Извлечение данных при машинном обучении
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2019-07-21 04:02

SQL
Если вам нужно получить данные из реляционной базы данных, скорее всего, вы будете работать с языком SQL. Библиотека SQLAlchemy позволит связать ваш код в ноутбуке с наиболее распространенными типами баз данных. По ссылке вы найдете информацию о том, какие базы данных поддерживаются и как осуществить привязку к каждому типу. Вы можете использовать библиотеку SQLAlchemy, чтобы просматривать таблицы и запрашивать данные, или писать необработанные запросы. Для привязки к базе данных понадобится адрес URL с вашими идентификационными данными. Далее нужно инициализировать метод create_engine для создания подключения.
from sqlalchemy import create_engine engine = create_engine('dialect+driver://username:password@host:port/database')Теперь вы можете писать запросы к базе данных и получать результаты.
connection = engine.connect() result = connection.execute("select * from my_table")Скрапинг
Веб-скрапинг используется для загрузки данных с веб-сайтов и извлечения необходимой информации с их страниц. Существует множество библиотек Python, применимых для этого, но самой простой является Beautiful Soup. Вы можете установить пакет через pip.
pip install BeautifulSoup4Давайте на простом примере разберемся, как этим пользоваться. Мы собираемся применить Beautiful Soup и библиотеку urllib, чтобы соскрапить названия отелей и цены на них с веб-сайта TripAdvisor. Сначала импортируем все библиотеки, с которыми собираемся работать.
from bs4 import BeautifulSoup import urllib.requestТеперь загружаем контент страницы, которую будем скрапить. Я хочу собрать данные о ценах на отели на греческом острове Крит и беру адрес URL, содержащий перечень отелей в этом месте.
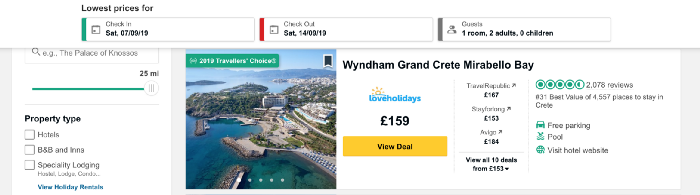
URL = 'https://www.tripadvisor.co.uk/Hotels-g189413-Crete-Hotels.html' page = urllib.request.urlopen(URL) soup = BeautifulSoup(page, 'html.parser') print(soup.prettify())
find_all, которая позволит извлечь части интересующего нас документа. Можно по-разному фильтровать его, используя функцию find_all, чтобы передать одну строку, регулярное выражение или список. Также можно отфильтровать один из атрибутов тега — это как раз тот метод, который мы применим. Если вы не знакомы с тегами и атрибутами языка HTML, обратитесь за кратким обзором к этой статье. Чтобы понять, как наилучшим образом обеспечить доступ к данным в теге, нам нужно проверить код для этого элемента на странице. Находим код к названию отеля, кликая правой кнопкой мыши по названию в списке, как показано на рисунке ниже. 
inspect появится код элемента, а раздел с названием отеля будет выделен цветом.
listing_title. После класса идет код и название этого атрибута к функции find_all, а также тег div.content_name = soup.find_all('div', attrs={'class': 'listing_title'}) print(content_name)Каждый раздел кода с названием отеля возвращается в виде списка.

getText библиотеки Beautiful Soup.content_name_list = [] for div in content_name: content_name_list.append(div.getText().split(' ')[0]) print(content_name_list)Названия отелей возвращаются в виде списка.


content_price = soup.find_all('div', attrs={'class': 'price-wrap'}) print(content_price) В случае с ценой есть небольшая сложность. Ее можно увидеть, запустив следующий код:
content_price_list = [] for div in content_price: content_price_list.append(div.getText().split(' ')[0]) print(content_price_list)Результат продемонстрирован ниже. Если в списке отелей указано уменьшение цены, в дополнение к некоторому тексту возвращается как исходная цена, так и итоговая. Чтобы устранить эту проблему, мы просто возвращаем цену, актуальную на сегодняшний день.

content_price_list = [] for a in content_price: a_split = a.getText().split(' ')[0] if len(a_split) > 5: content_price_list.append(a_split[-4:]) else: content_price_list.append(a_split) print(content_price_list)Это даст нам следующий результат:

API
API — программный интерфейс приложения (от англ. application programming interface). С позиции извлечения данных это веб-система, обеспечивающая конечную точку данных, с которой вы можете связаться посредством программирования. Обычно данные возвращаются в формате JSON или XML.
Этот метод, вероятно, пригодится вам в машинном обучении. Я приведу простой пример извлечения данных о погоде с общедоступного API Dark Sky. Чтобы подключиться к нему, нужно зарегистрироваться, и у вас будет 1000 бесплатных вызовов в день. Этого должно быть достаточно для пробы. Для доступа к данным из Dark Sky я воспользуюсь библиотекой requests. Первым делом мне нужно получить корректный URL для запроса. Помимо прогноза, Dark Sky предоставляет исторические данные о погоде. В этом примере я возьму их, а корректный URL получу из документации. Структура этого URL:
https://api.darksky.net/forecast/[key]/[latitude],[longitude],[time]Мы будем использовать библиотеку
requests, чтобы получить результаты для конкретной широты и долготы, а также дату и время. Представим, что после извлечения ежедневных данных о ценах на отели Крита мы решили выяснить, связана ли ценовая политика с погодой.
Для примера давайте возьмем координаты одного из отелей в списке — Mitsis Laguna Resort & Spa.

requests, получим доступ к данным в формате JSON.import requests request_url = 'https://api.darksky.net/forecast/fd82a22de40c6dca7d1ae392ad83eeb3/35.3378,-25.3741,2019-07-01T12:00:00' result = requests.get(request_url).json() result Чтобы результаты было легче читать и анализировать, мы можем преобразовать данные в датафрейм.
import pandas as pd df = pd.DataFrame.from_dict(json_normalize(result), orient='columns') df.head()
Телеграм: t.me/ainewsline
Источник: habr.com