Вижу, значит существую: обзор Deep Learning в Computer Vision (часть 1)
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2019-05-22 11:46

Наверное, дорогой читатель, Вы подумали про Amazon Go. В каком-то смысле стоит задача повторить их успех, однако наше решение больше про внедрение, нежели про построение такого магазина с нуля за огромные деньги.
- Мотивация и что вообще происходит
- Классификация как стиль жизни
- Архитектуры свёрточных нейросетей: 1000 способов достичь одной цели
- Визуализация свёрточных нейросетей: покажи мне страсть
- Я и сам своего рода хирург: извлекаем фичи из нейросетей
- Держись рядом: representation learning для людей и лиц
- Часть 2:
детектирование, оценка позы и распознавание действийбез спойлеров
Мотивация и что вообще происходит
Статья ориентирована в большей степени на людей, которые уже знакомы с машинным обучением и нейросетями. Однако советую прочитать хотя бы первые два раздела — вдруг всё будет понятно :)
Рекомендую курс Антона Конушина «Введение в компьютерное зрение». Лично я проходил его аналог в ШАДе, что заложило прочную основу в понимании обработки изображений и видео.


















Я уже не говорю про многочисленные применения в различных внутренних задачах компаний. Facebook, к примеру, применяет зрение ещё и для того, чтобы фильтровать медиаконтент. В проверке качества/повреждений в промышленности тоже используются методы компьютерного зрения. Дополненной реальности здесь нужно, на самом деле, уделить отдельное внимание, поскольку
Смотивировались. Зарядились. Поехали:
Классификация как стиль жизни

/cats, /dogs и /leather_bags/humans, поместив в каждую папку только фото с соответствующими объектами.

… то лучше сначала прочитать первые 4 статьи из Открытого курса OpenDataScience по ML и ознакомиться с более вводной статьёй по зрению, например, хорошая лекция в Малом ШАДе.
спойлером выше). Помним, что картинка — это тензор размера (Height, Width, 3) (если она цветная). Сетке при обучении на вход всё это обычно подаётся не по одной картинке и не целым датасетом, а батчами, т.е. небольшими порциями объектов (например, 64 картинки в батче).
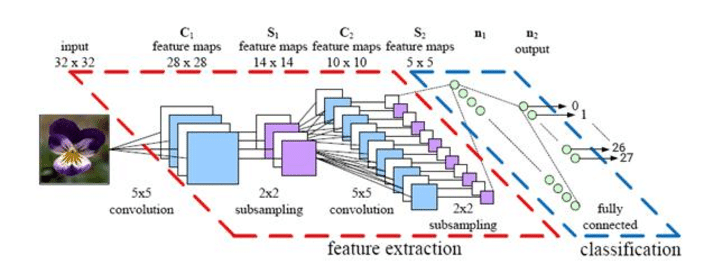
Таким образом, сеть принимает на вход тензор размера (BATCH_SIZE, H, W, 3). Можно “развернуть” каждую картинку в вектор-строку из H*W*3 чисел и работать со значениями в пикселях прямо как с признаками в машинном обучении, обычный Multilayer Perceptron (MLP) так и поступил бы, но это, честно говоря, такой себе бейзлайн, поскольку работа с пикселями как с вектор-строкой никак не учитывает, например, трансляционную инвариантность объектов на картинке. Тот же кот может быть как в середине фото, так и в углу, MLP эту закономерность не выучит. Значит нужно что-то по-умнее, например, операция свёртки. И это уже про современное зрение, про свёрточные нейронные сети:
# взято из официального туториала: # https://pytorch.org/tutorials/beginner/blitz/cifar10_tutorial.html import torch.nn as nn import torch.nn.functional as F import torch.optim as optim class Net(nn.Module): def __init__(self): super(Net, self).__init__() self.conv1 = nn.Conv2d(3, 6, 5) self.pool = nn.MaxPool2d(2, 2) self.conv2 = nn.Conv2d(6, 16, 5) self.fc1 = nn.Linear(16 * 5 * 5, 120) self.fc2 = nn.Linear(120, 84) self.fc3 = nn.Linear(84, 10) def forward(self, x): x = self.pool(F.relu(self.conv1(x))) x = self.pool(F.relu(self.conv2(x))) x = x.view(-1, 16 * 5 * 5) x = F.relu(self.fc1(x)) x = F.relu(self.fc2(x)) x = self.fc3(x) return x net = Net() criterion = nn.CrossEntropyLoss() optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9) for epoch in range(2): # loop over the dataset multiple times running_loss = 0.0 for i, data in enumerate(trainloader, 0): # get the inputs inputs, labels = data # zero the parameter gradients optimizer.zero_grad() # forward + backward + optimize outputs = net(inputs) loss = criterion(outputs, labels) loss.backward() optimizer.step() # print statistics running_loss += loss.item() if i % 2000 == 1999: # print every 2000 mini-batches print('[%d, %5d] loss: %.3f' % (epoch + 1, i + 1, running_loss / 2000)) running_loss = 0.0 print('Finished Training') - Данные (уже есть)
- Архитектура сети (самое интересное)
- Функция потерь, которая будет говорить, как нейросети учиться (здесь это будет кросс-энтропия)
- Метод оптимизации (будет менять веса сети в нужную сторону)
- Задать гиперпараметры архитектуры и оптимизатора (например, размер шага оптимизатора, количество нейронов в слоях, коэффициенты регуляризации)
В коде именно это и реализовано, сама свёрточная нейросеть описана в классе Net().
Если хочется не спеша и с начала узнать про свёртки и свёрточные сети, рекомендую лекцию в Deep Learning School (ФПМИ МФТИ) (на русском) на эту тему, и, конечно же, курс Стэнфорда cs231n (на английском).
Deep Learning School при Лаборатории Инноватики ФПМИ МФТИ — это организация, которая активно занимается разработкой открытого русскоязычного курса по нейросетям. В статье я буду несколько раз ссылаться на эти видеоуроки.

Архитектуры свёрточных нейросетей: 1000 способов достичь одной цели


К 2012 году был дан собран ImageNet, и для соревнования ILSVRC использовалась его подвыборка из тысяч картинок и 1000 классов. Сейчас в ImageNet ~14 миллионов картинок и 21841 класс (взято с оф. сайта), но для соревнования всё равно обычно выделяют лишь подмножество. ILSVRC тогда стал самым крупным ежегодным соревнованием по классификации изображений. Кстати, недавно придумали, как можно обучить на ImageNet'е за считанные минуты. Именно на ImageNet (в ILSVRC) с 2010 по 2018 получали SOTA-нейросети в задаче классификации изображений. Правда уже с 2016 года более актуальны соревнования по локализации, детектирования и понимания сцены, а не классификацию.
| Год | Статья | Ключевая идея | Вес |
|---|---|---|---|
| 2012 | AlexNet | использовать две свёртки подряд; делить обучение сети на две параллельных ветки | 240 MB |
| 2013 | ZFNet | размер фильтров, число фильтров в слоях | -- |
| 2013 | Overfeat | один из первых нейросетевых детекторов | -- |
| 2014 | VGG | глубина сети (13-19 слоёв), использование нескольких блоков Conv-Conv-Pool с меньшим размером свёрток (3х3) | 549MB (VGG-19) |
| 2014 | Inception (v1) (она же GoogLeNet) | 1х1-свёртка (идея из Network-in-Network), auxilary losses (или deep supervision), стекинг выходов нескольких свёрток (Inception-блок) | -- |
| 2015 | ResNet | residual connections, очень большая глубина (152 слоя..) | 98 MB (ResNet-50), 232 MB (ResNet-152) |
| Год | Статья | Ключевая идея | Вес |
|---|---|---|---|
| 2015 | Inception v2 и v3 | разложение свёрток в свёртки 1хN и Nx1 | 92 MB |
| 2016 | Inception v4 и Inception-ResNet | совмещение Inception и ResNet | 215 MB |
| 2016-17 | ResNeXt | 2 место ILSVRC, использование многих веток ( “обобщённый” Inception-блок) | -- |
| 2017 | Xception | depthwise separable convolution, меньше весит при сравнимой с Inception точности | 88 MB |
| 2017 | DenseNet | Dense-блок; лёгкая, но точная | 33 MB (DenseNet-121), 80 MB (DenseNet-201) |
| 2018 | SENet | Squeeze-and-Excitation блок | 46 MB (SENet-Inception), 440 MB (SENet-154) |
Поскольку нейросети внутри себя лишь перемножают тензоры, то количество операций умножения (читай: количество весов) напрямую влияет на скорость работы (если не используются трудоёмкие пост- или предобработка). Сама скорость работы сети зависит от реализации (фреймворка), железа, на котором выполняется, и от размера входной картинки.
| Год | Статья | Ключевая идея | Вес | Пример реализации |
|---|---|---|---|---|
| 2016 | SqueezeNet | FireModule сжатия-разжатия | 0.5 MB | Caffe |
| 2017 | NASNet | получена нейронным поиском архитектур, это сеть из разряда AutoML | 23 MB | PyTorch |
| 2017 | ShuffleNet | pointwise group conv, channel shuffle | -- | Caffe |
| 2017 | MobileNet (v1) | depthwise separable convolutions и много других трюков | 16 MB | TensorFlow |
| 2018 | MobileNet (v2) | рекомендую эту статью на Хабре | 14 MB | Caffe |
| 2018 | SqueezeNext | см. картиночки в оригинальном репозитории | -- | Caffe |
| 2018 | MnasNet | нейропоиск архитектуры специально под мобильные устройства с помощью RL | ~2 MB | TensorFlow |
| 2019 | MobileNet (v3) | она вышла, пока я писал статью :) | -- | PyTorch |
Но хочется как-то больше доверять CNN, а то напридумывали чёрных коробок, а что «внутри» — не очевидно. Чтобы лучше понимать механизм функционирования свёрточных сетей, исследователи придумали использовать визуализацию.
Визуализация свёрточных нейросетей: покажи мне страсть
Важным шагом к осознанию того, что происходит внутри свёрточных сетей, стала статья «Visualizing and Understanding Convolutional Networks». В ней авторы предложили несколько способов визуализации того, на что именно (на какие части картинки) реагируют нейроны в разных слоях CNN (рекомендую также посмотреть лекцию Стэнфорда на эту тему). Результаты получились весьма впечатляющие: авторы показали, что первые слои свёрточной сети реагируют на какие-то «низкоуровневые вещи» по типу краёв/углов/линий, а последние слои реагируют уже на целые части изображений (см. картинку ниже), то есть уже несут в себе некоторую семантику.



Я и сам своего рода хирург: извлекаем фичи из нейросетей
Представим, что есть картинка, и мы хотим найти похожие на неё визуально (так умеет, например, поиск по картинке в Яндекс.Картинки). Раньше (до нейросетей) инженеры для этого извлекали фичи вручную, например, придумывая что-то, что хорошо описывает картинку и позволит её сравнивать с другими. В основном, эти методы (HOG, SIFT) оперируют градиентами картинок, обычно именно эти штуки и называют «классическими» дескрипторами изображений. Особо интересующихся отсылаю к статье и к курсу Антона Конушина (это не реклама, просто курс хороший :)
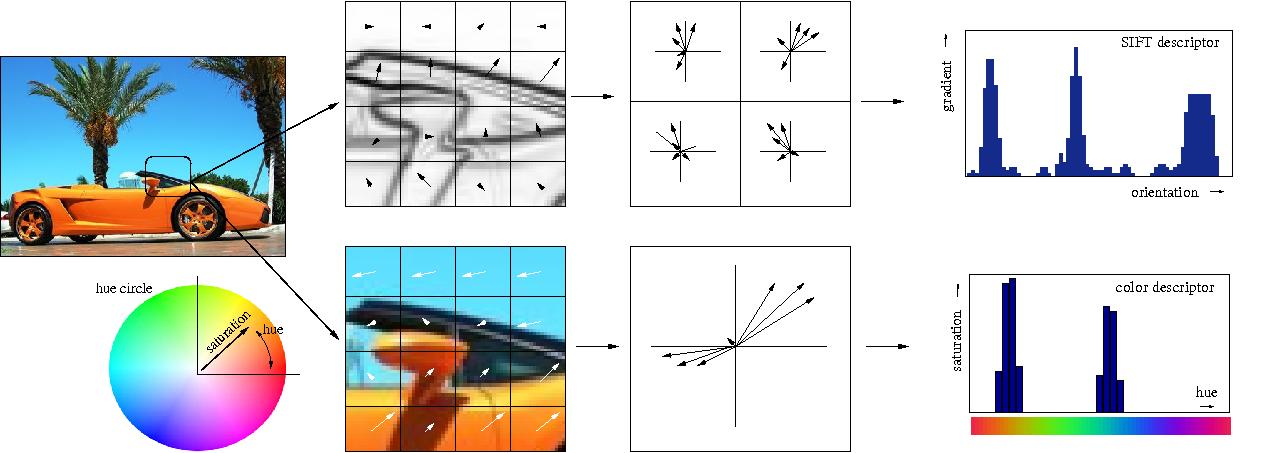
2). Обучение поверх этих фич Fully Connected (FC) слоёв-классификаторов
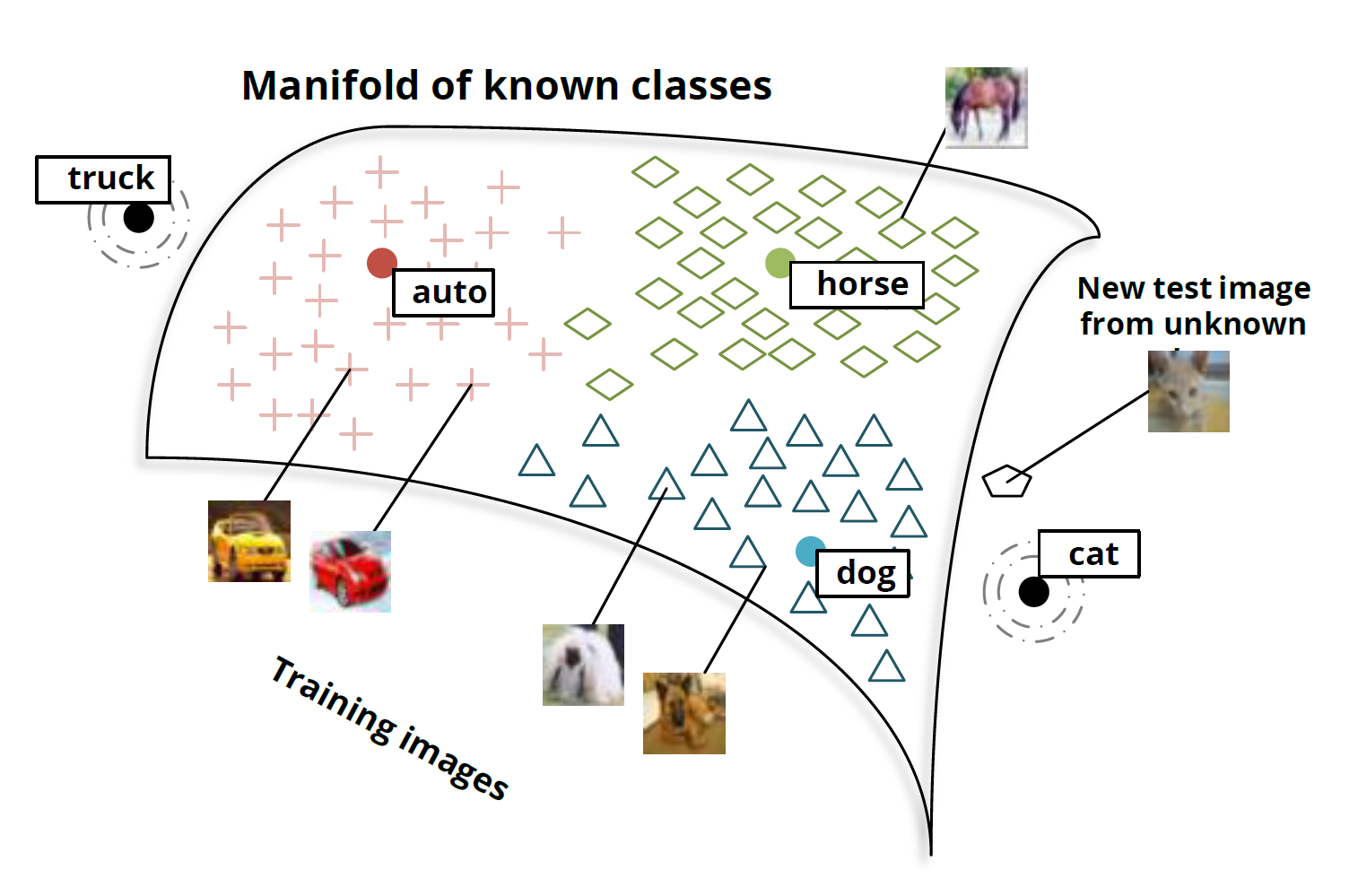
Да, на самом деле фичи можно получить и автоэнкодерами. На моей практике делали по-разному, но, например, в статьях по ре-идентификации (о которой речь будет дальше), чаще всё же берут фичи после extractor'a, а не обучают для этого автоэнкодер. Мне кажется, стоит провести эксперименты в обоих направлениях, если стоит вопрос о том, что работает лучше.

Оригинальная статья, а вообще зачем читать много текста, если можно посмотреть видео
Держись рядом: representation learning для людей и лиц
Если почитать научные статьи, то иногда складывается впечатление, что некоторые авторы понимают словосочетание metric learning по-разному, и нет какого-то единого мнения на счёт того, какие методы называть metric learning, а какие нет. Именно поэтому в данной статье я решил избежать именно этого словосочетания и использовал более логичное representation learning, некоторые читатели могут с этим не согласиться — буду рад обсудить в комментариях.
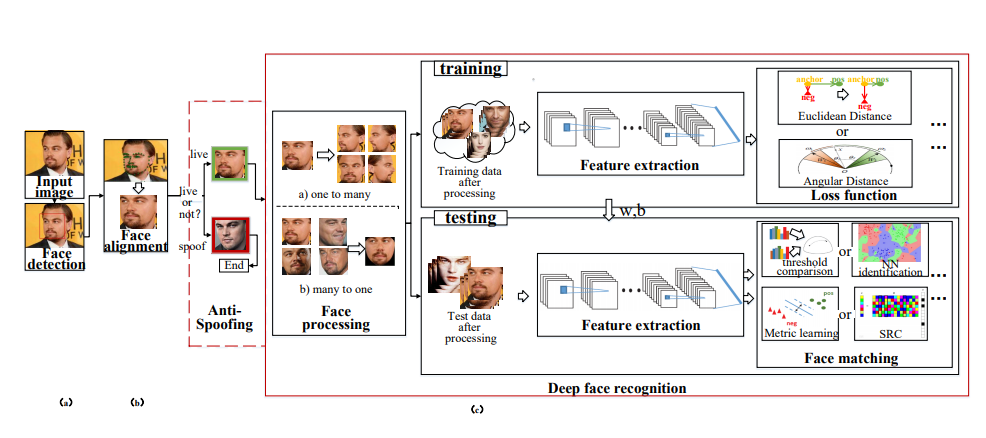
- Задача 1: есть галерея (набор) фотографий лиц людей, хотим, чтобы по новому фото сеть умела отвечать либо именем человека из галереи (мол, это он), либо говорила, что такого человека в галерее нет (и, возможно, добавляем в неё нового человека)

- Задача 2: то же самое, но работаем не с фотографиями лиц, а с кропами людей в полный рост

Первую задачу обычно называют распознаванием лиц, вторую — ре-идентификацией (сокращённо Reid). Я объединил их в один блок, поскольку в их решениях сегодня используются схожие идеи: для того, чтобы выучивать эффективные эмбеддинги картинок, которые могут справляться и с довольно сложными ситуациями, сегодня используют различные типы лоссов, такие как, например, triplet loss, quadruplet loss, contrastive-center loss, cosine loss.
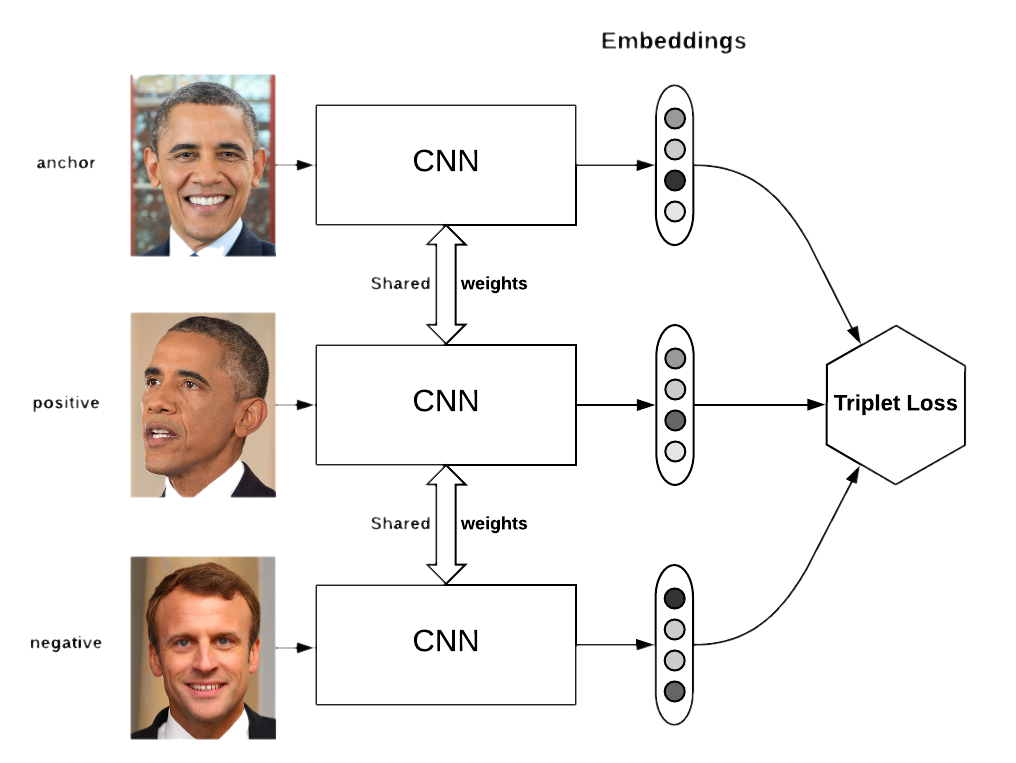
На стадии обучения: обучаем нейросеть либо на классификацию (Softmax + CrossEntropy), либо с помощью специального лосса (Triplet, Contrastive, etc.). Во втором случае ещё нужно правильно подбирать positive'ы и negative'ы в каждом батче
На стадии предсказания: если это был именно какой-то особый лосс по типу триплета, то он на вход принимал уже эмбеддинги — их и берём. Если была классификация, то тут нужно экспериментировать — можно брать фичи с какого-то из свёрточных слоёв, а можно и вероятности после классификатора (да, так делают и это работает). Далее ищем расстояние от пришедшей в тесте картинки до всех картинок из галереи и выдаём метку ближайшей. Расстояние меряем косинусом или Евклидовой метрикой
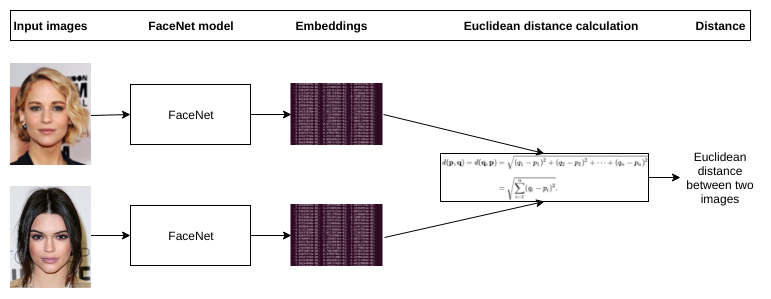



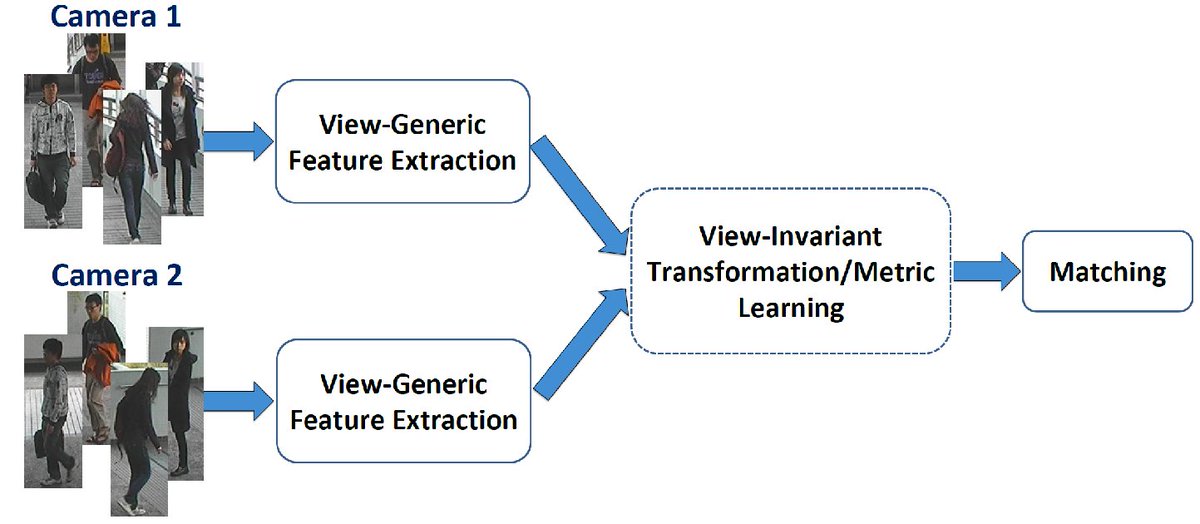
Несмотря на все эти продвинутые методы, в моих экспериментах, почему-то, лучше всего себя показал именно подход с классификацией. Возможно, я что-то не учёл, но пока что немного грустно, что придумали столько всего, а в итоге работает старая добрая логистическая регрессия классификация. Но главное — пробовать и не сдаваться!
Слово про ускорение нейросетей
Мы уже говорили о том, что можно просто придумать легковесную архитектуру. Но как быть, если сеть уже обучена и она крута, а сжать её всё равно нужно? В таком случае может помочь один (или все) из следующих методов:
Ну и правило использовать не float64, а, например, float32 никто не отменял. Есть даже свежая статья про low-precision training. Недавно, кстати, Google представил MorphNet, которая (вроде как) помогает автоматически сжимать модель.
А что дальше?

ФПМИ МФТИ организует программу бакалавриата (кстати, теперь и на английском, для иностранных студентов), однако сейчас активно развиваются и магистерские программы, причём как очные, так и онлайн. Со всем списком образовательных возможностей ФПМИ МФТИ можно ознакомиться здесь. Если вам интересно, буду рад обсудить конкретные программы в комментариях или личных сообщениях, а то ведь Физтех уже не тот (в хорошем смысле).
Телеграм: t.me/ainewsline
Источник: habr.com