XLNet: новый state-of-the-art в задачах обработки естественного языка
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2019-06-28 14:46

XLNet — это предобученная модель, которую можно адаптировать под любую поставленную задачу обработки текста. XLNet обходит BERT, — state-of-the-art модель, — на 20 задачах обработки естественного языка. Для 18 XLNet установил state-of-the-art результаты. Среди задач — такие, как вопросно-ответная система, анализ сентиментальной окраски, ранжирование документов и т.д.
На задаче моделирования контекстов подходы с предобучением, основанном на автокодирщике, (BERT) зарекомендовали себя лучше, чем те, что основаны на авторегрессивном языковом моделировании. Но у подхода с автокодированием есть ограничения. Одно из них — на входную последовательность слов накладываются маски, что не учитывает различия между замаскированными словами. Архитектура XLNet учитывает достоинства и недостатки BERT и содержит в себе идеи из Transformer-XL.
Ключевые характеристики
XLNet — это обобщенный авторегрессивный метод, который интегрирует в себе частично свойства авторегрессивных языковых моделей и автокодировщиков.
Во-первых, нейросеть не использует фиксированные прямо направленный и обратно направленный порядки факторизации, как в стандартных авторегрессивных моделях. Вместо этого, XLNet максимизирует ожидаемый логарифм вероятности последовательности слов с учетом всех перестановок порядков слов. Благодаря шагу с перестановками, контекст для каждой позиции в последовательности может состоять из слов с правой и левой сторон. Получается, что слово на каждой позиции в последовательности учится использовать контекстную информацию со всех остальных позиций (bidirectional context).
Во-вторых, как и в авторегрессивной модели, XLNet не маскирует слова в последовательности. Из-за этого модель не страдает от проблемы несоответствия модели на предобучении и на тюнинге для отдельной задачи. Эта проблема свойственна BERT.
В-третьих, в XLNet используется новая целевая функция. В XLNet частично используются идеи из недавно опубликованной языковой модели Transformer-XL.
XLNet в экспериментах
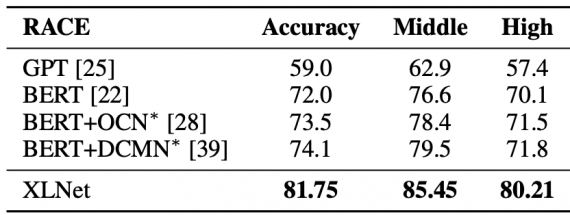
Исследователи сравнили работу модели с state-of-the-art подходами на 20 задачах обработки естественного языка. Одна из них — RACE. Ниже представлены результаты моделей на двух сабсетах данных (Middle и High). BERT и XLNet модели обе имели 24 слоя и были схожего размера. Для всех экспериментов использовался BERT-Large, — самая полная версия модели. XLNet в одиночку улучшает результаты лучшего ансамбля моделей на 7.6 пунктов в точности.
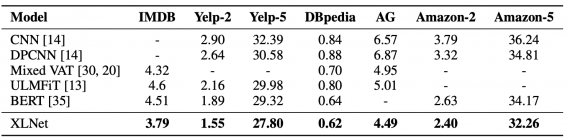
Исследователи сравнили модели на нескольких датасетах по текстовой классификации. XLNet все еще получил лучшие результаты в сравнении с остальными моделями.
Телеграм: t.me/ainewsline
Источник: neurohive.io