Выборка случайных чисел на основе функций распределения вероятностей
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2019-05-28 09:13

В этой серии статей мы обсудим моделирование пучков ионов или электронов с помощью методов трассировки частиц. Начнем мы с короткой справки о функциях распределения вероятностей и о разных способах выборки случайных чисел на их основе в программном пакете COMSOL Multiphysics®. В последующих заметках мы покажем, как этот функционал используется для точного моделирования распространения ионных или электронных пучков в реальных системах.
Актуальность использования функций распределения вероятностей
Энергетические пучки ионов и электронов важны для фундаментальных исследований в области высоких энергий и ядерной физики. Используются они и в разных прикладных задачах: в катодно-лучевых трубках, при производстве медицинских изотопов и для нейтрализации ядерных отходов. Для построения точной вычислительной модели распространения пучка особенно важны исходные значения положений частиц и компонент скорости.
Для запуска пучка ионов или электронов при проведении трассировки частиц часто требуется сделать выборку этих частиц в виде дискретных точек в т.н. фазовом пространстве. Однако перед тем, как разбираться в концепции фазового пространства и ее связи с пучками ионов и электронов, давайте поговорим о функциях распределения вероятностей и методах работы с ними в COMSOL Multiphysics.
Справка о функциях распределения вероятностей
Начнем с некоторых определений. Непрерывная случайная переменная x — это рандомно определяемая переменная, которая может принимать бесконечное множество значений. Например, предположим, что точка x1 выбрана случайно на отрезке длины L. Затем точка x2 выбирается в другом месте на этом отрезке. Если эти две точки не совпадают, можно выбрать третью точку , которая находится на том же отрезке, потом четвертую —
и так далее, таким образом получив бесконечное число несовпадающих точек. См. скриншот ниже.
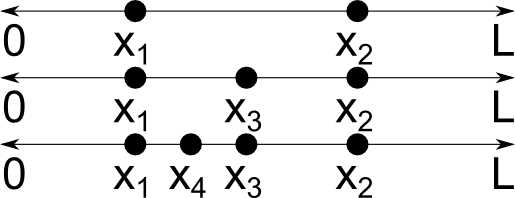
Кстати, другой тип рандомной переменной — дискретная случайная переменная, которая может принимать только конкретные значения. Представьте себе, что вы подбрасываете монетку или вытягиваете карту из колоды: количество результатов конечно.
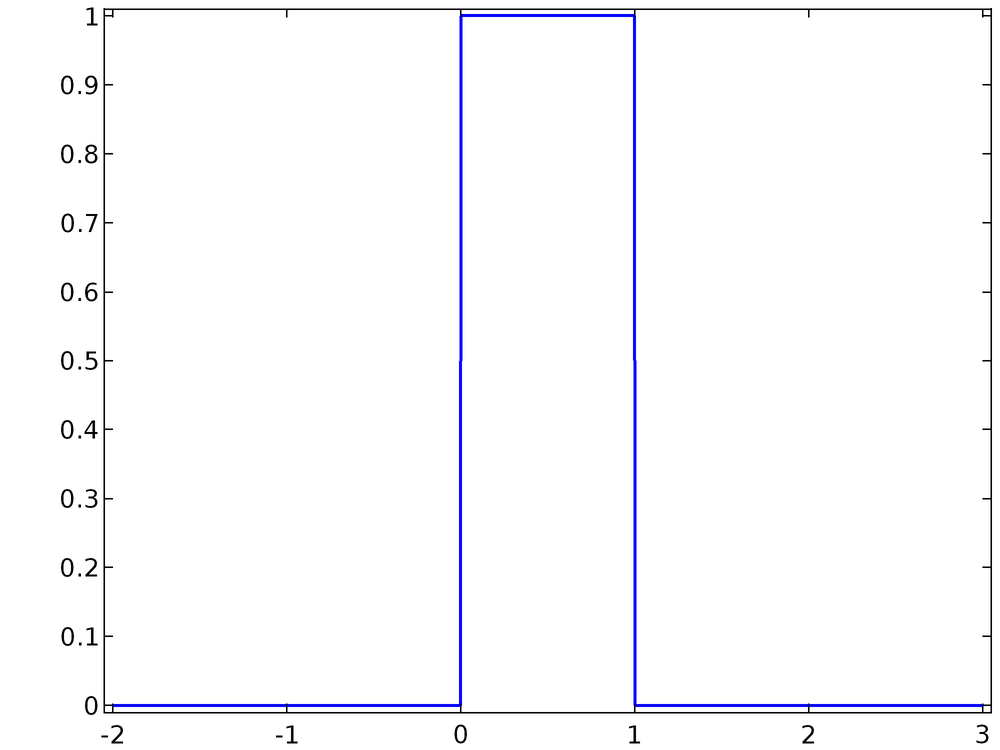
Одномерная функция распределения вероятностей (probability distribution function — PDF) или плотность распределения вероятностей f(x) описывает вероятность того, что непрерывная случайная переменная примет определенное значение. Например, функция распределения вероятностей вида
(1)
описывает переменную x, которая может с равномерной вероятностью принять любое из значений открытого интервала(0; 1), но не может принять какое-либо иное значение. Эта функция распределения вероятностей, в данном случае описывающая равномерное распределение, показана на графике ниже.
Функции распределения вероятностей могут также применяться в контексте дискретных случайных переменных и даже тех переменных, которые непрерывны в одних интервалах и дискретны в других. Как один из вариантов реализации последней из указанных ситуаций, такую случайную переменную можно рассматривать как непрерывную, уточнив, что функция распределения вероятностей включает в себя одну или несколько дельта-функций Дирака. В этой серии статей мы будем рассматривать только непрерывные случайные переменные.
Функция распределения вероятностей считается нормированной, если
Другими словами, суммарная вероятность того, что x примет значение из интервала (-?; ?), равна единице.
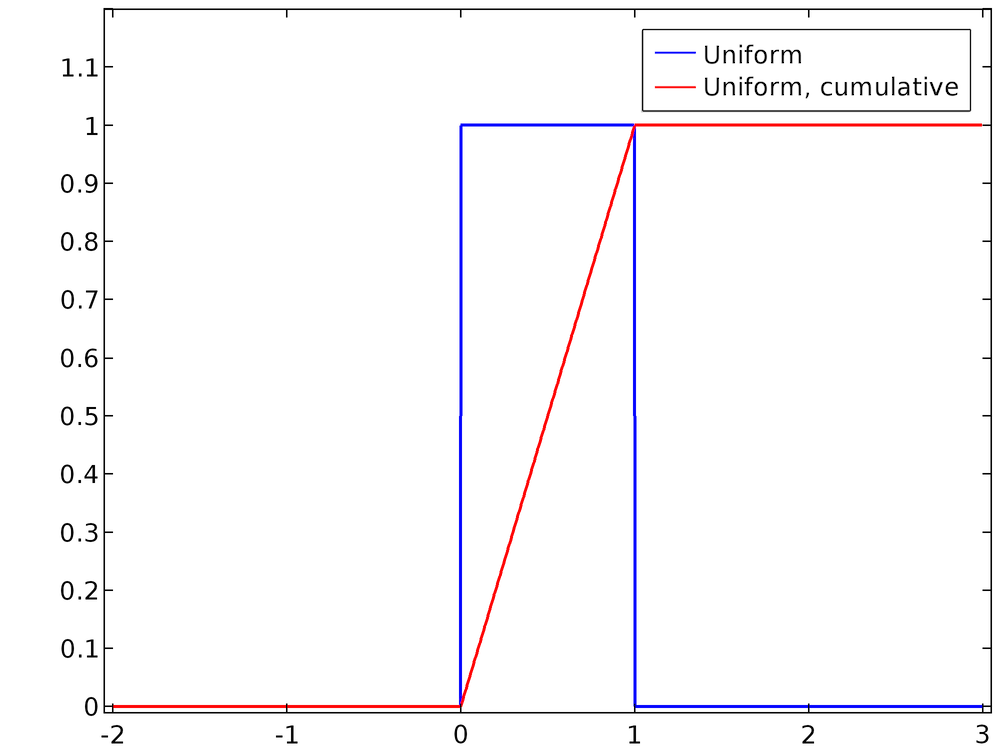
Интегральная или кумулятивная функция распределения F(x) (cumulative distribution function — CDF) представляет собой вероятность того, что значение непрерывной случайной переменной окажется в интервале (-?; x). Функция распределения вероятностей и интегральная функция распределения связаны соотношением
Из определения выше следует тот факт, что если функция распределения вероятностей является нормированной, то
Функция распределения вероятностей из уравнения (1) и соответствующая интегральная функция распределения показаны на графике ниже. Функция распределения вероятностей, записанная таким образом, является нормированной.
Выборка из одномерного распределения
Выбор случайного значения из равномерного распределения обычно довольно прост. В большинстве языков программирования уже имеются готовые процедуры для генерации равномерно распределенных случайных чисел. Однако предположим, что мы имеем гораздо более произвольное распределение, как, например, показанное ниже.
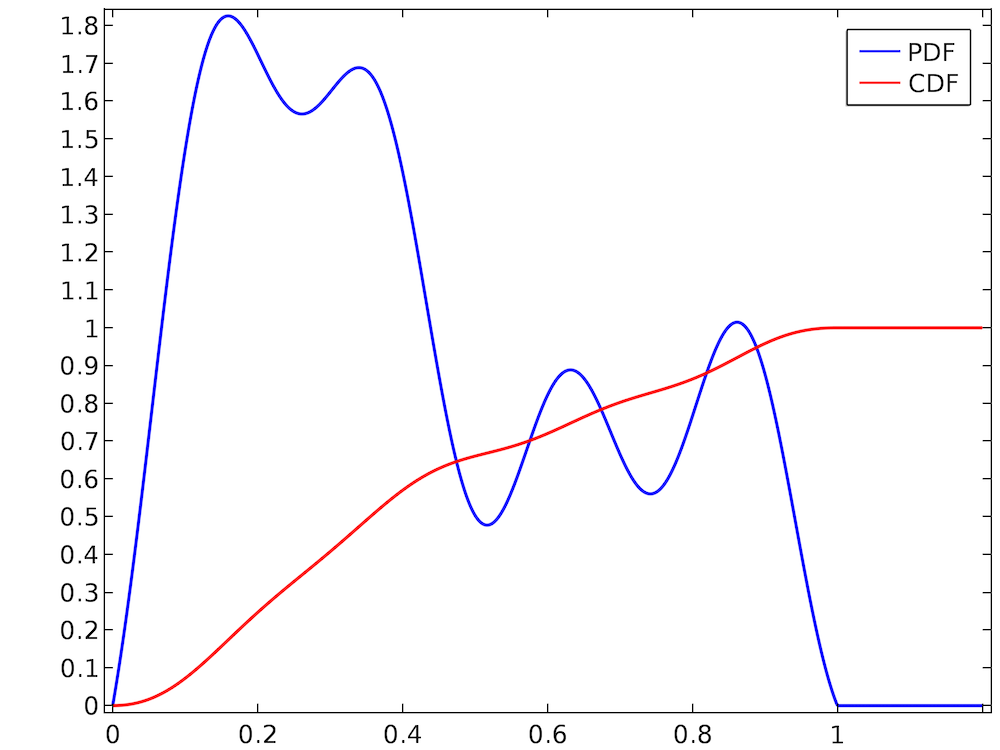
Случайная переменная принимает значения в интервале (0; 1), и функция распределения вероятностей является нормированной, потому что значение интегральной функции распределения на правом конце интервала равно 1. Однако распределение очевидно не является равномерным: к примеру, намного вероятнее, что случайное число попадет в интервал (0,2; 0,3), чем в интервал (0,7; 0,8). Использовать в такой ситуации встроенную процедуру для выборки равномерно распределенных случайных чисел из интервала (0; 1) было бы некорректно. Поэтому нам нужны альтернативные способы выборки случайных чисел из этой произвольно выглядящей функции распределения вероятностей.
Это приводит нас к одной из фундаментальных методик выборки (сэмплирования) значений из функции распределения вероятностей — выборки через обратное преобразование (inverse transform sampling). Пусть U — равномерно распределенное случайное число от нуля до единицы. (Другими словами, U соответствует функции распределения, заданной уравнением (1).) Тогда для выборки случайного числа с (возможно, неравномерной) функцией распределения вероятностей f(x) выполним следующее:
- Нормируем функцию f(x), если она еще не нормирована.
- Берем интеграл нормированной функции распределения вероятностей f(x), чтобы вычислить интегральную функцию распределения F(x).
- Рассчитываем обратную функцию для F(x). Итоговая функция представляет собой обратную интегральную функцию распределения, или квантильную функцию F-1(x). Поскольку мы уже нормировали f(x), для ясности мы назовем ее обратной нормальной интегральной функцией распределения.
- Подставляем значение равномерно распределенного случайного числа U в обратную нормальную интегральную функцию распределения.
Если подвести итог, F-1(U) является случайным числом с функцией распределения вероятностей f(x), если число . Рассмотрим пример, в котором данный метод используется для выборки из неравномерной функции распределения вероятностей.
Пример 1. Распределение Рэлея
Распределение Рэлея довольно часто фигурирует в уравнениях динамики разреженного газа и физики пучков. Оно описывается как
(2)
где ? — масштабный коэффициент, который предварительно задается (на входе задачи). Мы можем проверить, действительно ли распределение Рэлея, записанное в таком виде, является нормированным:
Интегральная функция распределения —
Для ? = 1 нормированное распределение Рэлея и его интегральная функция распределения показаны на графике ниже. Очевидно, что для высоких значений x интегральная функция распределения приближается к единице.
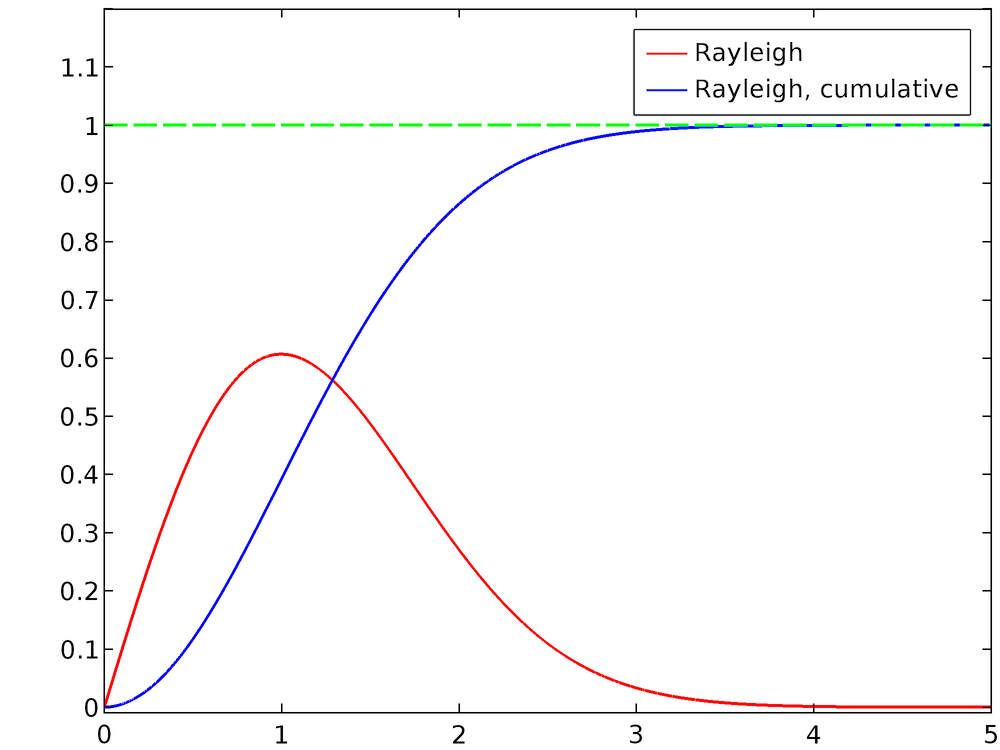
Чтобы вычислить обратную нормальную интегральную функцию распределения, зададим y = F(x) и найдем x:
Теперь подставим равномерно распределенное случайное число U вместо переменной y,
Поскольку U равномерно распределено на интервале (0; 1) и его значение еще не определено, можно далее упростить это выражение, зная, что U и 1 – U следуют одной и тоже функции распределения вероятностей. Таким образом, мы приходим к финальному выражению для значения x из выборки,
(3)
В последующем мы обсудим, как уравнение (3) можно использовать в модели COMSOL для выборки значений из распределения Рэлея.
Учтите, что обратную нормальную интегральную функцию распределения не всегда возможно рассчитать аналитически. Аналитическое решение в замкнутой форме для интеграла любой функции не всегда существует, и не всегда возможно записать выражения для обратной интегральной функции распределения. Распределение Рэлея было использовано здесь не "случайно", поскольку его обратную интегральную функцию распределения можно вывести, не прибегая к численным или приближенным техникам.
Выборка случайных чисел в COMSOL Multiphysics®
Результаты приведенного выше анализа можно использовать в COMSOL Multiphysics для выборки из произвольного одномерного распределения, например распределения Рэлея. Для начала давайте рассмотрим встроенные в пакет инструменты для выборки из распределений особых типов.
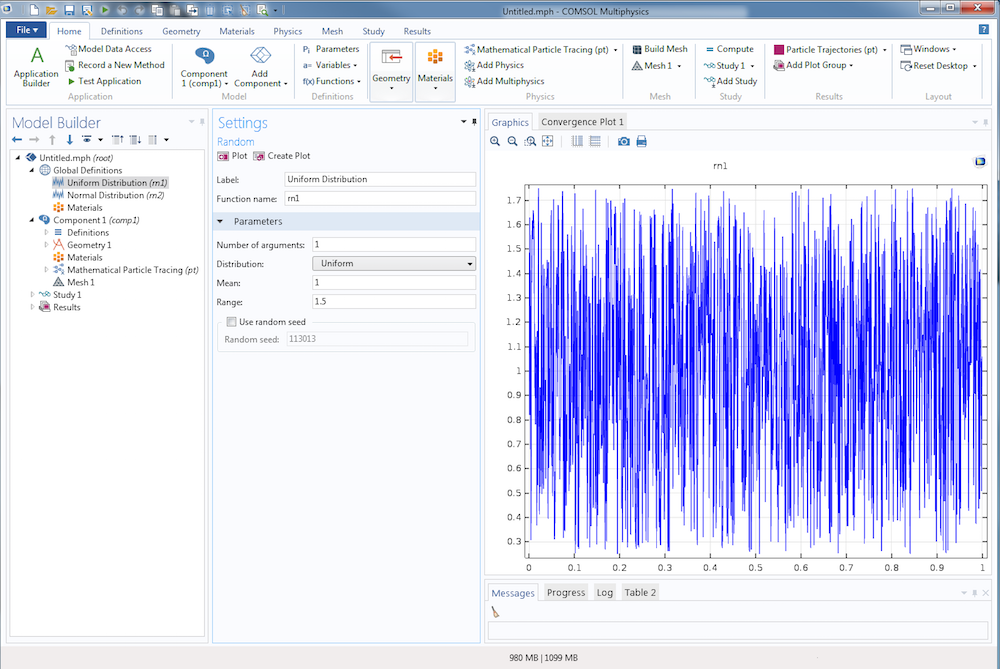
В COMSOL Multiphysics доступно несколько способов задать псевдослучайные числа (о значении термина «псевдослучайный» мы поговорим позже). Задать псевдослучайное число с равномерным или нормальным распределением можно с помощью функции Random (Случайная величина), доступной в узлах Global Definitions (Глобальные определения) и Definitions (Определения). Если используется распределение Uniform (Равномерное), укажите значения параметров Mean (Среднее значение) и Range (Диапазон). Для среднего значения ?u и диапазона ?u функция распределения вероятностей выглядит так:
Пример равномерного распределения со средним значением 1 и диапазоном 1.5 показан ниже.
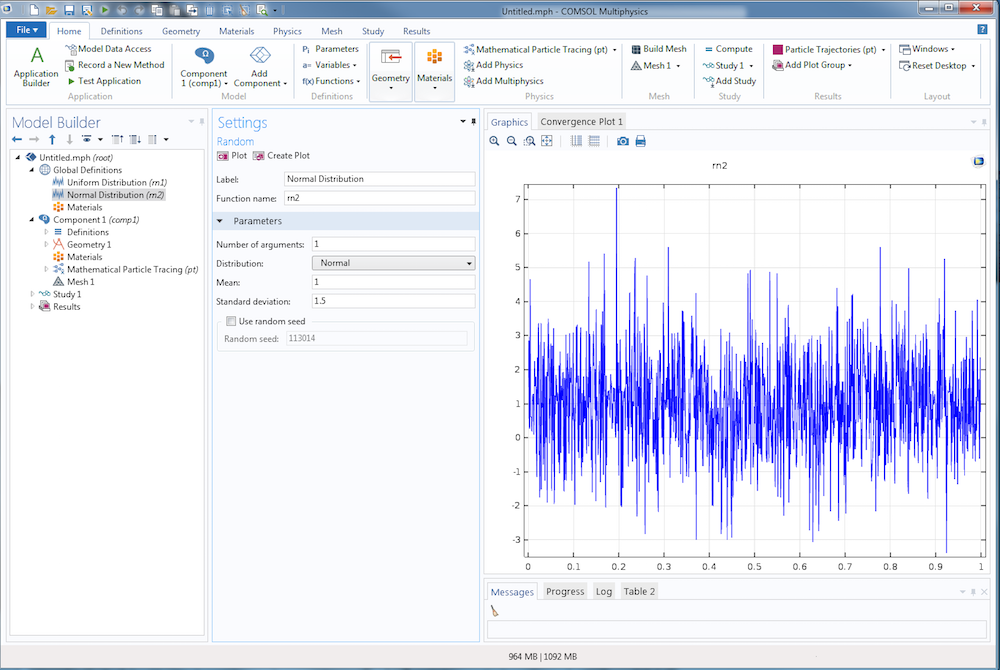
Если используется распределение Normal (Нормальное), или распределение Гаусса, укажите значения параметров Mean (Среднее значение) и Standard Deviation (Среднеквадратичное отклонение). Для среднего значения ?n и среднеквадратичного отклонения ?n функция распределения вероятностей выглядит так:
Пример равномерного распределения со средним значением 1 и среднеквадратичным отклонением 1,5 показан ниже. Как и в случае с равномерным распределением, кривая рваная и непредсказуемая. В отличие от равномерного распределения, точки на кривой расположены очень плотно вблизи прямой y = 1, от которой их плотность идет на спад.
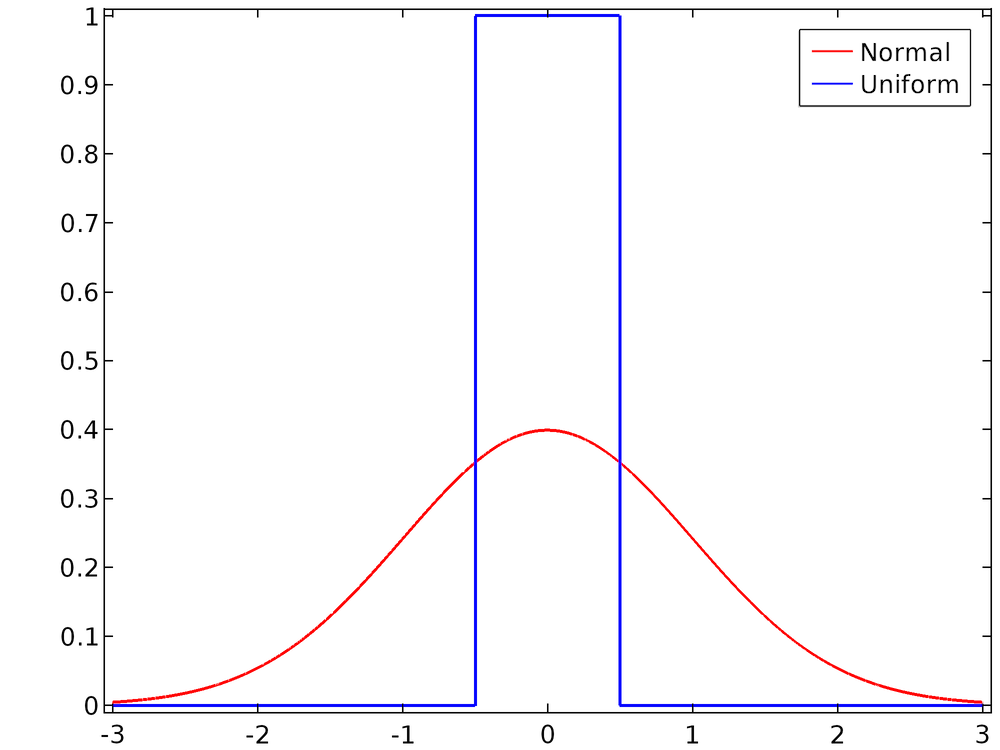
Ниже приведено сравнение двух распределений при стандартных настройках, когда среднее значение равно 0, а диапазон или среднеквадратичное отклонение равны 1.
Как альтернативу использования функции Random можно использовать также встроенные операторы random и randomnormal в любом выражении. В операторе random реализовано равномерное распределение со средним значением 0 и диапазоном 1; в randomnormal — нормальное распределение со средним значением 0 и среднеквадратичным отклонением 1.
Учитывая, что для уравнения (3) нам требуется число U, равномерно выбранное из интервала (0; 1), нам доступны две опции:
- Использование функции Random со средним значением 0,5 и диапазоном 1.
- Использование встроенного оператора
randomс добавлением постоянной величины 0,5.
В следующем примере мы допустим, что используется второй подход.
Случайные, псевдослучайные и начальные числа
Как уже упоминалось, вышеупомянутые методики используются для генерации псевдослучайных чисел. «Псевдослучайное» число — это случайное число, однозначно сгенерированное из исходного значения, или начального числа (seed). Для встроенного оператора random в качестве начального числа используется значение его аргумента (или аргументов). Для сравнения, истинно случайные числа не могут быть сгенерированы одной только программой и требуют некоторого источника энтропии — естественного процесса, по существу непредсказуемого и неповторимого, например, радиоактивного распада или атмосферного шума.
Работать с псевдослучайными числами удобнее, чем с истинно случайными, по нескольким причинам. Их воспроизводимость может быть полезна при поиске проблем в моделях Монте-Карло, поскольку можно получить одинаковый результат, выполнив моделирование несколько раз с одним и тем же начальным числом, упростив при этом обнаружение изменений в других областях модели. Поскольку для псевдослучайных чисел не требуется источника естественной энтропии, которая может иметь лишь конечную величину в той или иной среде и длиться конечный период времени, псевдослучайные числа менее вероятно приведут к увеличению требуемого времени моделирования, в отличие от истинно случайных чисел.
Несмотря на удобство использования псевдослучайных чисел, следует всегда держать в уме и учитывать некоторые особенности их использования. Результирующее псевдослучайное число будет отличаться для разных значений начального числа, хотя одно и то же начальное число даст при повторении одинаковое значение. Чтобы увидеть этой в любой модели COMSOL, создайте узел Global Evaluation (Расчет глобальных выражений) и несколько раз проведите расчет встроенной функции random с постоянным начальным числом, скажем random(1). Результат не покажет очевидной связи с числом 1 (в этой связи число будет выглядеть случайным), однако значение останется без изменений после нескольких повторных расчетов (и поэтому распределение значений уже не покажется случайным). См. скриншот ниже.
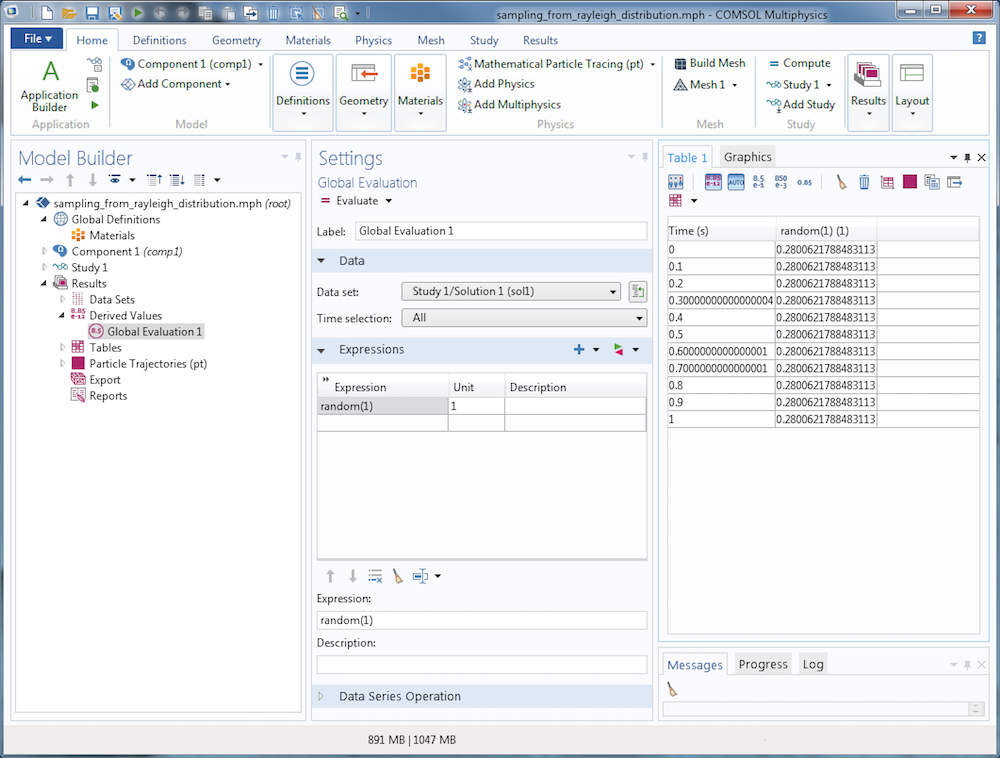
Если при каждом вычислении случайного числа будет использоваться иное начальное число, результаты каждый раз будут разными. Просмотрите и сопоставьте с предыдущей таблицу на следующем скриншоте, в которой используется в качестве входного аргумента для случайной функции переменная времени.
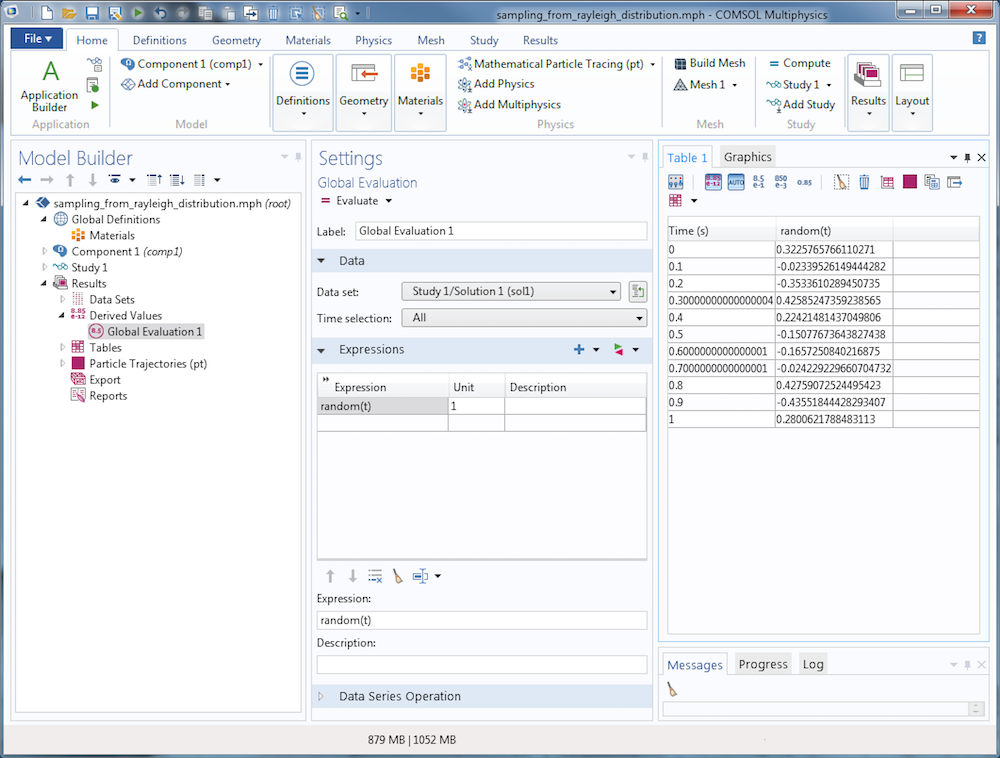
Расчеты с использованием техник Монте-Карло для систем частиц, как правило, включают в себя большие группы частиц, испускаемых со случайными исходными условиями и подвергающихся воздействию случайных сил. Вот несколько примеров случайных явлений, связанных с группами частиц:
- При излучении ионных и электронных пучков, для исходного положения каждой частицы в фазовом пространстве выполняется выборка на основе распределения, которая и является главной темой следующей статьи в этой серии
- Нейтрализация ионов в разреженном фоновом газе в следствие случайных столкновений, сопровождающихся обменом заряда
- Турбулентная дисперсия частиц в потоках текучей среды с высоким критерием Рейнольдса
- Моделирование диффузии частиц при броуновском движении
Очевидно, что если для каждой частицы будут использоваться одинаковые псевдослучайные числа, то такое моделирование будет некорректно отражать реальную физику процесса. Например в случае взаимодействия ионов с фоновым газом, каждая частица будет сталкиваться с молекулами или атомами газа в точности столько же раз, сколько и все другие. Чтобы исправить это, любым случайным числам, используемым в моделировании трассировки частиц, следует назначить начальные числа, уникальные для каждой их них.
Один из вариантов реализации такого подхода является использование при выборе начального числа индекса частицы, который уникален для каждой частицы. Переменная индекса частицы выглядит как <scope>.pidx, где <scope> представляет собой уникальный идентификатор для экземпляра физического интерфейса. Для интерфейса Mathematical Particle Tracing (Математическая трассировка частиц) индекс частицы обычно записывается как pt.pidx. Функция вида random(pt.pidx) присвоит всем частицам разные псевдослучайные числа.
Еще одна сложность связана с тем, что на частицы воздействуют случайные силы на протяжении всего их существования. Например, если для определения случайного столкновения с молекулой газа используется случайное число, это же случайное число не следует использовать для данной частицы в каждый момент времени — ведь тогда частица будет сталкиваться с молекулой на каждом временном шаге или не будет сталкиваться с ней вовсе! Для решения этой проблемы можно задать случайное начальное число, в котором используется несколько аргументов: хотя бы один аргумент, отличающийся для каждой частицы, и один, отличающийся на разных временных шагах моделирования. Если для моделирования необходима выборка нескольких псевдослучайных чисел, независимых друг от друга, могут потребоваться дополнительные аргументы. В этом случае типовая случайная функция может выглядеть так: random(pt.pidx,t,1), где заключительный аргумент 1 можно заменить другими численными значениями, если требуются дополнительные псевдослучайные числа.
Результаты: распределение Рэлея
Давайте вернемся к исходной задаче выборки/сэмплирования из распределения Рэлея. Предположим, что имеется совокупность частиц и требуется выбрать одно число для каждой частицы так, чтобы результирующие значения соответствовали распределению Рэлея. В этом примере мы будем использовать уравнение (2) с ? = 3. В модели COMSOL определим следующие переменные:
| Имя переменной | Выражение | Описание |
|---|---|---|
rn | 0.5+random(pt.pidx) | Случайный аргумент |
sigma | 3 | Масштабирующий параметр |
val | sigma*sqrt(-2*log(rn)) | Значение, сэмплированное из распределения Рэлея |
Обратите внимание на то, что последняя строка — не что иное, как уравнение (3). Следующий график представляет собой гистограмму значения rn для совокупности 1000 частиц. Плавная кривая — это точное распределение Рэлея, определенное с помощью отдельного задания и построения аналитической функции (опция Analytic).
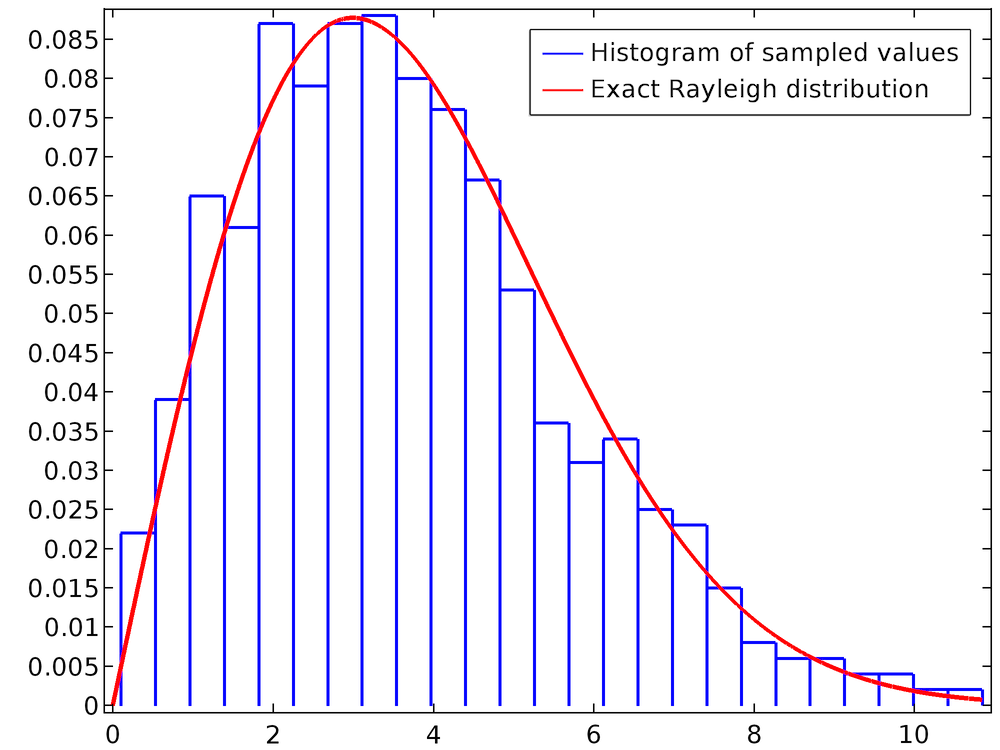
Для точного "воспроизведения" функции распределения вероятностей с большим количеством мелких деталей может потребоваться больше частиц.
Примечание по использованию интерполяционных функций
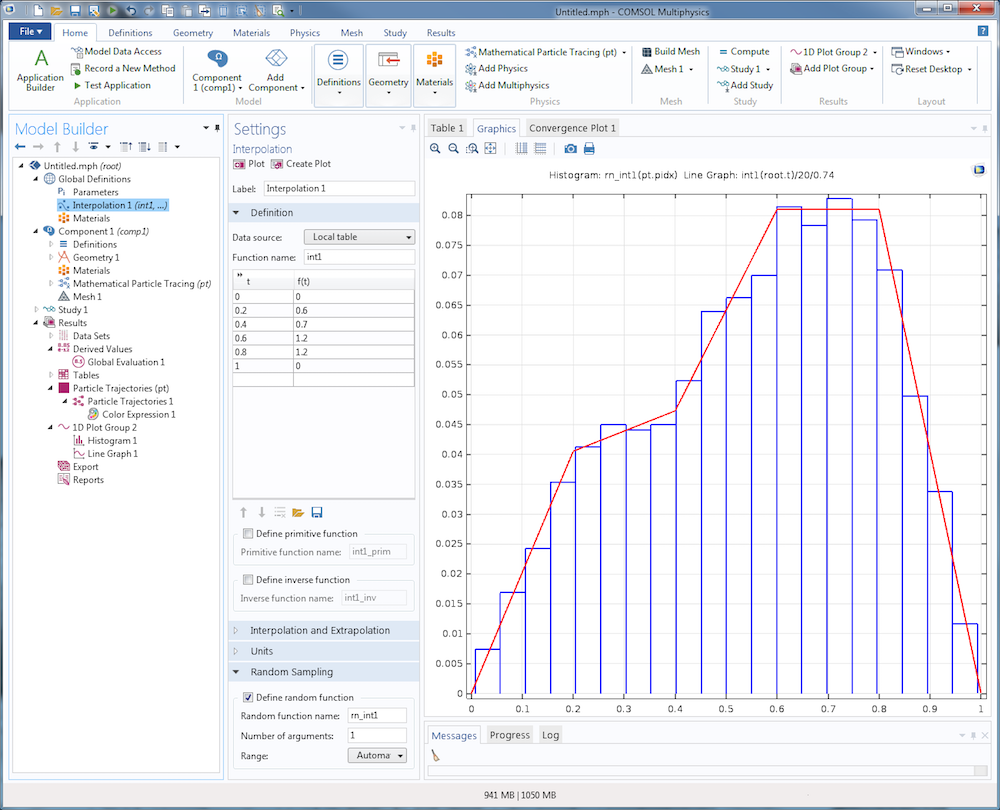
Если функция распределения вероятностей реализуется в COMSOL Multiphysics с помощью интерполяционной функции (Interpolation), а не аналитической (Analytic) или кусочной (Piecewise), то можно использовать встроенные опции для автоматического задания случайной функции на ее основе.
Предположим, что имеется интерполяционная функция с линейной интерполяцией между следующими точками данных:
| x | f(x) |
|---|---|
| 0 | 0 |
| 0.2 | 0.6 |
| 0.4 | 0.7 |
| 0.6 | 1.2 |
| 0.8 | 1.2 |
| 1 | 0 |
На следующем снимке экрана показано, как можно ввести эти данные в соотвествующие поля узла фукнции Interpolation. Установив флажок Define random function (Определить случайную функцию) в окне настроек для интерполяционной функции, можно автоматически задать функцию rn_int1 для расчета выборки из этого распределения. В графическом окне гистограмма показывает случайную выборку из 1000 точек данных и непрерывную кривую самой интерполяционной функции. Для корректировки количества столбцов и нормировки интерполяционной функции добавлены дополнительные коэффициенты 20 и 0.74, соответственно.
Использование функций распределения вероятностей в физике пучков
Итак, в данном материале мы разобрали, как связаны функции распределения вероятностей, интегральные функции распределения и их обратные функции. Мы также рассмотрели несколько приемов расчета выборки из равномерной и неравномерной функции распределения вероятностей в моделях COMSOL. В следующей статье из серии Распределения в фазовом пространстве для физики пучков» мы начнем обсуждение непосредственно физики ионных и электронных пучков и выясним, почему для точного моделирования систем пучков предельно важно использовать функции распределения вероятностей.
Телеграм: t.me/ainewsline
Источник: www.comsol.ru