Статьи про компьютерное зрение, интерпретируемость, NLP – мы побывали на конференции AISTATS в Японии и хотим поделиться обзором статей. Это крупная конференция по статистике и машинному обучению, и в этом году она проходит на Окинаве – острове недалеко от Тайваня. В этом посте Юлия Антохина (Yulia_chan) подготовила описание ярких статей из основной секции, в следующем вместе с Анной Папета расскажет про доклады приглашенных лекторов и теоретические исследования. Немного расскажем и про то, как проходила сама конференция и про “неяпонскую” Японию.
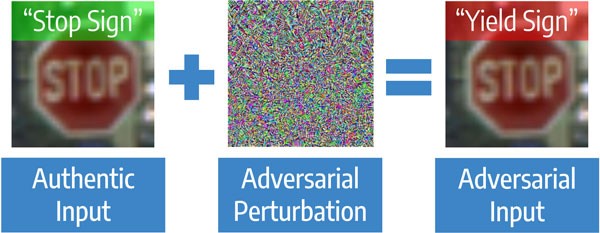
Defending against Whitebox Adversarial Attacks via Randomized Discretization Yuchen Zhang (Microsoft); Percy Liang (Stanford University) ? Статья ? Код Начнем со статьи про защиту от состязательных атак (adversarial attacks) в компьютерном зрении. Это целенаправленные атаки на модели, когда цель атаки – заставить модель ошибиться, вплоть до заранее заданного результата. Алгоритмы компьютерного зрения могут ошибаться даже при несущественных для человека изменениях исходной картинки. Задача актуальна, например, для машинного зрения, которое в хороших условиях распознает дорожные знаки быстрее человека, но при атаках работает гораздо хуже.
Adversarial Attack наглядно
Атаки есть Blackbox – когда атакующему неизвестно ничего про алгоритм, и Whitebox –обратная ситуация. Для защиты моделей есть два основных подхода. Первый подход – натренировать модель на обычных и на “атакованных” картинках – она называется adversarial training. Этот подход хорошо работает на небольших картинках вроде MNIST, но есть статьи, где показано, что он плохо работает на крупных картинках, вроде ImageNet. Второй вид защиты не требует переобучения модели. Достаточно только предобработать картинку перед подачей в модель. Примеры преобразований: JPEG сжатие, изменение размера. Эти методы требуют меньше вычислений, но сейчас работают только против Blackbox атак, так как если преобразование известно, можно применить обратное. Метод
В статье авторы предлагают метод, не требующий перетренировки модели и работающий для Whitebox атак. Цель – уменьшить расстояние Кульбака — Лейбнера между обычными примерами и “испорченными” с помощью случайного преобразования. Оказывается, достаточно добавить случайный шум, а затем случайным образом дискретизировать цвета. То есть на вход алгоритму подается “ухудшенного” качества изображение, но все же достаточного чтобы алгоритм работал. А за счет случайности есть потенциал противостоять Whitebox атакам.
Слева – оригинальная картинка, посередине – пример кластеризации цветов пикселей в Lab пространстве, справа – картинка в нескольких цветах (Например, вместо 40 оттенков голубого — один)
Результаты
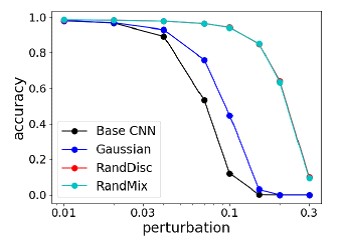
Этот метод сравнивался с самыми сильными атаками на с NIPS 2017 Adversarial Attacks & Defenses Competition, и он показывает в среднем лучшее качество и не переобучается под “атакующего”.
Сравнение самых сильных методов защиты против самых сильных атак на NIPS Competition
Сравнение точности методов на MNIST при разных изменениях изображения
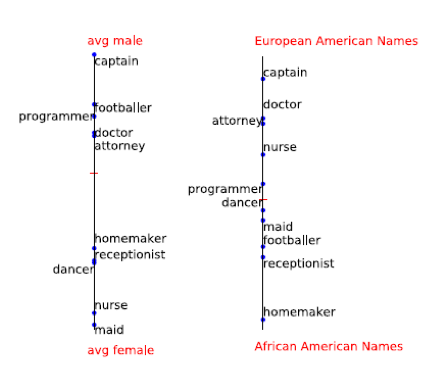
Attenuating Bias in Word vectors Sunipa Dev (University of Utah); Jeff Phillips (University of Utah) ? Статья «Модный» доклад был про Unbiased Word Vectors. В данном случае под Bias имеются ввиду смещения по полу или национальности в представлениях слов. Против такой «дискриминации» могут выступить какие-либо регуляторы, и поэтому ученые из университета Юты решили изучить возможности «уравнивания в правах» для NLP. В самом деле, почему мужчина не может быть «гламурным», а женщина «Data Scientistом»?
Original – результат, который получается сейчас, остальное – результаты работы unbiased алгоритма
В статье рассматривается способ нахождения такого смещения. Они решили, что пол и национальность хорошо характеризуются именами. А значит, если найти смещение по именам и вычесть его, то так, наверное, можно избавиться от предвзятости алгоритма. Пример более «мужских» и «женских» слов:
Имена для поиска смещения по полу:
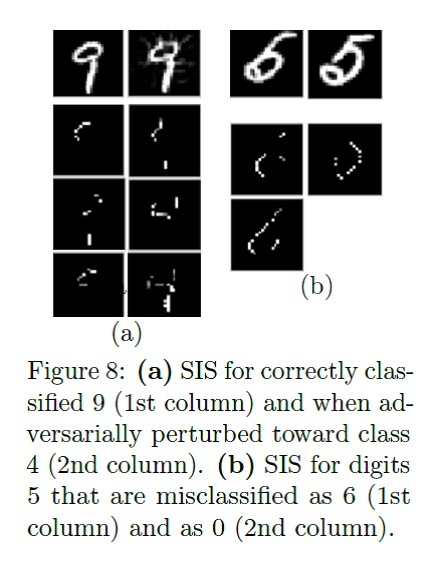
Как ни странно, такой простой метод работает. Авторы обучили несмещенный относительно пола Glove и выложили в Git. What made you do this? Understanding black-box decisions with sufficient input subsets Brandon Carter (MIT CSAIL); Jonas Mueller (Amazon Web Services); Siddhartha Jain (MIT CSAIL); David Gifford (MIT CSAIL) ? Статья ? Код раз и два Следующая статья рассказывает про алгоритм Sufficient Input Subset. SIS — это минимальные подмножества фичей, при которых модель выдаст определенный результат, даже если все остальные фичи обнулить. Это еще один способ как-то интерпретировать результаты сложных моделей. Работает и на текстах, и на картинках.
Алгоритм поиска SIS подробно:
Пример применения на тексте с отзывами про пиво:
Пример применения на MNIST:
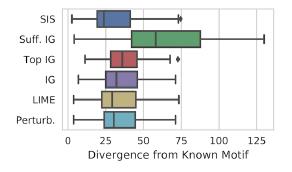
Сравнение методов «интерпретирования» по расстоянию Кульбака – Лейблера относительно «идеального» результата:
Фичи сначала ранжируются по влиянию на модель, а затем разбиваются на непересекающиеся подмножества, начиная с самых влиятельных. Работает перебором, и на размеченном датасете результат интерпретирует лучше LIME. Есть удобная реализация поиска SIS от Google Research.
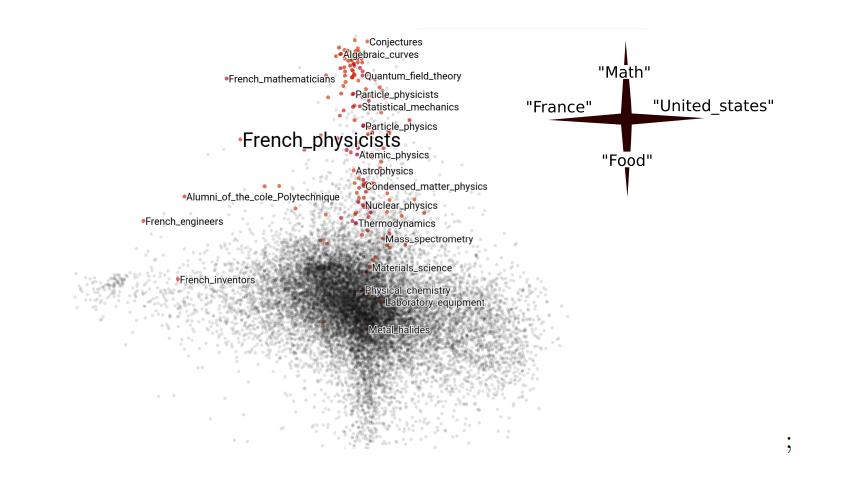
Empirical Risk Minimization and Stochastic Gradient Descent for Relational Data Victor Veitch (Columbia University); Morgane Austern (Columbia University); Wenda Zhou (Columbia University); David Blei (Columbia University); Peter Orbanz (Columbia University) ? Статья ? Код В секции по оптимизации был доклад по Empirical Risk Minimization, где авторы исследовали способы применения стохастического градиентного спуска на графах. Например, при построении модели на данных соцсети можно использовать только фиксированные фичи профиля (количество подписчиков), но тогда теряется информация о связях между профилями (кто на кого подписан). При этом весь граф чаще всего сложно обрабатывать – например, он не помещается в память. Когда такая ситуация возникает на табличных данных, модель можно запустить на подвыборках. А как правильно выбрать аналог подвыборки на графе не было понятно. Авторы теоретически обосновали возможность использовать случайные подграфы как аналог подвыборок, и это оказалось «Not crazy idea». На Github есть воспроизводимые примеры из статьи, в том числе и пример с «Википедией».
Category Embeddings на данных «Википедии» с учетов ее графовой структуры, выделенные статьи наиболее близки по теме к «Французским физикам»:
? Data Science for Networked Data Про графы на дискретных данных был еще один обзорный доклад Data Science for Networked Data от приглашенного спикера Poling Loh (University of Wisconsin-Madison). В презентации рассматривались темы Statistical inference, Resource allocation, Local algorithms. В Statistical inference, например, речь шла о том, как понять, какую структуру имеет граф по данным о инфекционных заболеваниях. Предлагается использовать статистику количество связей между инфицированными узлами – и доказана теорема для соответствующего статистического теста. Вообще доклад интереснее смотреть, скорее всего, тем, кто не занимается графовыми моделями, но хотел бы попробовать и интересуется, как правильно проверять гипотезы для графов.
Как проходила сама конференция
AISTATS 2019 — это трехдневная конференция на Окинаве. Это Япония, но по культуре Окинава ближе к Китаю. Главная торговая улица напоминает крошечный такой Майями, на улицах длинные машины, кантри–музыка, а отойдешь немного в сторону – джунгли со змеями, вывороченные тайфунами мангровые деревья. Местный колорит создает культура Рюкю – королевства, которое находилось на Окинаве, но сначала стало вассалом и торговым партнером Китая, а затем было захвачено японцами.
А еще на Окинаве, видимо, часто проводят свадьбы, потому что очень много свадебных салонов, да и конференция проходила в помещении Wedding Hall.
Ученых, авторов статей, слушателей и спикеров собралось больше 500 человек. За три дня можно успеть поговорить почти со всеми. Хотя конференция проходила «на краю света» — приехали представители со всего мира. Несмотря на широкую географию, оказалось, что интересы у всех нас схожие. Для нас стало неожиданностью, к примеру, что ученые из Австралии решают такие же Data Science-задачи и теми же методами, как и мы в нашей команде. А, ведь, почти на противоположных сторонах планеты живем… «Из индустрии» участников было не так много: Google, Amazon, МТС и еще несколько топовых компаний.
Были представители японских компаний–спонсоров, которые в основном смотрели и слушали и, вероятно, кого-то хантили, несмотря на то, что «неяпонцам» работать в Японии очень непросто.
Статьи, заявленные на конференцию по темам:
Обо всем остальном — в нашем следующем посте. Не пропустите! Анонс:

 Результаты
Результаты




 Фичи сначала ранжируются по влиянию на модель, а затем разбиваются на непересекающиеся подмножества, начиная с самых влиятельных. Работает перебором, и на размеченном датасете результат интерпретирует лучше LIME. Есть удобная реализация поиска SIS от Google Research.
Фичи сначала ранжируются по влиянию на модель, а затем разбиваются на непересекающиеся подмножества, начиная с самых влиятельных. Работает перебором, и на размеченном датасете результат интерпретирует лучше LIME. Есть удобная реализация поиска SIS от Google Research.