Российский Speech-to-text датасет (STT/ASR)
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2019-05-09 18:30
большие данные big data, алгоритмы распознавания речи, распознавание образов

Группа российских разработчиков выпустила свободный датасет speech-to-text на русском языке, содержащий более 4000 тысяч часов записей с голосом для исследователей и разработчиков приложений с распознаванием речи. В ближайшее время создатели датасета планируют добавить еще 1500 часов речи, а в будущем увеличить его объем до 10 или даже 20 тысяч часов.
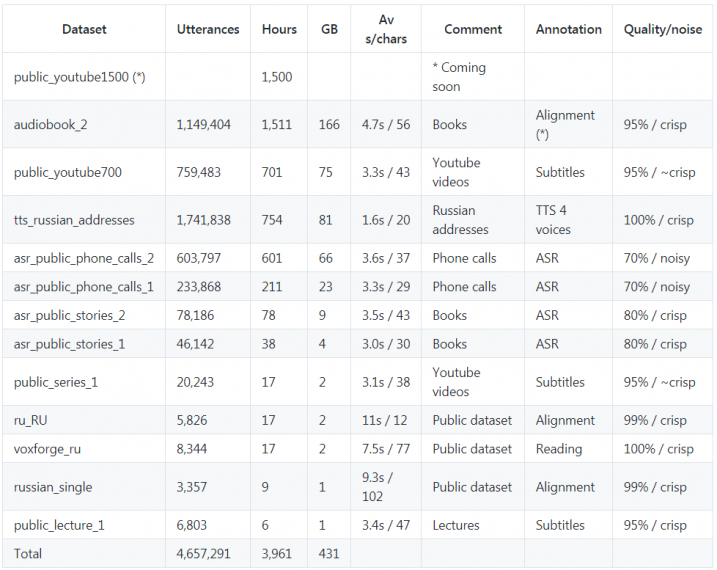
Данные в датасете разнообразны, их качество варьируется от довольно хорошего до почти идеального. Датасет нацелен на бизнес-приложения, поэтому выбирались соответствующие типы данных. Так, часть данных автоматически сгенерирована (ASR). Данные выбирались не только чистые, чтобы модель могла обучаться быть устойчивой к шумам и лучше работать в реальных условиях. Датасет выпущен под лицензией cc by-nc. Для использования в коммерческих целях потребуется связаться с создателями. Сами разработчики рассчитывают, что этот датасет станет подобным датасету Imagenet в области распознавания изображений по полноте и доступности в русскоязычном сегменте.
Особенности датасета:
- Все ссылки являются публичными;
- Датасет размещен в AWS-совместимом хранилище с CDN — скорость загрузки будет хорошей;
- Большая часть данных проверена и записана в одном формате;
- Сбор данных в дисковой БД, оптимизированной для работы даже на жестких дисках (разработчики еще не тестировали ее).
- Файл meta data;
- Некоторые простые изменяемые фрагменты кода для более легкого запуска;
Более подробно о мотивации авторов и особенностях датасета информация в оригинальной статье.
Телеграм: t.me/ainewsline
Источник: neurohive.io