Нейросеть от Samsung научила Распутина петь голосом Beyonce
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2019-06-22 15:00

Исследователи из Центра ИИ компании Samsung в Кембридже и Имперского колледжа в Лондоне создали end-to-end генеративно-состязательную сеть (GAN), которая анимирует и синхронизирует движения лица на 2D-изображении с аудиозаписью, содержащей голос. Благодаря этому создается впечатление, что голос с аудиоклипа принадлежит лицу на изображении.
Модель синхронизирует движения губ, движение бровей, а также делает синтезирует мигание глаз, чтобы сделать изображения более естественными. Синхронизация губ со звуком сегодня часто реализуется путем пост-редактирования или с использованием компьютерной графики.
Исследователи полагают, что модель может быть использована для автоматического создания говорящих голов персонажей в анимационных фильмах, заполнения пробелов при пропусках видеокадров во время видеозвонков с низкой пропускной способностью или для обеспечения лучшей синхронизации губ или дублирования фильмов на иностранных языках. Технология также может быть использована для других манипуляций с поддельными персонами.
В примерах, которыми поделились исследователи на YouTube: мертвый русский мистик Распутин, поющий песню Beyonce «Halo», рэперы 2Pac и Biggie, исполняющие свои работы, и Альберт Эйнштейн, цитирующий цитату об общем языке науки. Дополнительные примеры и документ с описанием модели можно найти на этом сайте. Код модели опубликован на github, и вы можете самостоятельно проверить ее работу.
Эта новость появилась через месяц после того, как центр ИИ компании Samsung в Москве представил AI для анимации 2D-изображений без 3D-моделирования. Это технология, которая может быть использована для создания более правдоподобных цифровых аватаров или глубоких подделок.
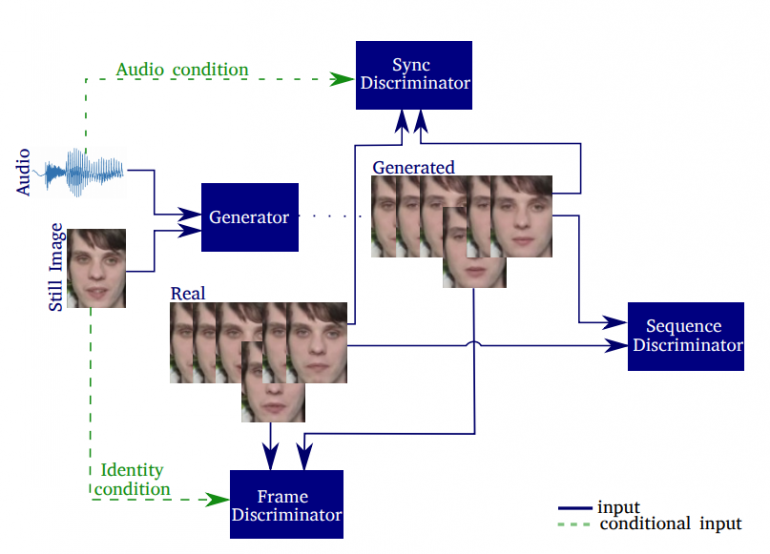
Модель использует 3 дискриминатора, ориентированных на детализацию кадров (frame discriminator), синхронизациию изображения с аудиозаписью (synchronization discriminator) и реалистичности выражений лица (sequence discriminator). Выполняется оценка вклада каждого компонента в модель. Сгенерированные видео оцениваются на основе резкости, качества реконструкции, точности считывания по губам, синхронизации, а также их способности генерировать естественные моргания.
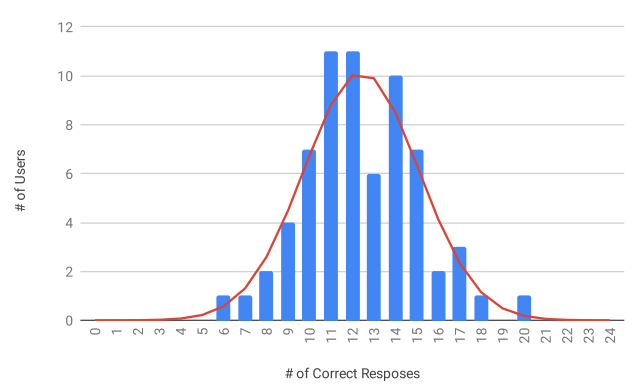
На сайте модели также можно найти Тьюринг-тест для проверки вашей способности отличать реальные видео от сгенерированных. Из распределения результатов этого теста, опубликованного исследователями, можно увидеть, что большая часть людей верно определяет истинность видео только у половины предлагаемых видеозаписей. Также, практически никто оказывается не способен верно определить все или почти все видеозаписи.
Телеграм: t.me/ainewsline
Источник: neurohive.io