Искусственный интеллект, читающий научные статьи, выучил химию и предсказал открытия
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2019-07-05 14:55

Искусственный интеллект, в который не было заложено никаких знаний по химии, переоткрыл таблицу Менделеева и подсказал учёным новые перспективные материалы. Для этого он проанализировал 3,3 миллиона аннотаций научных трудов.
Достижение описано в научной статье, опубликованной в журнале Nature группой во главе с Анубхавом Джайном (Anubhav Jain) из Национальной лаборатории имени Лоуренса в Беркли, США.
Сегодня среди учёных ходит грустная шутка, что проще сделать открытие заново, чем найти информацию о нём. По оценкам пятилетней давности, в Интернете было доступно 114 миллионов (!) научных публикаций на английском языке. И каждый день к этому массиву прибавляется множество новых.
Даже в узких областях науки, будь то изучение солнечного ветра или термоэлектрических материалов, количество выходящих статей таково, что исследователь не в состоянии читать их все, даже если он ежедневно с утра до вечера будет заниматься только этим.
Научное сообщество пытается решить эту проблему, создавая более совершенные поисковые системы, базы данных и инструменты автоматического анализа информации. Но на данный момент задача быть в курсе всего, что происходит в твоей области, всё ещё требует от учёного непосильного труда.
Команда Джайна внесла свой вклад в решение этой проблемы, создав систему искусственного интеллекта, основанную на технологии Word2vec.
Этот метод по своей сути чисто лингвистический. Каждое слово представляется в виде набора n чисел (координат). Другими словами, оно становится точкой в n-мерном пространстве.
Компьютер вычисляет, как часто те или иные слова встречаются поблизости друг от друга. На этом основании он присваивает им значения координат. Предполагается, что слова с близкими координатами имеют похожий смысл.
Джайна и коллег интересовало, как этот подход справится с анализом научной литературы по материаловедению. Конкретно их интересовали термоэлектрические материалы, которые превращают разницу температур в электрическое напряжение (или наоборот).
Исследователи "скормили" системе 3,3 миллиона аннотаций научных статей, опубликованных более чем в тысяче журналов в период между 1922 и 2018 годами. Искусственный интеллект выделил в них примерно полмиллиона различных слов. Каждое слово он представил в виде набора из двухсот координат.
Авторы особо подчёркивают, что в программу не было заложено никаких сведений по химии или физике. Все свои "познания" система почерпнула из аннотаций научных статей. Тем более удивительными получились результаты.
Например, исследователи выяснили, какие координаты в 200-мерном пространстве получило название каждого химического элемента. Спроецировав эту картину на плоскость, они получили некое подобие таблицы Менделеева. Элементы оказались сгруппированы по своей природе: отдельно инертные газы, отдельно щелочные металлы, отдельно двухатомные неметаллы и так далее.
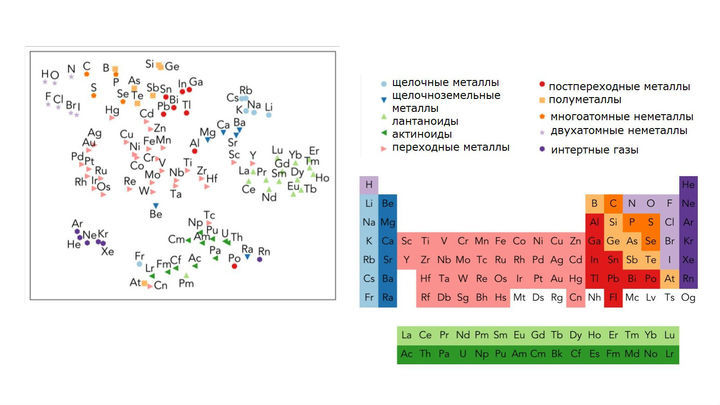
Слева: элементы, сгруппированные искусственным интеллектом. Справа: те же группы в таблице Менделеева.
"Не зная ничего о материаловедении, [программа] изучила такие понятия, как периодическая таблица [Менделеева] и кристаллическая структура металлов", – утверждает Джайн.
Если компьютерный разум так хорошо освоил материаловедение, может ли он выделить среди многочисленных материалов эффективные термоэлектрики? Авторы проверили это, задав поиск названий веществ, по своим координатам максимально близких к слову "термоэлектрик".
Программа сформировала топ-10 материалов. Для каждого из них исследователи рассчитали фактор мощности (power factor), определяющий его эффективность как термоэлектрика.
Оказалось, что у всех отобранных веществ эта величина была выше, чем в средняя по всем известным термоэлектрическим соединениям. У материалов из топ-3 она была больше, чем у 95% известных термоэлектриков.
Но для перспективного термоэлектрика важен не только фактор мощности. Необходимо, чтобы вещество было недорогим, безопасным и простым в производстве. Учитывает ли искусственный интеллект эти особенности? И может ли он предсказать, на какие вещества специалистам следует обратить внимание в будущих исследованиях? Как считают авторы, да.
Например, учёные дали системе то же задание: найти термоэлектрики, но сделали это дважды. В первый раз они предоставили ей публикации, вышедшие до 2008 года, а во второй – до 2018 года.
В первый раз система отобрала топ-5 материалов. Три из них вошли в топ и по публикациям 2018 года, а остальные два содержали редкие или токсичные элементы.
По расчётам исследователей, система угадывала материал, на который специалисты обратят внимание в следующие десять лет, вчетверо чаще, чем если бы она называла их случайно.
"Это исследование показывает, что, если бы этот алгоритм использовался ранее, некоторые материалы могли быть обнаружены на много лет раньше", – говорит Джайн.
Другими словами, информация о перспективных соединениях содержалась в научных статьях, но сообщество не заметило её вовремя.
Вместе с результатами таких "послесказаний" авторы публикуют названия 50 лучших термоэлектриков, на которые исследователям стоит обратить пристальное внимание прямо сейчас. Время покажет, был ли прав искусственный интеллект. Если его выводы подтвердятся, это будет означать, что у учёных действительно появился новый мощный инструмент получения информации.
Также исследователи опубликовали инструкцию для тех, кто хочет воспользоваться теми же алгоритмами при поиске перспективных веществ в других классах материалов.
![]()
Телеграм: t.me/ainewsline
Источник: nauka.vesti.ru