опыт разработки классификатора и разовьём интуитивное понимание следующих концепций:
- Построение модели потока данных (data input pipelines) с использованием
tf.keras.preprocessing.image.ImageDataGenerator-класса (Каким образом эффективно работать с данными на диске взаимодействуя с моделью?) - Переобучение — что это такое и как его определить?
- Расширение данных (data augmentation) и метод исключений (dropout) — ключевые техники в борьбе с переобучением в задач распознавания образов, которые мы внедрим в наш процесс обучения модели.
Мы будем следовать основному подходу при разработке моделей машинного обучения:
- Исследовать и понять данные
- Настроить поток входных данных
- Построить модель
- Обучить модель
- Протестировать модель
- Улучшить модель / Повторить процесс
Перед тем как мы начнем...
Перед тем как запускать код в редакторе, рекомедуем сбросить все настройки в Runtime -> Reset all в верхнем меню. Подобное действие позволит избежать проблем с нехваткой памяти, если параллельно вы работали или работаете с несколькими редакторами.
Импортирование пакетов
Давайте начнём с импорта нужных пакетов:
os— чтение файлов и структуры директорий;numpy— для некоторых матричных операций вне TensorFlow;matplotlib.pyplot— построение графиков и отображение изображений из тестового и валидационного набора данных.
from __future__ import absolute_import, division, print_function, unicode_literals import os import matplotlib.pyplot as plt import numpy as np Импортируем TensorFlow:
import tensorflow as tf from tensorflow.keras.preprocessing.image import ImageDataGeneratorimport logging logger = tf.get_logger() logger.setLevel(logging.ERROR)Загрузка данных
Разработку нашего классификатора мы начинаем с загрузки набора данных. Набор данных, который мы используем представляет собой отфильтрованную версию набора данных Собаки vs Кошки с сервиса Kaggle (в конце концов именно этот набор данных предоставляется Microsoft Research).
В прошлом CoLab мы с вами использовали набор данных из самого TensorFlow Dataset модуля, который оказывается крайне удобным для работы и тестирования. В этом CoLab однако, мы воспользуемся классом tf.keras.preprocessing.image.ImageDataGenerator для чтения данных с диска. Поэтому предварительно нам необходимо загрузить набор данных Собаки VS Кошки и разархивировать его.
_URL = 'https://storage.googleapis.com/mledu-datasets/cats_and_dogs_filtered.zip' zip_dir = tf.keras.utils.get_file('cats_and_dogs_filterted.zip', origin=_URL, extract=True)Набор данных, который мы загрузили, имеет следующую структуру:
cats_and_dogs_filtered |__ train |______ cats: [cat.0.jpg, cat.1.jpg, cat.2.jpg ...] |______ dogs: [dog.0.jpg, dog.1.jpg, dog.2.jpg ...] |__ validation |______ cats: [cat.2000.jpg, cat.2001.jpg, cat.2002.jpg ...] |______ dogs: [dog.2000.jpg, dog.2001.jpg, dog.2002.jpg ...]Чтобы получить полный список директор можно воспользоваться следующей командой:
zip_dir_base = os.path.dirname(zip_dir) !find $zip_dir_base -type d -printВывод (при запуске из CoLab):
/root/.keras/datasets /root/.keras/datasets/cats_and_dogs_filtered /root/.keras/datasets/cats_and_dogs_filtered/train /root/.keras/datasets/cats_and_dogs_filtered/train/dogs /root/.keras/datasets/cats_and_dogs_filtered/train/cats /root/.keras/datasets/cats_and_dogs_filtered/validation /root/.keras/datasets/cats_and_dogs_filtered/validation/dogs /root/.keras/datasets/cats_and_dogs_filtered/validation/catsТеперь присвоим переменным корректные пути к директориям с наборами данных для тренировки и валидации:
base_dir = os.path.join(os.path.dirname(zip_dir), 'cats_and_dogs_filtered') train_dir = os.path.join(base_dir, 'train') validation_dir = os.path.join(base_dir, 'validation') train_cats_dir = os.path.join(train_dir, 'cats') train_dogs_dir = os.path.join(train_dir, 'dogs') validation_cats_dir = os.path.join(validation_dir, 'cats') validation_dogs_dir = os.path.join(validation_dir, 'dogs')Разбираемся с данными и их структурой
Давайте посмотрим сколько же у нас изображений кошек и собак в тестовом и валидационном наборах данных (директориях).
num_cats_tr = len(os.listdir(train_cats_dir)) num_dogs_tr = len(os.listdir(train_dogs_dir)) num_cats_val = len(os.listdir(validation_cats_dir)) num_dogs_val = len(os.listdir(validation_dogs_dir)) total_train = num_cats_tr + num_dogs_tr total_val = num_cats_val + num_dogs_valprint('Кошек в тестовом наборе данных: ', num_cats_tr) print('Собак в тестовом наборе данных: ', num_dogs_tr) print('Кошек в валидационном наборе данных: ', num_cats_val) print('Собак в валидационном наборе данных: ', num_dogs_val) print('--') print('Всего изображений в тренировочном наборе данных: ', total_train) print('Всего изображений в валидационном наборе данных: ', total_val)Вывод:
Кошек в тестовом наборе данных: 1000 Собак в тестовом наборе данных: 1000 Кошек в валидационном наборе данных: 500 Собак в валидационном наборе данных: 500 -- Всего изображений в тренировочном наборе данных: 2000 Всего изображений в валидационном наборе данных: 1000Установка параметров модели
Для удобства мы вынесем установку переменных, которые нам понадобятся для дальнейшей обработки данных и тренировки модели, в отдельное объявление:
BATCH_SIZE = 100 # количество тренировочных изображений для обработки перед обновлением параметров модели IMG_SHAPE = 150 # размерность к которой будет преведено входное изображениеРасширение данных
Переобучение обычно происходит в тех случаях, когда в нашем наборе данных мало обучающих примеров. Один из способов устранить нехватку данных — их расширение до нужного количества экземпляров и нужной вариативностью. Расширение данных представляет собой процесс генерации данных из существующих экземпляров путём применения различных трансформаций к исходному набору данных. Целью такого метода является увеличение количества уникальных входных экземпляров, которые модель больше никогда не увидит, что, в свою очередь, позволит модели лучше обобщать входные данные и показывать большую точность на валидационном наборе данных.
С использованием tf.keras мы можем реализовать подобные случайные преобразования и генерацию новых изображений через класс ImageDataGenerator. Нам будет достаточно передать в виде параметров различные трансформации, которые мы хотели бы применить к изображениям, а обо всём остальном во время тренировки модели позаботится сам класс.
Для начала давайте напишем функцию, которая будет отображать изображения полученные в результате случайных преобразований. Затем мы подробнее разберём используемые преобразования в процессе расширения исходного набора данных.
def plotImages(images_arr): fig, axes = plt.subplots(1, 5, figsize=(20,20)) axes = axes.flatten() for img, ax in zip(images_arr, axes): ax.imshow(img) plt.tight_layout() plt.show()Переворачивание изображения по горизонтали
Начать мы можем с простого преобразования — горизонтального переворачивания изображения. Посмотрим, каким образом данное преобразование будет выглядеть применённое на наших исходных изображениях. Чтобы добиться подобной трансформации необходимо передать параметр horizontal_flip=True конструктору класса ImageDataGenerator.
image_gen = ImageDataGenerator(rescale=1./255, horizontal_flip=True) train_data_gen = image_gen.flow_from_directory(batch_size=BATCH_SIZE, directory=train_dir, shuffle=True, target_size=(IMG_SHAPE, IMG_SHAPE))Вывод:
Found 2000 images belonging to 2 classes.Чтобы увидеть преобразование в действии давайте возьмём одно из наших изображений из обучающего набора данных и повторим его пять раз. Преобразование будет произвольным образом применено (или не будет) к каждой копии.
augmented_images = [train_data_gen[0][0][0] for i in range(5)] plotImages(augmented_images)Вывод (2 из 5 изображений):
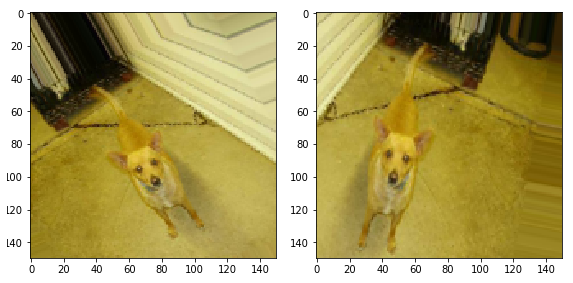
Поворот изображений
Преобразование в виде поворота произвольным образом повернёт изображение на определённое количество градусов. В нашем примере значение угла поворота равно 45.
image_gen = ImageDataGenerator(rescale=1./255, rotation_range=45) train_data_gen = image_gen.flow_from_directory(batch_size=BATCH_SIZE, directory=train_dir, shuffle=True, target_size=(IMG_SHAPE, IMG_SHAPE))Вывод:
Found 2000 images belonging to 2 classes.Чтобы увидеть преобразование мы поступим таким же образом — возьмём одно произвольное изображение из входного набора данных и 5 раз его повторим. Преобразование будет произвольным образом применено (или не применено) к каждой копии.
augmented_images = [train_data_gen[0][0][0] for i in range(5)] plotImages(augmented_images)Вывод (2 изображения из 5):

Применение увеличения
Мы так же можем применить преобразование увеличения к нашему входному набору данных — увеличить произвольно до х50%.
image_gen = ImageDataGenerator(rescale=1./255, zoom_range=0.5) train_data_gen = image_gen.flow_from_directory(batch_size=BATCH_SIZE, directory=train_dir, shuffle=True, target_size=(IMG_SHAPE, IMG_SHAPE))Вывод:
Found 2000 images belonging to 2 classes.Поступим так же, как поступали в прошлый раз — 5 раз повторим одно из входных изображений. Преобразование будет (или не будет) случайным образом применено к каждой копии изображения.
augmented_images = [train_data_gen[0][0][0] for i in range(5)] plotImages(augmented_images)Вывод (2 из 5 изображений):

Объединяем всё вместе
Мы можем применить все приведённые выше преобразования, и даже больше, одной строкой кода, лишь передавая нужные аргументы с нужными значениями конструктору класса ImageDataGenerator.
Пора объединить все использованные ранее преобразования — изменение размеров изображения, поворот на 45 градусов, смещение по ширине, смещение по высоте, горизонтальный переворот и увеличение.
image_gen_train = ImageDataGenerator( rescale=1./255, rotation_range=40, width_shift_range=0.2, height_shift_range=0.2, shear_range=0.2, zoom_range=0.2, horizontal_flip=True, fill_mode='nearest' ) train_data_gen = image_gen_train.flow_from_directory(batch_size=BATCH_SIZE, directory=train_dir, shuffle=True, target_size=(IMG_SHAPE, IMG_SHAPE), class_mode='binary')Вывод:
Found 2000 images belonging to 2 classes.Давайте визуализируем то, каким образом будут выглядеть изображения к которым будут применены произвольные преобразования.
augmented_images = [train_data_gen[0][0][0] for i in range(5)] plotImages(augmented_images)Вывод (2 изображения из 5):

Создаём валидационный набор данных
В основном, расширение данных применяется на обучающем наборе данных, чтобы они представляли собой репрезентативную выборку того, каким образом будут выглядеть настоящие входные данные с которыми предстоит работать модели. Поэтому к валидационному набору данных мы никаких преобразований, кроме изменения размера, не применяем.
image_gen_val = ImageDataGenerator(rescale=1./255) val_data_gen = image_gen_val.flow_from_directory(batch_size=BATCH_SIZE, directory=validation_dir, target_size=(IMG_SHAPE, IMG_SHAPE), class_mode='binary')Создание модели
Описываем модель
Модель состоит из 4 блоков свёртки после каждого из которых следует блок со слоем подвыборки.
Перед последним полносвязным слоем мы так же применяем исключение со значением вероятности 0.5. Это означает, что 50% значений поступающих на вход этому слою будут сброшены до 0. Это позволит избежать переобучения.
Далее у нас идёт полносвязный слой с 512 нейронами и функцией активации relu. Модель выдаст распределение вероятностей по двум классам — собаки и кошки — используя softmax.
model = tf.keras.models.Sequential([ tf.keras.layers.Conv2D(32, (3,3), activation='relu', input_shape=(IMG_SHAPE, IMG_SHAPE, 3)), tf.keras.layers.MaxPooling2D(2, 2), tf.keras.layers.Conv2D(64, (3, 3), activation='relu'), tf.keras.layers.MaxPooling2D(2, 2), tf.keras.layers.Conv2D(128, (3, 3), activation='relu'), tf.keras.layers.MaxPooling2D(2, 2), tf.keras.layers.Conv2D(128, (3, 3), activation='relu'), tf.keras.layers.MaxPooling2D(2, 2), tf.keras.layers.Dropout(0.5), tf.keras.layers.Flatten(), tf.keras.layers.Dense(512, activation='relu'), tf.keras.layers.Dense(2, activation='softmax') ])Компилирование модели
Как и ранее мы воспользуемся оптимизатором adam. В качестве функции потерь воспользуемся sparse_categorical_crossentropy. Так же мы хотим на каждой обучающей итерации следить за точностью модели, поэтому передаём значение accuracy в параметр metrics:
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])Представление модели
Давайте взглянем на структуру нашей модели по уровням используя метод summary:
model.summary()Вывод:
Model: "sequential" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= conv2d (Conv2D) (None, 148, 148, 32) 896 _________________________________________________________________ max_pooling2d (MaxPooling2D) (None, 74, 74, 32) 0 _________________________________________________________________ conv2d_1 (Conv2D) (None, 72, 72, 64) 18496 _________________________________________________________________ max_pooling2d_1 (MaxPooling2 (None, 36, 36, 64) 0 _________________________________________________________________ conv2d_2 (Conv2D) (None, 34, 34, 128) 73856 _________________________________________________________________ max_pooling2d_2 (MaxPooling2 (None, 17, 17, 128) 0 _________________________________________________________________ conv2d_3 (Conv2D) (None, 15, 15, 128) 147584 _________________________________________________________________ max_pooling2d_3 (MaxPooling2 (None, 7, 7, 128) 0 _________________________________________________________________ dropout (Dropout) (None, 7, 7, 128) 0 _________________________________________________________________ flatten (Flatten) (None, 6272) 0 _________________________________________________________________ dense (Dense) (None, 512) 3211776 _________________________________________________________________ dense_1 (Dense) (None, 2) 1026 ================================================================= Total params: 3,453,634 Trainable params: 3,453,634 Non-trainable params: 0 _________________________________________________________________Тренировка модели
Настала пора тренировки модели!
Так как обучающие блоки будут поступать из генератора (ImageDataGenerator) мы воспользуемся методом fit_generator вместо ранее используемого метода fit:
EPOCHS = 100 history = model.fit_generator( train_data_gen, steps_per_epoch=int(np.ceil(total_train / float(BATCH_SIZE))), epochs=EPOCHS, validation_data=val_data_gen, validation_steps=int(np.ceil(total_val / float(BATCH_SIZE))) )Визуализация результатов тренировки
Теперь мы визуализируем результаты тренировки нашей модели:
acc = history.history['acc'] val_acc = history.history['val_acc'] loss = history.history['loss'] val_loss = history.history['val_loss'] epochs_range = range(EPOCHS) plt.figure(figsize=(8,8)) plt.subplot(1, 2, 1) plt.plot(epochs_range, acc, label='Точность на обучении') plt.plot(epochs_range, val_acc, label='Точность на валидации') plt.legend(loc='lower right') plt.title('Точность на обучающих и валидационных данных') plt.subplot(1, 2, 2) plt.plot(epochs_range, loss, label='Потери на обучении') plt.plot(epochs_range, val_loss, label='Потери на валидации') plt.legend(loc='upper right') plt.title('Потери на обучающих и валидационных данных') plt.savefig('./foo.png') plt.show()Вывод:
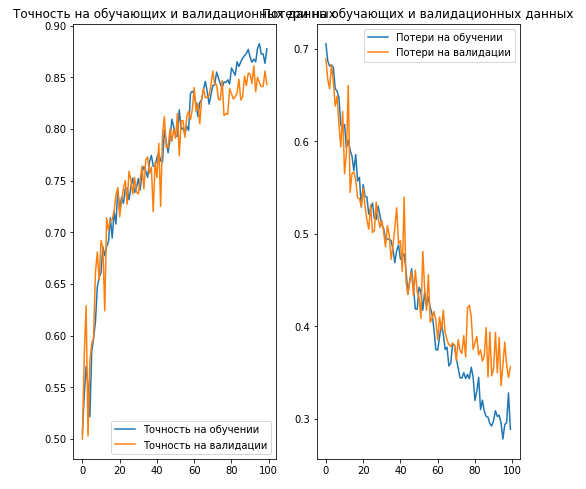
Другие техники для предотвращения переобучения
На этом занятии мы познакомились с тремя техниками, которые позволят избежать переобучения:
- Ранняя остановка: при использовании данного метода мы отслеживаем значение функции потерь на валидационном наборе данных в процессе обучающих итераций и определяем точку останова (прекращения дальнейшего обучения модели).
- Расширение данных (т.н. augmentation): искусственным путём увеличиваем обучающий набор данных путём применения произвольных преобразований к каждому элементу входного набора данных.
- Исключение / Отключение (т.н. dropout): отключение произвольного количества нейронов в сети во время процесса обучения (их значения не учитываются, а веса и смещения не изменяются).
Мы рассмотрели некоторые наиболее популярные техники борьбы с переобучением, однако это далеко не всё. Больше про существующие методы борьбы с переобучением можно узнать из этой статьи.
Упражнение: классификация изображений цветов
Оригинальный CoLab на английском языке доступен по этой ссылке. CoLab на русском языке доступен по этой ссылке.
Теперь настала пора вам применить все полученные знания и построить свёрточную нейронную сеть для классификации цветов. Мы специально создали почти пустой CoLab для создания свёрточной нейронной сети и её тренировки. В этом CoLab мы загрузим набор данных изображениц цветов и разделим его на обучающий набор данных и валидационный. В отдельном CoLab мы так же предоставим решение этого упражнения, что бы вы могли свериться с ним и сравнить собственные результаты с нашими.
Мы настоятельно рекомендуем писать весь код самому и не копировать готовые решения из предыдущих CoLab. В конце CoLab мы хотим предложить вам поиграться со значениями параметров, гиперпараметров и поэкспериментировать с различными архитектурами моделей, чтобы определить какая же из них даст нибольшую точность.
Наслаждайтесь!
# Классификация изображений с использованием tf.keras В этом CoLab вы будете классифицировать изображения цветов. Вы будете разрабатывать классификатор изображений с использованием tf.keras.Sequential, а данные загружать с использованием ImageDataGenerator.
Импортирование пакетов
Давайте начнем с импортирования необходимых пакетов. os пакет нужен нам для чтения файлов и структуры директорий, numpy нужен нам для преобразования python-списков в numpy-массивы для выполнения матричных операций и, в завершение, нам понадобится matplotlib.pyplot для отрисовки графиков и отображения исходных и преобразованных изображений.
from __future__ import absolute_import, division, print_function, unicode_literals import os import numpy as np import glob import shutil import matplotlib.pyplot as pltTODO: импортируем TensorFlow и Keras-слои
В приведённой ниже области для исходного кода импортируйте TensorFlow как tf и Keras-слои с моделями, которые вы будете использовать для построения свёрточной нейронной сети. Так же, импортируйте ImageDataGenerator-класс из Keras для работы с изображениями и расширения исходного набора данных.
# импорт пакетовЗагрузка данных
Начать разработку нашего классификатора изображений нужно с загрузки набора данных с которым мы будем работать — цветочный набор данных. Первым делом необходимо загрузить архив с набором данных и сохранить его во временной директории.
Загруженный архив необходимо разархивировать.
_URL = "https://storage.googleapis.com/download.tensorflow.org/example_images/flower_photos.tgz" zip_file = tf.keras.utils.get_file(origin=_URL, fname="flower_photos.tgz", extract=True) base_dir = os.path.join(os.path.dirname(zip_file), 'flower_photos')Набор данных, который мы загрузили архивом, содержит 5 типов цветов:
- Розы
- Маргаритки
- Одуванчики
- Подсолнухи
- Тюльпаны
Создадим метки для каждого из этих пяти классов:
classes = ['розы', 'маргаритки', 'одуванчики', 'подсолнухи', 'тюльпаны']Набор данных, который мы загрузили, имеет следующую структуру:
flower_photos |__ diasy |__ dandelion |__ roses |__ sunflowers |__ tulipsКак вы уже обратили внимание в структуре загруженного набора данных отсутствуют директории с обучающим набором данных и валидационным. Таким образом создание этих двух наборов данных будет лежать на наших плечах. Давайте напишем код, который будет это делать.
Код ниже создаёт 2 директории train и val в каждой из которых будет 5 под-директорий (одна на каждый тип изображения). После этого мы переместим изображения в эти директории таким образом, чтобы 80% изображений попадало в обучающий набор данных, а остальные 20% попадали в валидационный набор данных. Итоговая структура будет выглядеть следующим образом:
flower_photos |__ diasy |__ dandelion |__ roses |__ sunflowers |__ tulips |__ train |______ daisy: [1.jpg, 2.jpg, 3.jpg ....] |______ dandelion: [1.jpg, 2.jpg, 3.jpg ....] |______ roses: [1.jpg, 2.jpg, 3.jpg ....] |______ sunflowers: [1.jpg, 2.jpg, 3.jpg ....] |______ tulips: [1.jpg, 2.jpg, 3.jpg ....] |__ val |______ daisy: [507.jpg, 508.jpg, 509.jpg ....] |______ dandelion: [719.jpg, 720.jpg, 721.jpg ....] |______ roses: [514.jpg, 515.jpg, 516.jpg ....] |______ sunflowers: [560.jpg, 561.jpg, 562.jpg .....] |______ tulips: [640.jpg, 641.jpg, 642.jpg ....] Так как мы не удаляем исходные директории, то они останутся у нас, но будут пустыми. Код ниже так же выведет на экран количество изображений по каждому типу цветка.
for cl in classes: img_path = os.path.join(base_dir, cl) images = glob.glob(img_path + '/*.jpg') print("{}: {} изображений".format(cl, len(images))) train, val = images[:round(len(images)*0.8)], images[round(len(images)*0.8):] for t in train: if not os.path.exists(os.path.join(base_dir, 'train', cl)): os.makedirs(os.path.join(base_dir, 'train', cl)) shutil.move(t, os.path.join(base_dir, 'train', cl)) for v in val: if not os.path.exists(os.path.join(base_dir, 'val', cl)): os.makedirs(os.path.join(base_dir, 'val', cl)) shutil.move(v, os.path.join(base_dir, 'val', cl))Для удобства вынесем ссылки на директории каждого набора данных в отдельные переменные:
train_dir = os.path.join(base_dir, 'train') val_dir = os.path.join(base_dir, 'val')Расширение данных
Переобучение, в основном, происходит тогда, когда у нас маленький обучающий набор данных. Один из способов устранить эту проблему — расширение данных (т.н. augmentation) до нужного количества обучающих примеров. Расширение данных представляет собой процесс применения произвольных трансформации к исходным данным и добавление полученных изменённых данных в первоначальный обучающий набор. Цель заключается в том, чтобы сгенерировать реалистичные изображения, которые модель больше никогда не увидит в последующем — ни в валидационном наборе данных, ни в тестовом. Такой подход позволяет модели лучше обобщать и извлекать различные признаки.
В tf.keras мы можем это реализовать с использованием класса, который раньше нами применялся для генерации обучающего набора данных кошек и собак — ImageDataGenerator. Мы просто передаём конструктору класса набор различных значений нужных нам параметров и обо всём остальном он позаботится сам.
Экспериментируйте с различными преобразованиями изображений
В этой части вы получите практический опыт применения некоторых базовых преобразования изображений. Перед тем как мы будем применять преобразования давайте объявим две переменные — одна будет содержать значение количества обучающих блоков (изображений) за одну итерацию batch_size, а вторая размеры нашего изображения на входе в свёрточную нейронную сеть IMG_SHAPE.
TODO: установите количество обучающих блоков и размер изображений
В ячейке ниже укажите значение 100 для переменной batch_size и значение 150 для переменной IMG_SHAPE:
batch_size = IMG_SHAPE = TODO: примените произвольный горизонтальный переворот изображения
В ячейке ниже воспользуйтесь классом ImageDataGenerator для создания преобразования, которое сперва нормализует значения пикселей цветных изображений, а затем применит произвольный горизонтальный переворот. После этого воспользуйтесь методом .flow_from_directory для применения полученного преобразования к изображениям из обучающего набора данных. Убедитесь, что указали корректно размер обучающего блока, путь к директории с обучающим набором данных, целевой размер изображений и не забудьте затем перемешать все изображения.
image_gen = train_data_gen = Давайте возьмём одно произвольное изображение и отобразим его 5 раз применив случайным образом наше преобразование:
def plotImages(images_arr): fig, axes = plt.subplots(1, 5, figsize=(20,20)) axes = axes.flatten() for img, ax in zip(images_arr, axes): ax.imshow(img) plt.tight_layout() plt.show() augmented_images = [train_data_gen[0][0][0] for i in range(5)] plotImages(augmented_images)TODO: примените произвольный переворот изображения
В ячейке ниже, воспользовавшись классом ImageDataGenerator сперва нормализуйте цветное изображение и примените произвольный поворот на 45 градусов. После этого воспользуйтесь методом .flow_from_directory для применения полученного преобразования к изображениям из обучающего набора данных. Убедитесь, что указали корректно размер обучающего блока, путь к директории с обучающим набором данных, целевой размер изображений и не забудьте затем перемешать все изображения.
image_gen = train_data_gen = Давайте возьмём одно произвольное изображение и отобразим его 5 раз применив случайным образом наше преобразование:
augmented_images = [train_data_gen[0][0][0] for i in range(5)] plotImages(augmented_images)TODO: примените произвольное увеличение изображения
В ячейке ниже, воспользовавшись классом ImageDataGenerator сперва нормализуйте цветное изображение и примените произвольное увеличение до 50%. После этого воспользуйтесь методом .flow_from_directory для применения полученного преобразования к изображениям из обучающего набора данных. Убедитесь, что указали корректно размер обучающего блока, путь к директории с обучающим набором данных, целевой размер изображений и не забудьте затем перемешать все изображения.
image_gen = train_data_gen = Давайте возьмём одно произвольное изображение и отобразим его 5 раз применив случайным образом наше преобразование:
augmented_images = [train_data_gen[0][0][0] for i in range(5)] plotImages(augmented_images)TODO: объединяем все изменения
В ячейке ниже укажите код, который использует ImageDataGenerator для нормализации цветного изображения и выполняет следующие преобразования произвольным образом:
- поворот на 45 градусов
- увеличение до 50%
- горизонтальное отражение
- смещение по ширине на 0.15
- смещение по высоте на 0.15
Затем воспользуйтесь методом flow_from_directory для применения перечисленных выше трансформаций к изображениям в обучающем наборе. Убедитесь, что указали корректно размер обучающего блока, путь к директории с обучающим набором данных, целевой размер изображений и не забудьте затем перемешать все изображения.
image_gen_train = train_data_gen = Давайте возьмём одно произвольное изображение и отобразим его 5 раз применив случайным образом наши преобразования:
augmented_images = [train_data_gen[0][0][0] for i in range(5)] plotImages(augmented_images)TODO: создайте генератор изображений для валидационного набора данных
В основном расширение данных применяется к обучающему набору данных. Поэтому, в ячейке ниже, воспользуйтесь классом ImageDataGenerator только для того, чтобы нормализовать значения пикселей цветного изображения. Затем воспользуйтесь методом flow_from_directory для применения указанной единственной трансформации к изображениям в валидационном наборе. Убедитесь, что указали корректно размер валидационного блока, путь к директории с валидационным набором данных и целевой размер изображений. Перемешивать валидационный набор данных не обязательно.
image_gen_val = val_data_gen = TODO: Создайте свёрточную нейронную сеть
В ячейке ниже создайте свёрточную нейронную сеть, которая будет состоять из 3 свёрточных пар — слой свёртки и слой подвыборки по максимальному значению. Первый свёрточный слой должен иметь 16 фильтров, второй — 32 фильтра, третий — 64 фильтра. Все фильтры должны быть размером 3х3. Размер окна подвыборки на всех слоях должен быть размером 2х2.
После всех трёх свёрточных пар должен идти слой Flatten, а затем полносвязный слой с 512 нейронами. Свёрточная нейронная сеть на выходе должна выдавать распределение вероятностей по 5 классам, чего можно добиться использованием функции активации softmax. Все остальные слои должны использовать функцию активации relu. Так же, где имеет смысл, добавьте слой отключения нейронов с вероятностью 20%.
model = TODO: скомпилируйте модель
В ячейке ниже напишите код, который будет компилировать модель с использованием оптимизатора adam и использовать sparse_categorical_crossentropy в качестве функции потерь. Так же мы хотим отслеживать метрику точности на обучающем наборе данных и валидационном наборе на каждой обучающей итерации, поэтому не забудьте передать соответствующий параметр в метод compile(...).
# компилирование моделиTODO: обучите модель
В ячейке ниже напишите код, который запустит обучение модели с использованием функции fit_generator вместо обычной функции fit, которую мы ранее использовали. Мы используем функцию fit_generator потому что прибегаем к использованию класса ImageDataGenerator для генерации новых обучающих и валидационных данных для нашей модели. Обучите модель на 80 итерациях и убедитесь, что используете подходящие параметры в fit_generator-функции.
epochs = history = TODO: постройте графики точности / потерь для обучающего и валидационного наборов данных
В ячейке ниже напишите код, который построит графики точности и потерь для обучающего и валидационного наборов данных:
acc = val_acc = loss = val_loss = epochs_range = TODO: поэкспериментируйте с различными параметрами
Дойдя до этого момента вы создали свёрточную нейронную сеть с тремя свёрточными блоками (слой свёртки + слой подвыборки) и последующим полносвязным слоем состоящим из 512 нейронов. В ячейке ниже напишите код для создания новой свёрточной сети с другой архитектурой. Не бойтесь экспериментировать со значениями параметров. Например, вы можете добавить больше свёрточных или полносвязных слоёв с различным количеством нейронов, изменить параметры слоя отключения нейронов и т.п. Вы так же можете поэкспериментировать с большим количеством преобразований, используя тот самый класс ImageDataGenerator — изменять произвольным образом яркость изображения или смещения по осям. Поэкспериментируйте с как можно большим количеством изменений, чтобы у вас была возможность сравнить точность работы модели по различным комбинациям параметров.
Изменения каких параметров дают наибольший результат?
Итоги
В этой части мы рассмотрели как свёрточные нейронные сети работают с цветными изображениями и каким образом можно избежать их переобучения.
Основные моменты из прошедшей главы относительно свёрточных нейронных сетей при работе с RGB-изображениями различного размера:
- Изменение размеров: при работе с изображениями различных размеров, перед тем как подавать их на вход свёрточной нейронной сети необходимо привести эти изображения к одному размеру (одинаковая ширина и высота);
- Цветные изображения: компьютер интерпретирует цветные изображения как 3D-массивы;
- RGB-изображения: цветные изображения состоящие из 3 цветовых каналов: красного, зеленого и синего;
- Свёртка: выполняя операцию свёртки цветного изображения мы применяем эту операцию к каждому цветовому каналу изображения используя свой фильтр (ядро). Операция свёртки на каждом цветовом канале выполняется аналогично операции свёртки на изображениях в оттенках серого, через поэлементное умножение значений пикселей изображения и значений фильтра (ядра). Полученные итоговые значения суммируются и прибавляется значение смещения — результатирующее значение записывается в выходное представление.
- Подвыборка по максимальному значению: выполняя операцию подвыборки по максимальному значению мы выполняем её на каждом цветовом канале с тем же размером окна фильтра и тем же шагом. Операция подвыборки по максимальному значению на цветовых каналах выполняется таким же образом, как и на единственном канале в изображении в оттенках серого.
- Валидационный набор данных: мы используем валидационный набор данных с целью контроля точности работы модели во время процесса обучения. Валидационный набор данных может так же использоваться для преждевременной остановки процесса обучения во избежание переобучения, а так же подобный набор может помочь нам в сравнении различных архитектур моделей и выборе лучшей.
Методы для избежания переобучения:
- Преждевременная остановка: при использовании этого метода мы вычисляем значение функции потерь на валидационном наборе данных во время обучения и останавливаем дальнейшее обучение, если значение функции потерь начинает увеличиваться.
- Расширение изображений: искусственное увеличение количества изображений в обучающей выборке путём применения различных и произвольных комбинаций преобразований к исходных изображениям в обучающей выборке.
- Исключение (отключение): отключение произвольного количества нейронов в сети в процессе обучения.
Мы так же разработали и обучили свёрточную нейронную сеть классифицировать изображения кошек и собак без использования расширений изображений и отключения нейронов в сети. Как вы уже смогли убедиться на примере, расширение изображений и произвольные отключения нейронов в процессе обучения позволили нашей модели увеличить точность на валидационном наборе данных и избежать переобучения. А в качестве упражнения у вас была возможность применить полученные знания для создания свёрточной нейронной сети для классификации изображений цветов.
… и стандартные call-to-action — подписывайся, ставь плюс и делай share :)
YouTube Telegram ВКонтакте
Телеграм: t.me/ainewsline
Источник: habr.com