Нейросети и глубокое обучение, глава 4: визуальное доказательство того, что нейросети способны вычислить любую функцию
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2019-07-29 10:35

Один из наиболее потрясающих фактов, связанных с нейросетями, заключается в том, что они могут вычислить вообще любую функцию. То есть, допустим, некто даёт вам какую-то сложную и извилистую функцию f(x):

Теорема универсальности хорошо знакома людям, использующим нейросети. Но хотя это так, понимание этого факта не так широко распространено. А большинство объяснений этого слишком технически сложные. К примеру, одна из первых работ, доказывающих этот результат, использовала теорему Хана — Банаха, теорему представлений Риса и немного анализа Фурье. Если вы математик, вам несложно разобраться в этих доказательствах, но большинству людей это не так-то просто. А жаль, поскольку базовые причины универсальности просты и прекрасны. В данной главе я даю простое и по большей части визуальное объяснение теоремы универсальности. Мы шаг за шагом пройдём по лежащим в её основе идеям. Вы поймёте, почему нейросети действительно могут вычислить любую функцию. Вы поймёте некоторые ограничения этого результата. И поймёте, как результат связан с глубокими НС. Чтобы следить за материалом этой главы, не обязательно читать предыдущие. Он структурирован в виде самостоятельного эссе. Если у вас есть самое базовое представление о НС, вы должны суметь понять объяснения. Но я буду иногда давать ссылки на предыдущие материалы, чтобы помочь заполнить пробелы в знаниях.
Теоремы универсальности часто встречаются в информатике, так, что иногда мы даже забываем, насколько они потрясающие. Но стоит напоминать себе: возможность вычислить любую произвольную функцию поистине удивительна. Практически любой процесс, который вы можете себе представить, можно свести к вычислению функции. Рассмотрим задачу поиска названия музыкальной композиции на основе краткого отрывка. Это можно считать вычислением функции. Или рассмотрим задачу перевода китайского текста на английский. И это можно считать вычислением функции (на самом деле, многих функций, поскольку существует множество приемлемых вариантов переводов одного текста). Или рассмотрим задачу генерации описания сюжета фильма и качества актёрской игры на основе файла mp4. Это тоже можно рассматривать, как вычисление некоей функции (здесь тоже верна ремарка, сделанная по поводу вариантов перевода текста). Универсальность означает, что в принципе, НС могут выполнять все эти задачи, и множество других.
Конечно, только из того, что мы знаем, что существуют НС, способные, допустим, переводить с китайского на английский, не следует, что у нас есть хорошие техники для создания или даже распознавания такой сети. Это ограничение также применимо к традиционным теоремам универсальности для таких моделей, как Булевы схемы. Но, как мы уже видели в этой книге, у НС есть мощные алгоритмы для выучивания функций. Комбинация алгоритмов обучения и универсальности – смесь привлекательная. Пока что в книге мы концентрировались на обучающих алгоритмах. В данной главе мы сконцентрируемся на универсальности и на том, что она означает.
Два подвоха
До того, как объяснить, почему теорема универсальности верна, я хочу упомянуть два подвоха, содержащихся в неформальном заявлении «нейросеть может вычислить любую функцию».
Во-первых, это не значит, что сеть можно использовать для точного подсчёта любой функции. Мы лишь можем получить настолько хорошее приближение, насколько нам нужно. Увеличивая количество скрытых нейронов, мы улучшаем аппроксимацию. К примеру, ранее я иллюстрировал сеть, вычисляющую некую функцию f(x) с использованием трёх скрытых нейронов. Для большинства функций при помощи трёх нейронов можно будет получить только низкокачественное приближение. Увеличив количество скрытых нейронов (допустим, до пяти), мы обычно можем получить улучшенное приближение:
Второй подвох состоит в том, что функции, которые можно аппроксимировать описанным способом, принадлежат к непрерывному классу. Если функция прерывается, то есть, делает внезапные резкие скачки, то в общем случае её будет невозможно аппроксимировать при помощи НС. И это неудивительно, поскольку наши НС вычисляют непрерывные функции от входных данных. Однако, даже если функция, которую нам очень нужно вычислить, разрывная, часто оказывается достаточно непрерывной аппроксимации. Если это так, то мы можем использовать НС. На практике это ограничение обычно не является важным.
В итоге, боле точным утверждением теоремы универсальности будет то, что НС с одним скрытым слоем можно использовать для аппроксимации любой непрерывной функции с любой желаемой точностью. В данной главе мы докажем чуть менее строгую версию этой теоремы, используя два скрытых слоя вместо одного. В задачах я кратко опишу как это объяснение можно, с небольшими изменениями, адаптировать к доказательству, использующему только один скрытый слой.
Универсальность с одним входным и одним выходным значением
Чтобы понять, почему теорема универсальности истинна, начнём с понимания того, как создать НС, аппроксимирующую функцию только с одним входным и одним выходным значением:

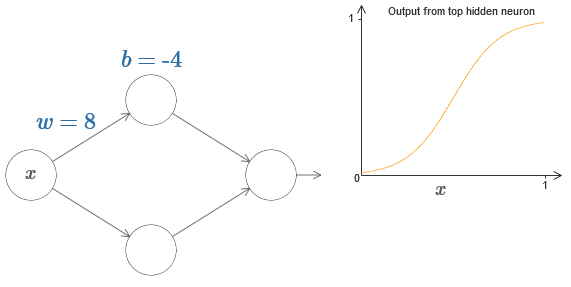
Затем протяните его влево, чтобы уменьшить смещение. Вы увидите, что график двигается вправо, не меняя форму.
Уменьшите вес до 2-3. Вы увидите, что с уменьшением веса кривая распрямляется. Чтобы кривая не убегала с графика, возможно, придётся подправить смещение.
Наконец, увеличьте вес до значений более 100. Кривая будет становиться всё круче, и в итоге приблизится к ступеньке. Попробуйте подрегулировать смещение так, чтобы её угол находился в районе точки x=0,3. На видео ниже показано, что должно получиться:
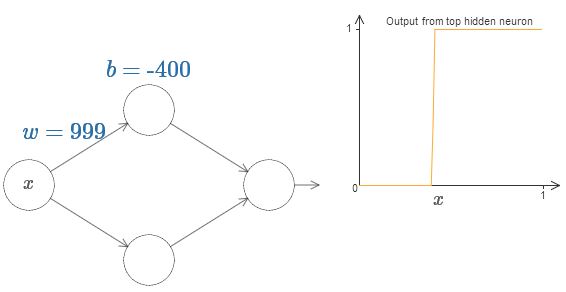
Для ответа на вопрос попытайтесь изменить вес и смещение в интерактивной диаграмме. Можете ли вы понять, как положение ступеньки зависит от w и b? Попрактиковавшись немного, вы сможете убедить себя, что её положение пропорционально b и обратно пропорционально w.
На самом деле, ступенька находится на отметке s=?b/w, как будет видно, если подстроить вес и смещение к следующим значениям:
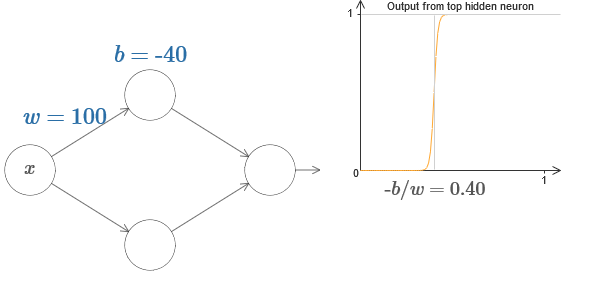

Кстати, отметим, что выход всей сети равен ?(w1a1 + w2a2 + b), где b – смещение выходного нейрона. Это, очевидно, не то же самое, что взвешенный выход скрытого слоя, график которого мы строим. Но пока мы сконцентрируемся на взвешенном выходе скрытого слоя, и только позднее подумаем, как он связан с выходом всей сети.
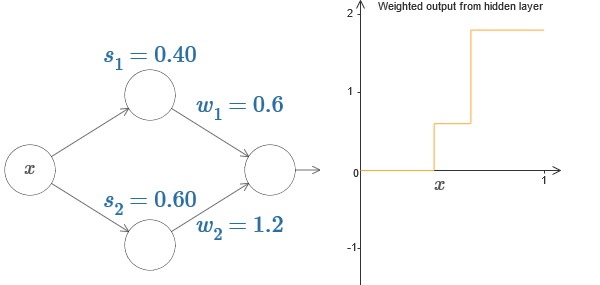
Попробуйте на интерактивной диаграмме в оригинале статьи увеличивать и уменьшать ступеньку s1 верхнего скрытого нейрона. Посмотрите, как это меняет взвешенный выход скрытого слоя. Особенно полезно понять, что происходит, когда s1 превышает s2. Вы увидите, что график в этих случаях меняет форму, поскольку мы переходим от ситуации, в которой верхний скрытый нейрон активируется первым, к ситуации, в которой нижний скрытый нейрон активируется первым.
Сходным образом попробуйте манипулировать ступенькой s2 у нижнего скрытого нейрона, и посмотрите, как это меняет общий выход скрытых нейронов.
Попробуйте уменьшать и увеличивать выходные веса. Заметьте, как это масштабирует вклад от соответствующих скрытых нейронов. Что будет, если один из весов сравняется с 0?
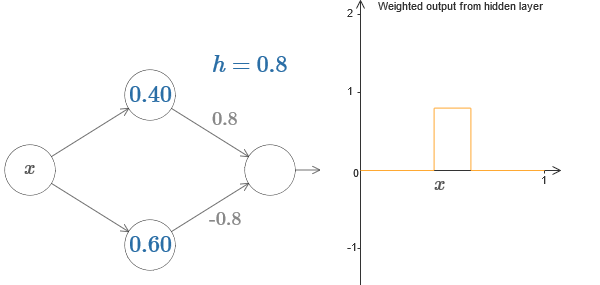
Наконец, попробуйте выставить w1 в 0,8, а w2 в -0,8. Получится функция «выступа», с началом в точке s1, концом в точке s2, и высотой 0,8. К примеру, взвешенный выход может выглядеть так:
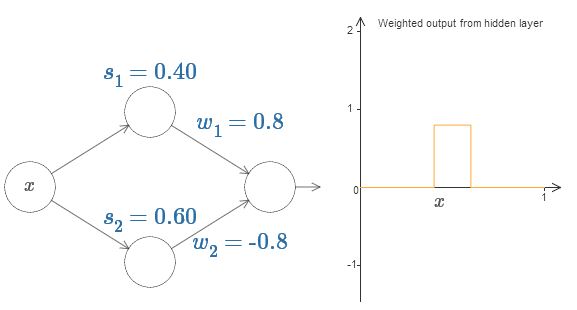
if вход >= начало ступеньки:
добавить 1 к взвешенному выходу
else:
добавить 0 к взвешенному выходу
По большей части я буду придерживаться графических обозначений. Однако иногда вам будет полезно переключаться на представление if-then-else и размышлять о происходящем в этих терминах.
Мы можем использовать наш трюк с появлением выступа, склеив две части скрытых нейронов вместе в одной сети:
На диаграмме можно ещё кликнуть по графику, и потаскать высоту ступеньки вверх или вниз. При изменении её высоты вы видите, как изменяется высота соответствующего h. Соответствующим образом меняются выходные веса +h и –h. Иначе говоря, мы напрямую манипулируем функцией, график которой показан справа, и видим эти изменения в значениях h слева. Можно ещё зажать клавишу мыши на одном из выступов, а потом провести мышью влево или вправо, и выступы будут подстраиваться под текущую высоту.
Настало время справиться с задачей.
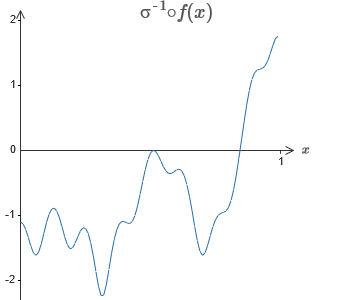
Вспомним функцию, которую я нарисовал в самом начале главы:
Она строится для значений x от 0 до 1, а значения по оси y варьируются от 0 до 1.
Очевидно, что эта функция нетривиальная. И вы должны придумать, как подсчитать её с использованием нейросетей.
В наших нейросетях выше мы анализировали взвешенную комбинацию ?jwjaj выхода скрытых нейронов. Мы знаем, как получить значительный контроль над этой величиной. Но, как я отметил ранее, эта величина не равна выходу сети. Выход сети – это ?(?jwjaj + b), где b – смещение выходного нейрона. Можем ли мы получить контроль непосредственно над выходом сети?
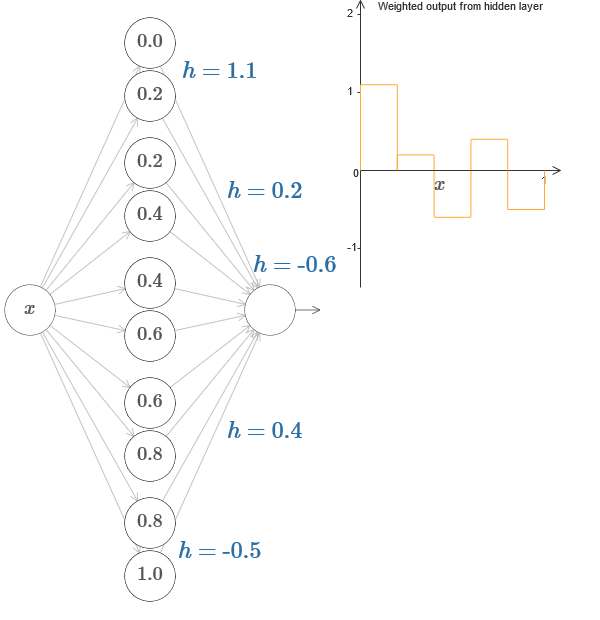
Решение – разработать такую нейросеть, у которой взвешенный выход скрытого слоя задаётся уравнением ??1?f(x), где ??1 — обратная функция ?. То есть, мы хотим, чтобы взвешенный выход скрытого слоя был таким:
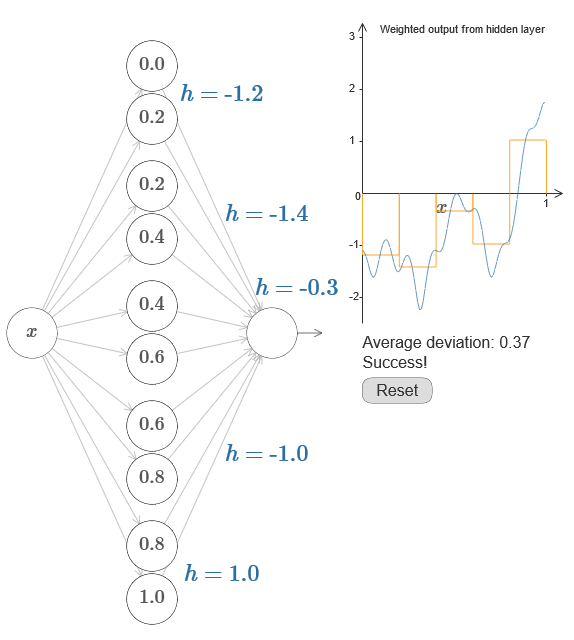
В частности, легко превратить все найденные данные обратно в стандартный вид с параметризацией, используемый для НС. Позвольте быстро напомнить, как это работает.
У первого слоя все веса имеют большое постоянное значение, к примеру, w=1000.
Смещения скрытых нейронов вычисляются через b=?ws. Так что, к примеру, для второго скрытого нейрона s=0,2 превращается в b=?1000?0,2=?200.
Последний слой весов определяется значениями h. Так что, к примеру, значение, выбранное вами для первого h, h= -0,2, означает, что выходные веса двух верхних скрытых нейронов равны -0,2 и 0,2 соответственно. И так далее, для всего слоя выходных весов.
Наконец, смещение выходного нейрона равно 0.
И это всё: у нас получилось полное описание НС, неплохо вычисляющей изначальную целевую функцию. И мы понимаем, как улучшить качество аппроксимации, улучшая количество скрытых нейронов.
Кроме того, в нашей оригинальной целевой функции f(x)=0,2+0,4x2+0,3sin(15x)+0,05cos(50x) нет ничего особенного. Подобную процедуру можно было бы использовать для любой непрерывной функции на отрезках от [0,1] до [0,1]. По сути, мы используем нашу однослойную НС для построения справочной таблицы по функции. И мы можем взять эту идею за основу, чтобы получить обобщённое доказательство универсальности.
Функция от многих параметров
Расширим наши результаты на случай множества входящих переменных. Звучит сложно, но все нужные нам идеи можно понять уже для случая всего с двумя входящими переменными. Поэтому рассмотрим случай с двумя входящими переменными.
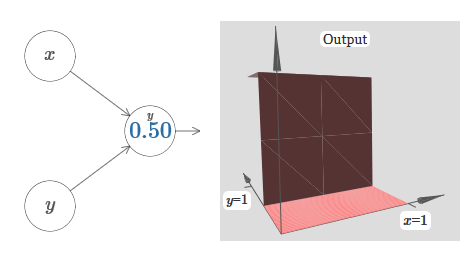
Начнём с рассмотрения того, что будет, когда у нейрона есть два входа:
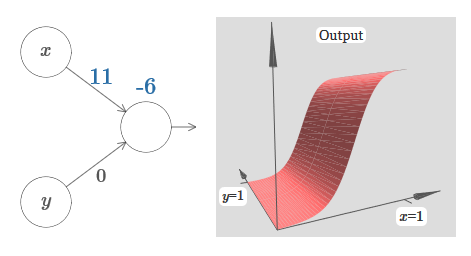
Учитывая это, что, как вы думаете, произойдёт, когда мы увеличим вес w1 до w1=100, а w2 оставим 0? Если это сразу вам непонятно, подумайте немного над этим вопросом. Потом посмотрите следующее видео, где показано, что произойдёт:
Давайте переделаем диаграмму, чтобы параметром было местоположение ступеньки:
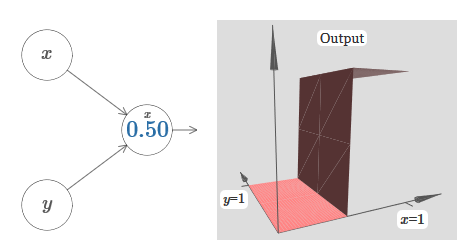
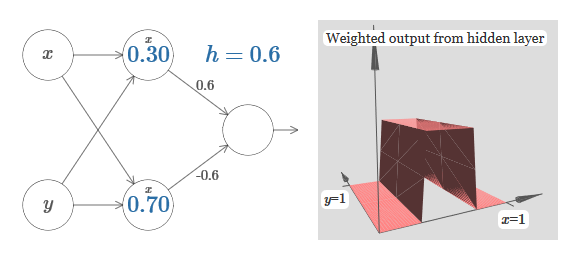
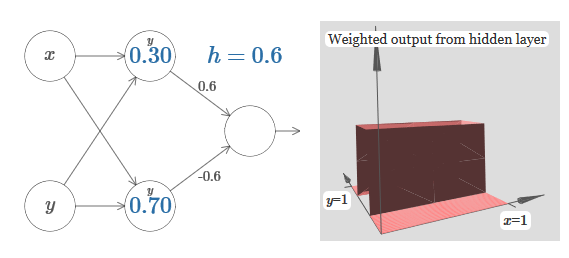
Мы узнали, как построить функцию выступа по оси x. Естественно, мы легко можем сделать функцию выступа и по оси y, используя две ступенчатые функции по оси y. Вспомним, что мы можем сделать это, сделав большие веса на входе y, и установив вес 0 на входе x. И вот, что получится:

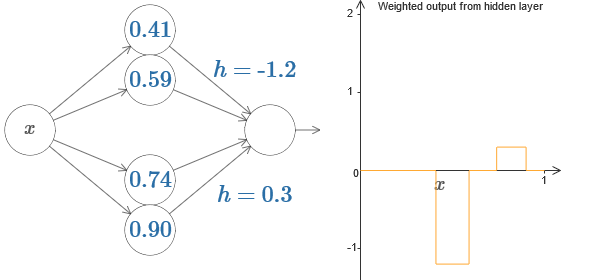
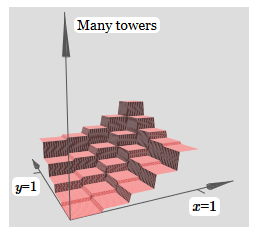
Созданное нами немного похоже на «функцию башни»:
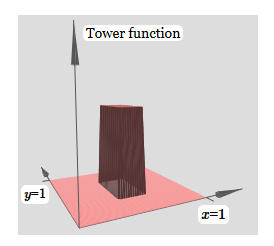 Если мы можем создать такие функции башен, то мы можем использовать их для аппроксимации произвольных функций, просто добавляя башни различных высот в разных местах:
Если мы можем создать такие функции башен, то мы можем использовать их для аппроксимации произвольных функций, просто добавляя башни различных высот в разных местах: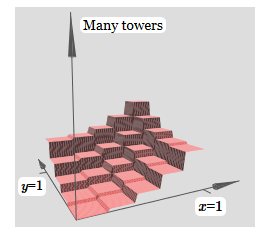 Конечно, мы пока ещё не дошли до создания произвольной функции башни. Мы пока сконструировали что-то вроде центральной башни высоты 2h с окружающим её плато высоты h.
Конечно, мы пока ещё не дошли до создания произвольной функции башни. Мы пока сконструировали что-то вроде центральной башни высоты 2h с окружающим её плато высоты h.Но мы можем сделать функцию башни. Вспомните, что раньше мы показали, как нейроны можно использовать для реализации инструкции if-then-else:
if вход >= порог: выход 1 else: выход 0Это был нейрон с одним входом. А нам нужно применить сходную идею к комбинированному выходу скрытых нейронов:
if скомбинированный выход скрытых нейронов >= порог: выход 1 else: выход 0Если мы правильно выберем порог – к примеру, 3h/2, втиснутый между высотой плато и высотой центральной башни – мы сможем раздавить плато до нуля, и оставить только одну башню.
Представляете, как это сделать? Попробуйте поэкспериментировать со следующей сетью. Теперь мы строим график выхода всей сети, а не просто взвешенный выход скрытого слоя. Это значит, что мы добавляем член смещения к взвешенному выходу от скрытого слоя, и применяем сигмоиду. Сможете ли вы найти значения для h и b, при которых получится башня? Если вы застрянете на этом моменте, вот две подсказки: (1) чтобы выходящий нейрон продемонстрировал правильное поведение в стиле if-then-else, нам нужно, чтобы входящие веса (все h или –h) были крупными; (2) значение b определяет масштаб порога if-then-else.
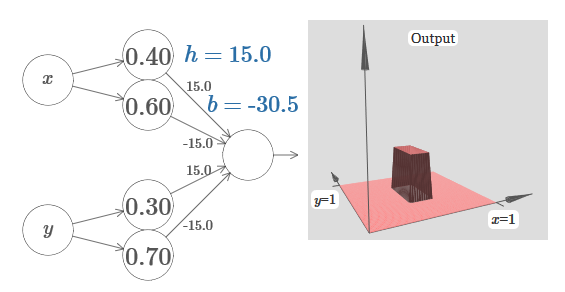
 В частности, заставив взвешенный выход второго скрытого слоя хорошо аппроксимировать ??1?f, мы гарантируем, что выход нашей сети будет хорошей аппроксимацией желаемой функции f.
В частности, заставив взвешенный выход второго скрытого слоя хорошо аппроксимировать ??1?f, мы гарантируем, что выход нашей сети будет хорошей аппроксимацией желаемой функции f.А что же насчёт функций многих переменных?
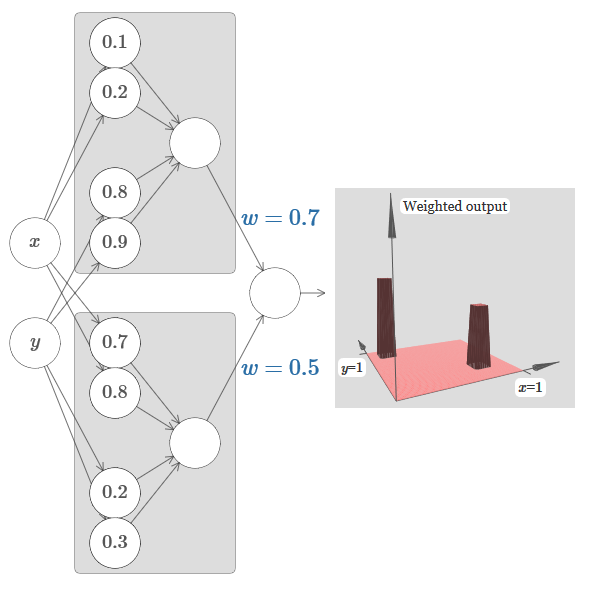
Попробуем взять три переменных, x1,x2,x3. Следующую сеть можно использовать для подсчёта функции башни в четырёх измерениях?
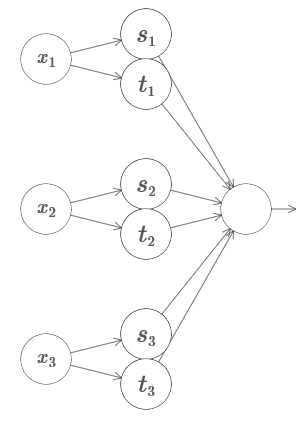
Сеть вычисляет функцию, равную 1, при выполнении трёх условий: x1 находится между s1 и t1; x2 находится между s2 и t2; x3 находится между s3 и t3. Сеть равна 0 во всех других местах. Это такая башня, у которой 1 – небольшой участок пространства входа, и 0 – всё остальное.
Склеивая множество таких сетей, мы можем получить сколько угодно башен, и аппроксимировать произвольную функцию трёх переменных. Та же идея работает в m измерений. Меняется только выходное смещение (?m+1/2)h, чтобы правильно втиснуть нужные значения и убрать плато.
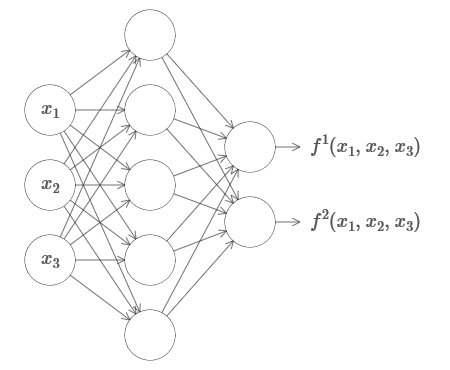
Хорошо, теперь мы знаем, как использовать НС для аппроксимации вещественной функции многих переменных. Что насчёт векторных функций f(x1,…,xm) ? Rn? Конечно, такую функцию можно рассматривать, просто как n отдельных вещественных функций f1(x1,…,xm), f2(x1,…,xm), и так далее. А потом мы просто склеиваем все сети вместе. Так что с этим легко разобраться.
Задача
- Мы увидели, как использовать нейросети с двумя скрытыми слоями для аппроксимации произвольной функции. Можете ли вы доказать, что это возможно делать с одним скрытым слоем? Подсказка – попробуйте работать с всего двумя выходными переменными, и показать, что: (a) возможно получить функции ступенек не только по осям x или y, но и в произвольном направлении; (b) складывая множество конструкций с шага (a), возможно аппроксимировать функцию круглой, а не прямоугольной башни; © используя круглые башни, возможно аппроксимировать произвольную функцию. Шаг © будет проще сделать, используя материал, представленный в этой главе немного ниже.
Выход за рамки сигмоидных нейронов
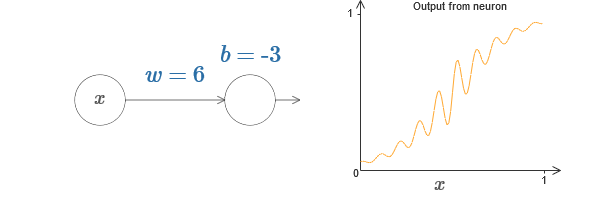
Мы доказали, что сеть, состоящая из сигмоидных нейронов, может вычислить любую функцию. Вспомним, что в сигмоидном нейроне входы x1,x2,… превращаются на выходе в ?(?jwjxj + b), где wj — веса, b – смещение, ? — сигмоида.

Мы можем использовать эту функцию активации для получения ступенчатой, точно так же, как в случае с сигмоидой. Попробуйте (в оригинале статьи) на диаграмме задрать вес до, допустим, w=100:

Задачи
- Ранее в книге мы познакомились с нейроном другого типа — выпрямленным линейным нейроном, или выпрямленной линейной единицей [rectified linear unit, ReLU]. Поясните, почему такие нейроны не удовлетворяют условиям, необходимым для универсальности. Найдите доказательство универсальности, показывающее, что ReLU универсально подходят для вычислений.
- Допустим, мы рассматриваем линейные нейроны, с функцией активации s(z)=z. Поясните, почему линейные нейроны не удовлетворяют условиям универсальности. Покажите, что такие нейроны нельзя использовать для универсальных вычислений.
Исправляем ступенчатую функцию
Покамест мы предполагали, что наши нейроны выдают точные ступенчатые функции. Это неплохое приближение, но лишь приближение. На самом деле существует узкий промежуток отказа, показанный на следующем графике, где функции ведут себя совсем не так, как ступенчатая:
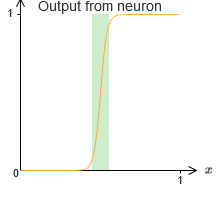 В этом промежутке отказа данное мною объяснение универсальности не работает.
В этом промежутке отказа данное мною объяснение универсальности не работает.
Отказ не такой уж страшный. Задавая достаточно большие входные веса, мы можем делать эти промежутки сколь угодно малыми. Мы можем сделать их гораздо меньшими, чем на графике, невидимыми глазу. Так что, возможно, нам не стоит волноваться из-за этой проблемы.
Тем не менее, хотелось бы иметь некий способ её решения.
Оказывается, её легко решить. Давайте посмотрим на это решение для вычисляющих функции НС со всего одним входом и выходом. Те же идеи сработают и для решения проблемы с большим количеством входов и выходов.
В частности, допустим, мы хотим, чтобы наша сеть вычислила некую функцию f. Как и раньше, мы пытаемся сделать это, проектируя сеть так, чтобы взвешенный выход скрытого слоя нейронов был ??1?f(x):
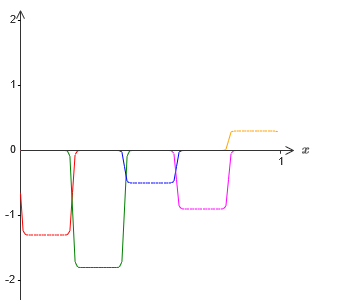
Но, допустим, что вместо использования только что описанной аппроксимации, мы используем набор скрытых нейронов для вычисления аппроксимации половины нашей изначальной целевой функции, то есть, ??1?f(x)/2. Конечно, это будет выглядеть, просто как масштабированная версия последнего графика:
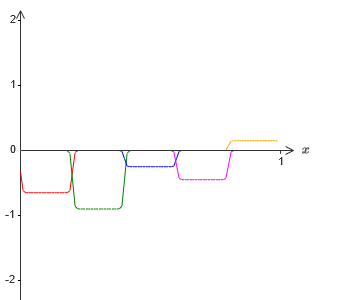
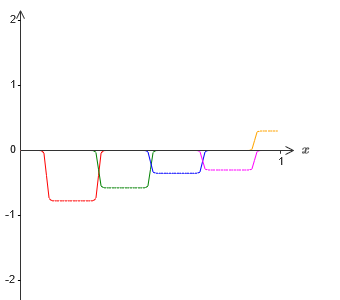
Заключение
Рассмотренное здесь объяснение универсальности определённо нельзя назвать практическим описанием того, как подсчитывать функции при помощи нейросетей! В этом смысле оно больше похоже на доказательство универсальности логических вентилей NAND и прочего. Поэтому я в основном пытался сделать так, чтобы эта конструкция была ясной, и ей было просто следовать, не оптимизируя её детали. Однако попытки оптимизировать эту конструкцию могут стать для вас интересным и поучительным упражнением.
Хотя полученный результат нельзя напрямую использовать для создания НС, он важен, поскольку он снимает вопрос вычислимости какой-либо определённой функции при помощи НС. Ответ на такой вопрос всегда будет положительным. Поэтому правильно спрашивать не вычислима ли какая-либо функция, а каков правильный способ её вычисления.
Разработанная нами универсальная конструкция использует всего два скрытых слоя для вычисления произвольной функции. Как мы обсуждали, возможно получить тот же результат при помощи единственного скрытого слоя. Учитывая это, вы можете задуматься, зачем вообще нам нужны глубокие сети, то есть, сети с большим количеством скрытых слоёв. Не можем ли мы просто заменить эти сети на неглубокие, имеющие один скрытый слой?
Хотя, в принципе, это возможно, существуют хорошие практические причины для использования глубоких нейросетей. Как описано в главе 1, у глубоких НС есть иерархическая структура, позволяющая им хорошо адаптироваться для изучения иерархических знаний, которые оказываются полезными для решения реальных проблем. Более конкретно, при решении таких задач, как распознавание образов, полезно бывает использовать систему, понимающую не только отдельные пиксели, но и всё более сложные концепции: от границ до простых геометрических фигур, и далее, вплоть до сложных сцен с участием нескольких объектов. В более поздних главах мы увидим свидетельства, говорящие в пользу того, что глубокие НС смогут лучше неглубоких справиться с изучением подобных иерархий знания. Подытоживая: универсальность говорит нам, что НС могут подсчитать любую функцию; эмпирические свидетельства говорят о том, что глубокие НС лучше адаптированы к изучениям функций, полезных для решения многих задач реального мира.
Телеграм: t.me/ainewsline
Источник: habr.com