Соревнование ML-систем на лингвистическом материале. Как мы учились заполнять пропуски
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2019-05-29 16:15

- Генерация заголовков для новостных статей.
- Разрешение анафоры и кореференции.
- Морфологический анализ на материале малоресурсных языков.
- Автоматический анализ одного из видов эллипсиса (гэппинга).
Сегодня мы расскажем про последнюю из них: что такое эллипсис и зачем учить машину восстанавливать его в тексте, как мы создавали новый корпус, на котором можно решить эту задачу, как проходили сами соревнования и каких результатов смогли добиться участники.
AGRR-2019 (Automatic Gapping Resolution for Russian)
Осенью 2018 года перед нами встала исследовательская задача, связанная с эллипсисом — намеренным пропуском цепочки слов в тексте, которую можно восстановить из контекста. Как автоматически найти в тексте такой пропуск и правильно его заполнить? Это легко для носителя языка, но научить этому машину непросто. Довольно быстро стало понятно, что это хороший материал для соревнования, и мы взялись за дело.
В организации соревнований по новой теме есть свои особенности, и нам они во многом кажутся плюсами. Одна из основных вещей — создание корпуса (множества текстов с разметкой, на которых можно обучаться). Как он должен выглядеть и какого объема быть? Для многих задач существуют стандарты представления данных, от которых можно отталкиваться. Так, например, для задачи определения именованных сущностей разработаны IO/BIO/IOBES схемы разметки, для задач синтаксического и морфологического парсинга традиционно используется CONLL формат, изобретать ничего не нужно, зато нужно строго следовать гайдлайнам. В нашем случае, собрать корпус и сформулировать задачу нам предстояло самим.
Вот такая вот задача...
Тут нам неизбежно придется сделать популярно-лингвистическое введение о том, что такое эллипсис вообще и гэппинг как один из его видов.
Каких бы представлений о языке вы ни придерживались, сложно спорить с тем, что поверхностный уровень выражения (текст или речь) не единственный. Сказанная фраза — это вершина айсберга. Сам айсберг включает в себя прагматическую оценку, построение синтаксической структуры, подбор лексического материала и так далее. Эллипсис — явление, красиво связывающее поверхностный уровень с глубинным. Это опущение повторяющихся элементов синтаксической структуры. Если мы представим синтаксическую структуру предложения в виде дерева и в этом дереве можно будет выделить одинаковые поддеревья, то часто (но не всегда), для того чтобы предложение было естественным, повторяющиеся элементы удаляются. Такое удаление и называется эллипсисом (пример 1).
(1) Мне так и не перезвонили, и я не понимаю, почему мне так и не перезвонили.
Пропуски, получаемые при эллипсисе, можно однозначно восстановить из языкового контекста. Сравните первый пример со вторым (2), где есть пропуск, но что именно там пропущено — непонятно. Этот случай не является эллипсисом.
(2)
(3) Я принял ее за итальянку, а его — за шведа.
Во всех примерах больше двух предложений (клауз), они сочинены между собой. В первой клаузе присутствует глагол (лингвисты, скорее, скажут «предикат») принял и его участники: я, ее и за итальянку. Во второй клаузе выраженного глагола нет, есть только не связанные синтаксически между собой «остатки» (или ремнанты) его и за шведа, но мы понимаем, как восстанавливается пропуск.
Для восстановления пропуска мы обращаемся к первой клаузе и копируем из нее всю структуру (пример 4). Заменяем только те части, для которых в неполной клаузе есть «параллельные» ремнанты. Копируем предикат принял, ее заменяем на его, за итальянку заменяем на ремнант за шведа. Для я параллельного ремнанта не нашлось, значит, копируем его без замены.
(4) Я принял ее за итальянку, а его я принял за шведа.
Похоже, что для восстановления пропуска нам достаточно определить, есть ли в этом предложении гэппинг, найти неполную клаузу и связанную с ней полную (из которой берется материал для восстановления), а затем понять, какие в неполной клаузе есть «остатки» (ремнанты) и чему они соответствуют в полной. Кажется, этих условий достаточно, чтобы эффективно заполнить пробел. Таким образом мы пытаемся сымитировать процесс в голове у человека, читающего или слышащего текст, в котором возможно есть пропуски.
Так, а зачем это нужно?
Понятно, что у человека, который впервые слышит про эллипсис и связанные с ним сложности обработки, может возникнуть закономерный вопрос «А зачем». Скептикам хочется предложить почитать отцов лингвистической науки объяснить, что если решение прикладной задачи даст материал, который может быть полезен в теоретических исследованиях, то это уже достаточный ответ на вопрос о цели такой деятельности.
Теоретики занимаются изучением эллипсиса в разных языках уже около 50 лет, описывают ограничения, выделяют общие закономерности в разных языках. При этом нам неизвестно о существовании корпуса, иллюстрирующего какой-нибудь из видов эллипсиса на более чем нескольких сотнях примеров. Это отчасти связано с редкостью явления (например, на наших данных гэппинг встречается не более чем в 5 предложениях из 10 тысяч). Так что создание такого корпуса уже является важным результатом.
В прикладных системах, работающих с текстовыми данными, редкость явления позволяет просто игнорировать его. Неспособность синтаксического парсера восстановить пропуски при гэппинге точно не принесет много ошибок. Но из редких явлений складывается обширная и пестрая языковая периферия. Кажется, что опыт решения такой задачи сам по себе должен быть интересен тем, кто хочет создавать системы, работающие не только на простых, коротких, чистых текстах с общеупотребительной лексикой, то есть на сферических текстах в вакууме, которые в природе практически не встречаются.
Немногие парсеры могут похвастаться эффективной системой по определению и разрешению эллипсиса. Но во внутреннем парсере ABBYY есть модуль, отвечающий за восстановление пропусков, и в его основе лежат написанные вручную правила. Благодаря этой способности парсера мы и смогли создать большой корпус для соревнования. Потенциальная польза для исходного парсера заключается в замене медленно работающего модуля. Также во время работы над корпусом мы провели детальный анализ ошибок нынешней системы.
Как мы создавали корпус
Наш корпус в первую очередь предназначается для обучения автоматических систем, а значит, крайне важно, чтобы он был объемным и разнообразным. Руководствуясь этим, мы выстроили работу по сбору данных следующим образом. Для корпуса мы отобрали тексты разных жанров: от технической документации и патентов до новостей и постов из социальных медиа. Все они были размечены парсером ABBYY. В течение месяца мы распределяли между лингвистами-разметчиками данные. Разметчикам предлагалось, не меняя разметку, оценить ее по шкале:
0 — в предложении нет гэппинга, разметка нерелевантна.
1 — гэппинг есть, и его разметка верна.
2 — гэппинг есть, но с разметкой что-то не то.
3 — сложный случай, гэппинг ли это вообще?
В итоге нам пригодилась каждая из групп. Примеры из категории 1 попадали в положительный класс нашего датасета. Примеры из категорий 2 и 3 мы принципиально не хотели переразмечать вручную в целях экономии времени, но эти примеры пригодились нам позже для оценки нашего полученного корпуса. По ним можно судить, какие случаи система размечает стабильно неверно, а значит, они не попадают в наш корпус. И наконец, включая в корпус примеры, отнесенные разметчиками к категории 0, мы давали системам возможность «учиться на чужих ошибках», то есть не просто имитировать поведение исходной системы, а работать лучше нее.
Каждый пример оценивали по два разметчика. После этого из исходных данных в корпус попало чуть больше половины предложений. Из них и состоит весь положительный класс примеров и часть отрицательного. Мы решили сделать отрицательный класс в два раза больше положительного, чтобы, с одной стороны, классы были сравнимы по объему, а с другой — сохранялся перевес отрицательного класса, существующий в языке.
Чтобы соблюсти эту пропорцию, мы должны были добавить в корпус еще отрицательных примеров, помимо описанных примеров категории 0. Приведем пример (5) категории 0, который может запутать не только машину, но и человека.
(5) Но к тому времени Джек был влюблен в Синди Пейдж, сейчас – миссис Джек Свайтек.
Во второй клаузе не восстанавливается влюблен, ведь имеется в виду, что сейчас Синди Пейдж стала миссис Джек Свайтек, потому что вышла за него замуж.
Вообще, для такого сравнительно редкого синтаксического явления как гэппинг отрицательным примером является практически любое случайное предложение языка, ведь вероятность, что в случайном предложении найдется гэппинг, крошечная. Однако использование таких отрицательных примеров может привести к переобучению на знаках препинания. В нашем корпусе примеры для отрицательного класса добирались по простым критериям: наличие глагола, наличие запятой или тире, минимальная длина предложения не меньше 6 токенов.
Для соревнования мы выделили из обучающего корпуса dev часть (в пропорции 1:5), которую участникам предлагалось использовать для настройки своих систем. Финальные версии систем обучались на объединенных train и dev частях. Тестовый корпус (test) мы размечали своими силами вручную, по объему он составляет 10-ую часть train + dev. Вот точное количество примеров по классам:

Формат разметки
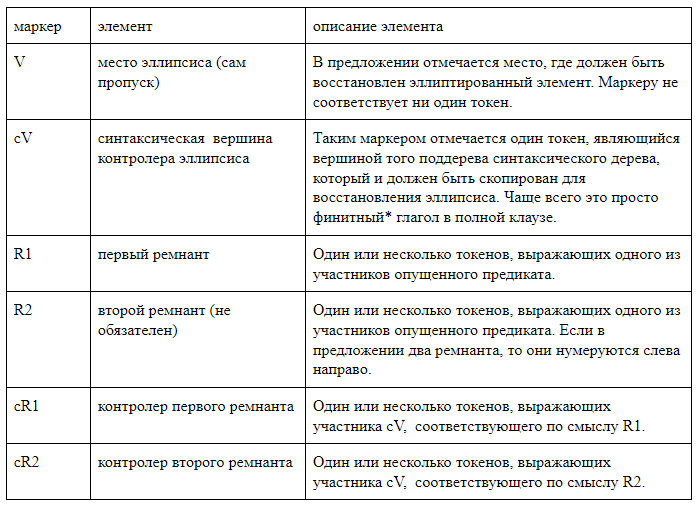
Мы сознательно отказались от использования сторонних парсеров и разработали разметку, в которой все интересующие нас элементы линейно отмечены в текстовой строке. Мы использовали два типа разметки. Первый, человекочитаемый, предназначен для работы с разметкой, и в нем удобно проводить анализ ошибок полученных систем. При таком способе квадратными скобками внутри предложения отмечаются все элементы гэппинга. Каждая пара скобок маркирована названием соответствующего элемента. Мы использовали следующие обозначения:

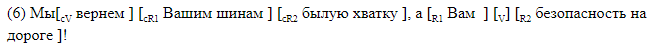
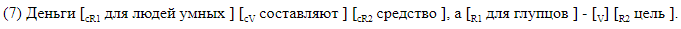


Задачи для участников
Участники AGRR-2019 могли решить любые из трех задач:
- Бинарная классификация. Нужно определить, есть ли в предложении гэппинг.
- Разрешение гэппинга. Нужно восстановить позиции пропуска (V) и позиции глагольного контролера (cV).
- Полная разметка. Нужно определить оффсеты для всех элементов гэппинга.
Каждая следующая задача так или иначе должна решать предыдущую. Понятно, что любая разметка возможна только в предложениях, на которых бинарная классификация показывает положительный класс (гэппинг есть), а полная разметка включает в себя и нахождение границ пропущенного и контролирующего предикатов.
Метрики
Для задачи бинарной классификации мы использовали стандартные метрики: точность и полноту, — а результаты участников ранжировались по f-мере.
Для задач разрешения гэппинга и полной разметки мы решили пользоваться посимвольной f-мерой, так как исходные тексты не были токенизированы и мы не хотели, чтобы разница в используемых участниками токенизаторах могла повлиять на результаты. True-negative примеры не вносили вклад в посимвольную f-меру, для каждого элемента разметки считалась своя f-мера, финальный результат получался макро-усреднением по всему корпусу. Благодаря такому подсчету метрики, false-positive случаи ощутимо штрафовались, что важно в случае когда положительных примеров в реальных данных во много раз меньше отрицательных.
Ход соревнования
Параллельно со сбором корпуса мы принимали заявки на участие в соревновании. В итоге мы зарегистрировали больше 40 участников. Затем мы выложили обучающий корпус и запустили соревнования. У участников было 4 недели на то, чтобы построить свои модели.
Этап оценки результатов проходил следующим образом: участники получили 20 тысяч предложений без разметки, внутри которых был замешан тестовый корпус. Команды должны были разметить эти данные своими системами, после чего мы оценивали результаты разметок на тестовом корпусе. Замешивание теста в большом объеме данных гарантировало нам, что корпус при всем желании не получится разметить вручную за те несколько дней, которые давались на прогон (автоматическую разметку).
Результаты соревнования
До финала дошли 9 команд, среди которых — представители двух IT-компаний, исследователи из МГУ, МФТИ, НИУ ВШЭ и ИППИ РАН.
Все команды, кроме одной, участвовали во всех трех соревнованиях. По условиям AGRR-2019 все команды опубликовали код своих решений. Сводная таблица с результатами приведена в нашем репозитории, там же можно найти ссылки на выложенные решения команд с краткими описаниями. Почти все показали высокие результаты. Вот оценки решений команд, занявших призовые места:
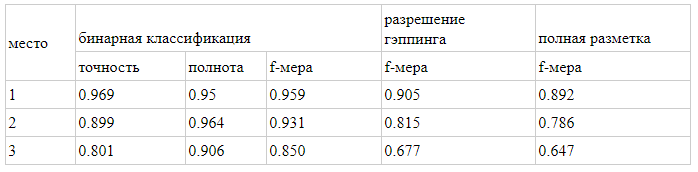
Итак, в этой статье мы рассказали, как, взяв за основу редкое языковое явление, сформулировать задачу, подготовить корпус и провести соревнования. Польза от такой работы есть и для NLP-сообщества, ведь соревнования помогают сравнить различные архитектуры и подходы между собой на конкретном материале, а лингвисты получают корпус редкого явления с возможностью его пополнения (используя решения победителей). Собранный корпус в несколько раз превышает объемы существующих на данный момент корпусов (причем для гэппинга объем корпуса на порядок превосходит объемы корпусов не только для русского, но и вообще для всех языков). Все данные и ссылки на решения участников можно найти в нашем гитхабе.
30 мая на специальной сессии "Диалога", посвященной соревнованиям по автоматическому анализу гэппинга, будут подведены итоги AGRR-2019. Мы расскажем об организации соревнования и подробно остановимся на содержании созданного корпуса, а участники представят выбранные архитектуры, с помощью которых они решали задачу. NLP Advanced Research Group
Телеграм: t.me/ainewsline
Источник: habr.com