Объясняем мемы про машинное обучение простым языком
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2019-05-10 17:52

Мы привыкли, что машинное обучение — это сложно. Но, оказывается, оно может быть и смешным, особенно если ты днями и ночами пытаешься заставить свои алгоритмы работать. На паблик Мемы про машинное обучение для взрослых мужиков (сейчас он называется Memes on Machine Learning for Young Ladies) подписано больше восьми тысяч человек, ежедневно специалисты по data science заливают в него новые мемы и пишут комментарии. Паша Данилов, студент второго курса Школы анализа данных и один из администраторов сообщества, рассказал, как находить смешное в алгоритмах и программировании на Python, и объяснил несколько специфических шуток, понять которые дано далеко не каждому.
— Расскажи про историю сообщества и про то, над чем вообще принято смеяться у датасаентистов?
Идея создать паблик не моя: до этого дошел мой приятель Данила, с которым мы уже достаточно давно знакомы. Паблик начинался с шуток про общественное представление о data science, деятельность российских и мировых ученых, а также о том, как просто выигрывать все конкурсы на Kaggle с помощью XGBoost. В определенный момент это была самая популярная реализация градиентного бустинга — алгоритма, который очень эффективно показывал себя во многих задачах. Со временем аудитория росла, на паблик начали подписываться очень крутые ребята, занимающиеся машинным обучением, хайп вокруг нейросетей продолжал расти, и как следствие, стало появляться все больше новых мемов.
Часть из них посвящена содержанию последних статей и конференций, часть это наложение профессиональных деформаций на окружающие нас явления и события Еще лучше, если ситуация и без того смешная, а к ней добавили контекст machine learning — это гарантия популярности поста.
Больше всего мы ценим не популярные посты, а те, где надо что-то осмыслить или быть в курсе последних событий в области и как-то связать это все в голове, прежде чем засмеяться в голос на всю квартиру. И, конечно, всем нравится адаптация популярных в интернете мемов под тематику машинного обучения. Этим летом были очень популярны вариации мема про продавца машин, только у нас он впаривал потенциальному покупателю разные алгоритмы.
— Ну а что смешного, например, вот здесь? Ошибка в коде?
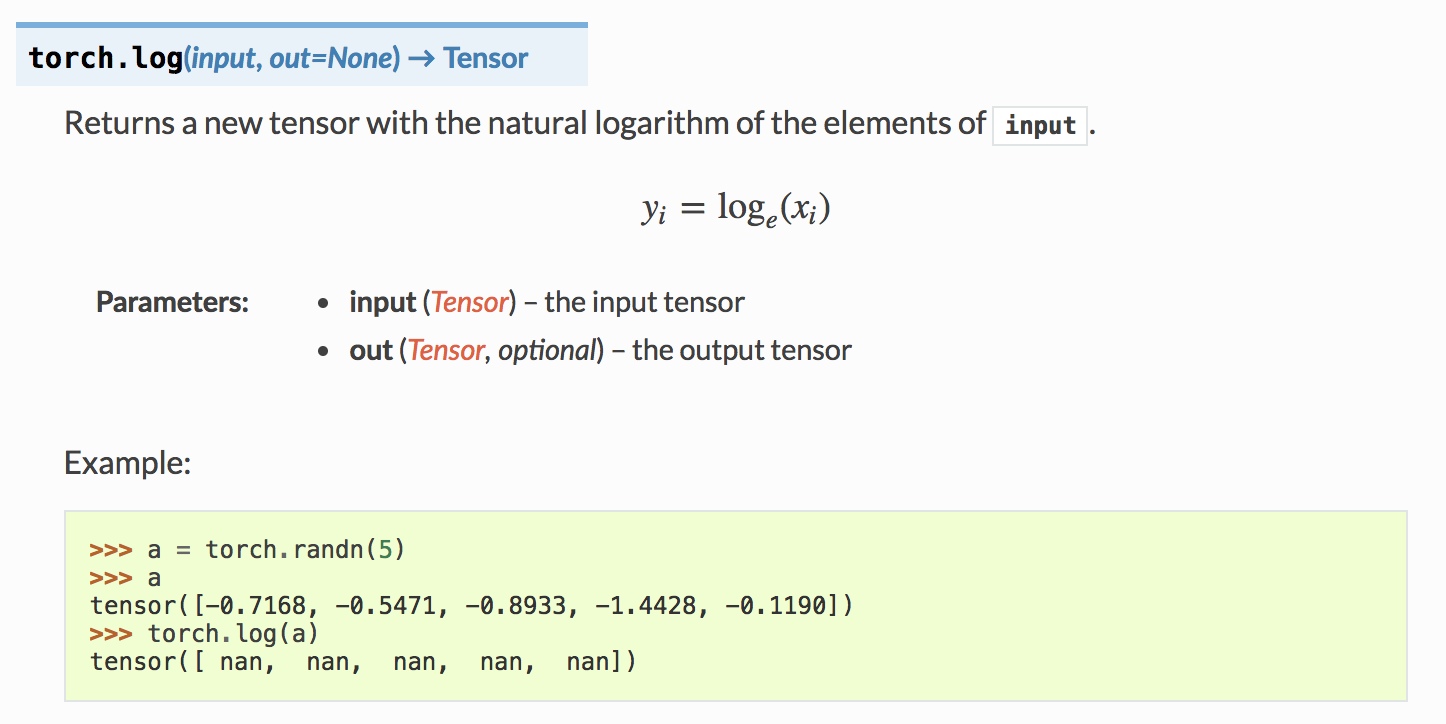
Среди подписчиков и в особенности админов паблика горячо любим фреймворк для глубинного обучения PyTorch, потому что в сравнении с TensorFlow он более приятен в использовании. Еще мы любим его за то, что в документации к нему специально указываются примеры использования. Поскольку документация генерируется автоматически при каждом обновлении репозитория, функции, генерирующие случайные значения, могут выдавать не самые лучшие примеры, и за этим никто специально не следит.
Данный кусок относится к реализации функции «натуральный логарифм», но так вышло, что все пять значений оказались отрицательными, а логарифм, как известно, для них не определен. В итоге получилась не самая удачная демонстрация того, как работает функция логарифма, порожденная рандомом.
— Шутки про котиков, конечно, актуальны в любом сообществе. Расскажи, что не так на этом видео? Что такое это fine tune?

Fine tuning — это процедура использования информации из нейросетей, обученных на больших коллекциях (например, на очень большой базе фотографий различных объектов), для решения желаемой задачи. Суть в том, что обычно все слои нейросети оставляют в том состоянии, в каком они есть после обучения на большой коллекции, заменяется только выходной слой в зависимости от задачи.
Допустим, мы хотим определять, автомобиль какого производителя находится на фотографии, и та часть сети, которую мы оставили неизменной, «видела» уже много автомобилей и не автомобилей, таким образом, она «представляет», куда нужно «смотреть», чтобы «увидеть» контуры автомобиля и его текстуру. Добавив новый выходной слой по числу классов производителей автомобилей, мы окончательно настраиваем нейросеть, чтобы она распознавала то что нам нужно. Если же просто заменить выходной слой от обученной ранее сети на тот, что нужен в решаемой задаче, и не дообучить ее на нужных данных, сеть не будет настроена делать какие-то осмысленные решения и будет делать классификацию плохого качества, «путаться» в принятии решения.
Так и получилось на картинке: кот как будто бы пьет воду, находясь рядом с краном, делает похожие движения, но на самом деле не пьет, то есть не делает того, что было задумано.
— Вот здесь, кажется, про какую-то боль всех исследователей. Что у вас болит?

Это адаптация мема The Floor is Lava под нашу тематику. Понятно, что по лаве никто ходить не хочет, поэтому пола нельзя касаться ни в коем случае — про это оригинал мема. Собственно, он легко адаптируется под вещи, которые человек избегает делать. В нашем случае они избегают нормального написания кода. Часто исследователи из мира data sciecne не придерживаются принятых в разработке программного обеспечения практик: не соблюдают конвенции, да что уж там греха таить, зачастую просто пишут не очень хорошо читаемый код. Часто это из-за того, что хорошие исследователи обычно математики и у них не так много опыта написания промышленного кода.
— Эта шутка вовсе похожа на издевательство, о чём это вообще?
Здесь изображена полносвязная нейросеть, которая считается самой базовой архитектурой. На вход подаем картинки, звуки, кадры, обрабатываем через сеть, внутри которой происходит магия, изображенная задумчивым смайликом, на выходе — разные классы объектов. Да, это действительно для людей, которые, например, чересчур щедры в использовании смайликов, чтобы им было понятнее на их языке.
— Как на такие мемы реагируют подписчики?
Недавно мы перевалили уже за восемь тысяч человек (для сравнения, в одном из самых крупных серьезных VK-сообществ по машинному обучению порядка 15 тысяч подписчиков). Сначала мы достаточно много постов делали своими руками, но с ростом аудитории, а главное, с появлением активных подписчиков, умеющих делать годные мемы, наша деятельность все чаще стала сводиться к одобрению или реджекту постов, хотя мы и сами делаем еще немало мемов.

В прошлом году даже наградили человека за лучший предложенный пост уже ставшей классической книгой Pattern Recognition and Machine Learning, написанной Кристофером Бишопом. Кстати, у нас есть планы по интернационализации, но пока мы еще не до конца понимаем, как лучше сделать этот переход.
Телеграм: t.me/ainewsline
Источник: academy.yandex.ru