NLP. Основы. Техники. Саморазвитие. Часть 2: NER
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2019-05-14 16:15

Зачем нужно решать задачу NER
Нетрудно понять, что, даже если мы хорошо научимся выделять в тексте персоны, локации и организации, вряд ли это вызовет большой интерес у заказчиков. Хотя какое-то практическое применение, конечно, есть и у задачи в классической постановке.
Один из сценариев, когда решение задачи в классической постановке все-таки может понадобиться, — структуризация неструктурированных данных. Пусть у вас есть какой-то текст (или набор текстов), и данные из него нужно ввести в базу данных (таблицу). Классические именованные сущности могут соответствовать строкам такой таблицы или же служить содержанием каких-то ячеек. Соответственно, чтобы правильно заполнять таблицу, нужно перед этим выделить в тексте те данные, которые вы будете в нее вносить (обычно после этого есть еще один этап — идентификация сущностей в тексте, когда мы понимаем, что спаны “ООН” и “Организация Объединенных Наций” относятся к одной и той же организации; однако, задача идентификации или entity linking — это уже другая задача, и о ней мы подробно рассказывать в этом посте не будем).
Однако, есть несколько причин, почему NER является одной из самых популярных задач NLP.
Во-первых, извлечение именованных сущностей — это шаг в сторону “понимания” текста. Это может как иметь самостоятельную ценность, так и помочь лучше решать другие задачи NLP.
Так, если мы знаем, где в тексте выделены сущности, то мы можем найти важные для какой-то задачи фрагменты текста. Например, можем выделить только те абзацы, где встречаются сущности какого-то определенного типа, а потом работать только с ними.
Допустим, вам приходит письмо, и хорошо бы сделать сниппет только той части, где есть что-то полезное, а не просто “Здравствуйте, Иван Петрович”. Если уметь выделять именованные сущности, сниппет можно сделать умным, показав ту часть письма, где есть интересующие нас сущности (а не просто показать первое предложение письма, как это часто делается). Или же можно просто подсветить в тексте нужные части письма (или, непосредственно, важные для нас сущности) для удобства работы аналитиков.
Кроме того, сущности – это жесткие и надежные коллокации, их выделение может быть важно для многих задач. Допустим, у вас есть название именованной сущности и, какой бы она ни была, скорее всего, она непрерывна, и все действия с ней нужно совершать как с единым блоком. Например, переводить название сущности в название сущности. Вы хотите перевести «Магазин “Пятерочка”» на французский язык единым куском, а не разбить на несколько не связанных друг с другом фрагментов. Умение определять коллокации полезно и для многих других задач — например, для синтаксического парсинга.
Без решения задачи NER тяжело представить себе решение многих задач NLP, допустим, разрешение местоименной анафоры или построение вопросно-ответных систем. Местоименная анафора позволяет нам понять, к какому элементу текста относится местоимение. Например, пусть мы хотим проанализировать текст “Прискакал Чарминг на белом коне. Принцесса выбежала ему навстречу и поцеловала его”. Если мы выделили на слове “Чарминг” сущность Персона, то машина сможет намного легче понять, что принцесса, скорее всего, поцеловала не коня, а принца Чарминга.
Теперь приведем пример, как выделение именованных сущностей может помочь при построении вопросно-ответных систем. Если задать в вашем любимом поисковике вопрос «Кто играл роль Дарта Вейдера в фильме “Империя наносит ответный удар”», то с большой вероятностью вы получите верный ответ. Это делается как раз с помощью выделения именованных сущностей: выделяем сущности (фильм, роль и т. п.), понимаем, что нас спрашивают, и дальше ищем ответ в базе данных.
Наверное, самое важное соображение, благодаря которому задача NER так популярна: постановка задачи очень гибкая. Другими словами, никто не заставляет нас выделять именно локации, персоны и организации. Мы можем выделять любые нужные нам непрерывные фрагменты текста, которые чем-то отличаются от остального текста. В результате можно подобрать свой набор сущностей для конкретной практической задачи, приходящей от заказчика, разметить корпус текстов этим набором и обучить модель. Такой сценарий встречается повсеместно, и это делает NER одной из самых часто решаемых задач NLP в индустрии.
Приведу пару примеров таких юзкейсов от конкретных заказчиков, в решении которых мне довелось принять участие.
Вот первый из них: пусть у вас есть набор инвойсов (денежных переводов). Каждый инвойс имеет текстовое описание, где содержится необходимая информация о переводе ( кто, кому, когда, что и по какой причине отправил). Например, компания Х перевела 10 долларов компании Y в такую-то дату таким-то образом за то-то. Текст довольно формальный, но пишется живым языком. В банках есть специально обученные люди, которые этот текст читают и затем заносят содержащуюся в нем информацию в базу данных.
Мы можем выбрать набор сущностей, которые соответствуют столбцам таблицы в базе данных (названия компаний, сумма перевода, его дата, тип перевода и т. п.) и научиться автоматически их выделять. После этого остается только занести выделенные сущности в таблицу, а люди, которые раньше читали тексты и заносили информацию в базу данных, смогут заняться более важными и полезными задачами.
Второй юзкейс такой: нужно анализировать письма с заказами из интернет-магазинов. Для этого необходимо знать номер заказа (чтобы все письма, относящиеся к данному заказу, помечать или складывать в отдельную папку), а также другую полезную информацию — название магазина, список товаров, которые были заказаны, сумму по чеку и т. п. Все это — номера заказа, названия магазинов и т. п. — можно считать именованными сущностями, и их тоже несложно научиться выделять с помощью методов, которые мы сейчас разберем.
Если NER – это так полезно, то почему не используется повсеместно?
Почему задача NER не везде решена и коммерческие заказчики до сих пор готовы платить за ее решение не самые маленькие деньги? Казалось бы, все просто: понять, какой кусок текста выделить, и выделить его.
Но в жизни все не так легко, возникают разные сложности.
Классической сложностью, которая мешает нам жить при решении самых разных задач NLP, являются разного рода неоднозначности в языке. Например, многозначные слова и омонимы (см. примеры в части 1). Есть и отдельный вид омонимии, имеющий непосредственное отношение к задаче NER — одним и тем же словом могут называться совершенно разные сущности. Например, пусть у нас есть слово “Вашингтон”. Что это? Персона, город, штат, название магазина, имя собаки, объекта, что-то еще? Чтобы выделить этот участок текста, как конкретную сущность, надо учитывать очень многое – локальный контекст (то, о чем был предшествующий текст), глобальный контекст (знания о мире). Человек все это учитывает, но научить машину делать это непросто.
Вторая сложность – техническая, но не нужно ее недооценивать. Как бы вы ни определили сущность, скорее всего, возникнут какие-то пограничные и непростые случаи — когда нужно выделять сущность, когда не нужно, что включать в спан сущности, а что нет и т. п. (конечно, если наша сущность — это не что-то слабо вариативное, типа емейла; однако выделять такие тривиальные сущности обычно можно тривиальными методами — написать регулярное выражение и не думать ни о каком машинном обучении).
Пусть, например, мы хотим выделить названия магазинов.
В тексте «Вас приветствует Магазин Профессиональных Металлоискателей», мы, почти наверное, хотим включать в нашу сущность слово “магазин” — это явно часть названия.
Другой пример — «Вас приветствует “Волхонка Престиж” — ваш любимый магазин брендов по доступным ценам». Наверное, слово “магазин” не надо включать в аннотацию — это явно не часть названия, а просто его описание. Кроме того, если включить в название это слово, нужно также включать и слова “- ваш любимый”, а этого, пожалуй, совсем не хочется делать.
Третий пример: «Вам пишет магазин зоотоваров “Немо”». Непонятно, является ли “магазин зоотоваров” частью названия или нет. Кажется, в этом примере любой выбор будет адекватным. Однако важно, что этот выбор нам нужно сделать и зафиксировать в инструкции для разметчиков, чтобы во всех текстах такие примеры были размечены одинаково (если этого не сделать, машинное обучение из-за противоречий в разметке неизбежно начнет ошибаться).
Таких пограничных примеров можно придумать много, и, если мы хотим, чтобы разметка была консистентной, все их нужно включить в инструкцию для разметчиков. Даже если примеры сами по себе простые, учесть и исчислить их нужно, а это будет делать инструкцию больше и сложнее.
Ну а чем сложнее инструкция, там более квалифицированные разметчики вам требуются. Одно дело, когда разметчику нужно определить, является ли письмо текстом заказа или нет (хотя и здесь есть свои тонкости и пограничные случаи), а другое дело, когда разметчику нужно вчитываться в 50-страничную инструкцию, найти конкретные сущности, понять, что включать в аннотацию, а что нет.
Квалифицированные разметчики — это дорого, и работают они, обычно, не очень оперативно. Деньги вы потратите точно, но совсем не факт, что получится идеальная разметка, ведь если инструкция сложная, даже квалифицированный человек может ошибиться и что-то неправильно понять. Для борьбы с этим используют многократную разметку одного текста разными людьми, что еще увеличивает цену разметки и время, за которое она готовится. Избежать этого процесса или даже серьезно сократить его не выйдет: чтобы обучаться, нужно иметь качественную обучающую выборку разумных размеров.
Это и есть две основных причины, почему NER еще не завоевал мир и почему яблони до сих пор не растут на Марсе.
Как понять, качественно ли решена задача NER
Расскажу немного про метрики, которыми люди пользуются для оценки качества своего решения задачи NER, и про стандартные корпуса.
Основная метрика для нашей задачи – это строгая f-мера. Объясним, что это такое.
Пусть у нас есть тестовая разметка (результат работы нашей системы) и эталон (правильная разметка тех же текстов). Тогда мы можем посчитать две метрики – точность и полноту. Точность – доля true positive сущностей (т. е. сущностей, выделенных нами в тексте, которые также присутствуют в эталоне), относительно всех сущностей, выделенных нашей системой. А полнота – доля true positive сущностей относительно всех сущностей, присутствующих в эталоне. Пример очень точного, но неполного классификатора – это классификатор, который выделяет в тексте один правильный объект и больше ничего. Пример очень полного, но вообще неточного классификатора – это классификатор, который выделяет сущность на любом отрезке текста (таким образом, помимо всех эталонных сущностей, наш классификатор выделяет огромное количество мусора).
F-мера же – это среднее гармоническое точности и полноты, стандартная метрика.
Как мы рассказали в предыдущем разделе, создавать разметку — дорогое удовольствие. Поэтому доступных корпусов с разметкой не очень много.
Для английского языка есть некоторое разнообразие — есть популярные конференции, на которых люди соревнуются в решении задачи NER (а для проведения соревнований создается разметка). Примеры таких конференций, на которых были созданы свои корпуса с именованными сущностями — MUC, TAC, CoNLL. Все эти корпуса состоят практически исключительно из новостных текстов.
Основной корпус, на котором оценивается качество решения задачи NER — это корпус CoNLL 2003 (вот ссылка на сам корпус, вот статья о нем). Там примерно 300 тысяч токенов и до 10 тысяч сущностей. Сейчас SOTA-системы (state of the art — т. е. наилучшие на данный момент результаты) показывают на этом корпусе f-меру порядка 0,93. Для русского языка все намного хуже. Есть один общедоступный корпус (FactRuEval 2016, вот статья о нем, вот статья на Хабре), и он очень маленький – там всего 50 тысяч токенов. При этом корпус довольно специфичный. В частности, в корпусе выделяется достаточно спорная сущность LocOrg (локация в организационном контексте), которая путается как с организациями, так и с локациями, в результате чего качество выделения последних ниже, чем могло бы быть.
Как решать задачу NER
Сведение задачи NER к задаче классификации
Несмотря на то что сущности часто бывают многословными, обычно задача NER сводится к задаче классификации на уровне токенов, т. е. каждый токен относится к одному из нескольких возможных классов. Есть несколько стандартных способов сделать это, но самый общий из них называется BIOES-схемой. Схема заключается в том, чтобы к метке сущности (например, PER для персон или ORG для организаций) добавить некоторый префикс, который обозначает позицию токена в спане сущности. Более подробно:
B – от слова beginning – первый токен в спане сущности, который состоит из больше чем 1 слова.
I – от словам inside – это то, что находится в середине.
E – от слова ending, это последний токен сущности, которая состоит больше чем из 1 элемента.
S – single. Мы добавляем этот префикс, если сущность состоит из одного слова.
Таким образом, к каждому типу сущности добавляем один из 4 возможных префиксов. Если токен не относится ни к какой сущности, он помечается специальной меткой, обычно имеющей обозначение OUT или O.
Приведем пример. Пусть у нас есть текст “Карл Фридрих Иероним фон Мюнхгаузен родился в Боденвердере”. Здесь есть одна многословная сущность — персона “Карл Фридрих Иероним фон Мюнгхаузен” и одна однословная — локация “Боденвердере”.
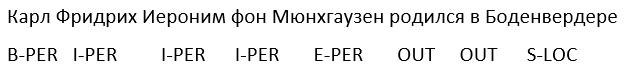
Другой пример вложенных сущностей: “Кафедра математической логики и теории алгоритмов механико-математического факультета МГУ”. Здесь в идеале хотелось бы выделять 3 вложенных организации, но приведенный выше способ разметки позволяет выделить либо 3 непересекающиеся сущности, либо одну сущность, имеющую аннотацией весь приведенный фрагмент.
Кроме стандартного способа свести задачу к классификации на уровне токенов, есть и стандартный формат данных, в котором удобно хранить разметку для задачи NER (а также для многих других задач NLP). Этот формат называется CoNLL-U. Основная идея формата такая: храним данные в виде таблицы, где одна строка соответствует одному токену, а колонки — конкретному типу признаков токена (в т. ч. признаком является и само слово — словоформа). В узком смысле формат CoNLL-U задает, какие именно типы признаков (т. е. колонки) включаются в таблицу — всего 10 типов признаков на каждый токен. Но исследователи обычно рассматривают формат шире и включают те типы признаков, которые нужны для конкретной задачи и метода ее решения. Приведем ниже пример данных в CoNLL-U-подобном формате, где рассмотрены 6 типов признаков: номер текущего предложения в тексте, словоформа (т. е. само слово), лемма (начальная форма слова), POS-таг (часть речи), морфологические характеристики слова и, наконец, метка сущности, выделяемой на данном токене.

А как решали задачу NER раньше?
Строго говоря, задачу можно решать и без машинного обучения — с помощью rule-based систем (в самом простом варианте — с помощью регулярных выражений). Это кажется устаревшим и неэффективным, однако нужно понимать, если у вас ограничена и четко очерчена предметная область и если сущность, сама по себе, не обладает большой вариативностью, то задача NER решается с помощью rule-based методов достаточно качественно и быстро.
Например, если вам нужно выделить емейлы или числовые сущности (даты, денежные суммы или номера телефонов), регулярные выражения могут привести вас к успеху быстрее, чем попытка решить задачу с помощью машинного обучения.
Впрочем, как только в дело вступают языковые неоднозначности разного рода (о части из них мы писали выше), такие простые способы перестают хорошо работать. Поэтому применять их имеет смысл только для ограниченных доменов и на простых и четко отделимых от остального текста сущностях.
Несмотря на все вышесказанное, на академических корпусах до конца 2000-х годов SOTA показывали системы на основе классических методов машинного обучения. Давайте кратко разберем, как они работали.
Признаки
До появления эмбеддингов, главным признаком токена обычно являлась словоформа — т. е. индекс слова в словаре. Таким образом, каждому токену ставится в соответствие булев вектор большой размерности (размерности словаря), где на месте индекса слова в словаре стоит 1, а на остальных местах стоят 0.
Кроме словоформы, в качестве признаков токена часто использовались части речи (POS-таги), морфологические признаки (для языков без богатой морфологии — например, английского, морфологические признаки практически не дают эффекта), префиксы (т. е. несколько первых символов слова), суффиксы (аналогично, несколько последних символов токена), наличие спецсимволов в токене и внешний вид токена.
В классических постановках, очень важным признаком токена является тип его капитализации, например:
- “первая буква большая, остальные маленькие”,
- “все буквы маленькие”,
- “все буквы большие”,
- или вообще “нестандартная капитализация” ( наблюдаемая, в частности, для токена “iPhone”).
Если токен имеет нестандартную капитализацию, про него с большой вероятностью можно сделать вывод, что токен является какой-то сущностью, причем тип этой сущности — вряд ли персона или локация.
Кроме всего этого, активно использовались газетиры – словари сущностей. Мы знаем, что Петя, Елена, Акакий – это имена, Иванов, Руставели, фон Гете – фамилии, а Мытищи, Барселона, Сан Пауло – города. Важно отметить, что словари сущностей сами по себе не решают задачу (“Москва” может быть частью названия организации, а “Елена” — частью локации), но могут улучшить ее решение. Впрочем, конечно, несмотря на неоднозначность, принадлежность токена словарю сущностей определенного типа — это очень хороший и значимый признак (настолько значимый, что обычно результаты решения задачи NER делятся на 2 категории — с использованием газетиров и без них).
Если вам интересно, как люди решали задачу NER, когда деревья были большие, советую посмотреть статью Nadeau and Sekine (2007), A survey of Named Entity Recognition and Classification. Методы, которые там описаны, конечно, устаревшие (даже если вы не можете использовать нейросети из-за ограничений производительности, вы, наверное, будете пользоваться не HMM, как написано в статье, а, допустим, градиентным бустингом), но посмотреть на описание признаков может иметь смысл. К интересным признакам можно отнести шаблоны капитализации (summarized pattern в статье выше). Они до сих пор могут помочь при решении некоторых задач NLP. Так, в 2018 году была успешная попытка применить шаблоны капитализации (word shape) к нейросетевым способам решения задачи.
Как решить задачу NER с помощью нейросетей?
NLP almost from scratch
Первая успешная попытка решить задачу NER с помощью нейросетей была совершена в 2011 году. В момент выхода этой статьи она показала SOTA-результат на корпусе CoNLL 2003. Но нужно понимать, что превосходство модели по сравнению с системами на основе классических алгоритмов машинного обучения было достаточно незначительным. В последующие несколько лет методы на основе классического ML показывали результаты, сравнимые с нейросетевыми методами. Кроме описания первой удачной попытки решить задачу NER с помощью нейростетей, в статье подробно описаны многие моменты, которые в большинстве работ на тему NLP оставляют за скобками. Поэтому, несмотря на то что архитектура нейросети, описанная в статье, устаревшая, со статьей имеет смысл ознакомиться. Это поможет разобраться в базовых подходах к нейросетям, используемых при решении задачи NER (и шире, многих других задач NLP). Расскажем подробнее об архитектуре нейросети, описанной в статье. Авторы вводят две разновидности архитектуры, соответствующие двум различным способам учесть контекст токена:
- либо использовать «окно» заданной ширины (window based approach),
- либо считать контекстом все предложение (sentence based approach).
В обоих вариантах используемые признаки – это эмбеддинги словоформ, а также некоторые ручные признаки – капитализация, части речи и т.д. Расскажем подробнее о том, как они вычисляются.
Мы получили на вход список слов нашего предложения: например, “The cat sat on the mat”.
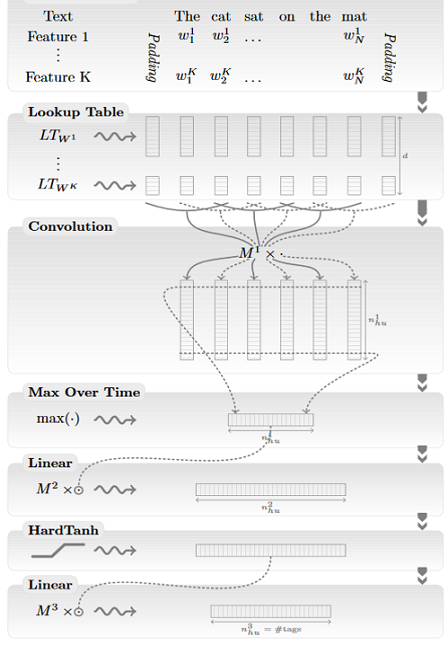
Важно отметить, что в sentence based approach кроме категориальных признаков, определяемых по словам, используется признак — сдвиг относительно токена, метку которого мы пытаемся определить. Значение этого признака для токена номер i будет i-core, где core — номер токена, метку которого мы пытаемся определить в данный момент (этот признак тоже считается категориальным, и вектора для него вычисляются точно так же, как и для остальных).
Следующий этап нахождения признаков токена — умножение каждого
Отличие описанного в этой статье способа работы с категориальными признаками от появившегося позже word2vec (мы рассказывали о том, как предобучаются словоформенные эмбеддинги word2vec, в предыдущей части нашего поста) в том, что здесь матрицы инициализируются случайным образом, а в word2vec матрицы предобучаются на большом корпусе на задаче определения слова по контексту (или контекста по слову).
Таким образом, для каждого токена получен непрерывный вектор признаков, являющийся конкатенацией результатов перемножения всевозможных
Теперь разберемся с тем, как эти признаки используются в sentence based approach (window based идейно проще). Важно, что мы будем запускать нашу архитектуру по отдельности для каждого токена (т. е. для предложения “The cat sat on the mat” мы запустим нашу сеть 6 раз). Признаки в каждом запуске собираются одинаковые, за исключением признака, отвечающего за позицию токена, метку которого мы пытаемся определить — токена core.
Берем получившиеся непрерывные вектора каждого токена и пропускаем их через одномерную свертку с фильтрами не очень большой размерности: 3-5. Размерность фильтра соответствует размеру контекста, который сеть одновременно учитывает, а количество каналов соответствует размерности исходных непрерывных векторов (сумме размерностей эмбеддингов всех признаков). После применения свертки получаем матрицу размерности m на f, где m — количество способов, которыми фильтр можно приложить к нашим данным (т. е. длина предложения минус длина фильтра плюс один), а f — количество используемых фильтров.
Как и почти всегда при работе со свертками, после свертки мы используем пулинг — в данном случае max pooling (т. е. для каждого фильтра берем максимум его значения на всем предложении), после чего получаем вектор размерности f. Таким образом, вся информация, содержащаяся в предложении, которая может нам понадобиться при определении метки токена core, сжимается в один вектор (max pooling был выбран потому, что нам важна не информация в среднем по предложению, а значения признаков на его самых важных участках). Такой “сплюснутый контекст” позволяет нам собирать признаки нашего токена по всему предложению и использовать эту информацию, чтобы определить, какую метку должен получить токен core.
Дальше пропускаем вектор через многослойный персептрон с какими-то функциями активации (в статье — HardTanh), а в качестве последнего слоя используем полносвязный с softmax размерности d, где d — количество возможных меток токена.
Таким образом сверточный слой позволяет нам собрать информацию, содержащуюся в окне размерности фильтра, пулинг — выделить самую характерную информацию в предложении (сжав ее в один вектор), а слой с softmax — позволяет определить, какую же метку имеет токен номер core.
CharCNN-BLSTM-CRF
Поговорим теперь о архитектуре CharCNN-BLSTM-CRF, то есть о том, что было SOTA в период 2016-2018 (в 2018 появились архитектуры на основе эмбеддингов на языковых моделях, после которых мир NLP уже никогда не будет прежним; но эта сага не об этом). В применении к задаче NER архитектура впервые была описана в статьях Lample et al (2016) и Ma & Hovy (2016). Первые слои сети такие же, как в пайплайне NLP, описанном в предыдущей части нашего поста. Сначала вычисляется контекстно-независимый признак каждого токена в предложении. Признаки обычно собираются из трех источников. Первый – словоформенный эмбеддинг токена, второй – символьные признаки, третий — дополнительные признаки: информация про капитализацию, часть речи и т. п. Конкатенация всех этих признаков и составляет контекстно-независимый признак токена. Про словоформенные эмбеддинги мы подробно говорили в предыдущей части. Дополнительные признаки мы перечислили, но мы не говорили, как именно они встраиваются в нейросеть. Ответ простой — для каждой категории дополнительных признаков мы с нуля учим эмбеддинг не очень большого размера. Это в точности Lookup-таблицы из предыдущего параграфа, и учим их мы точно так же, как описано там. Теперь расскажем, как устроены символьные признаки. Ответим сначала на вопрос, что это такое. Все просто — мы хотим для каждого токена получать вектор признаков константного размера, который зависит только от символов, из которых состоит токен (и не зависит от смысла токена и дополнительных атрибутов, таких как часть речи).
Перейдем теперь к описанию архитектуры CharCNN (а также, связанной с ней архитектуры CharRNN). Нам дан токен, который состоит из каких-то символов. На каждый символ мы будем выдавать вектор какой-то не очень большой размерности (например, 20) — символьный эмбеддинг. Символьные эмбеддинги можно предобучать, однако чаще всего они учатся с нуля — символов даже в не очень большом корпусе много, и символьные эмбеддинги должны адекватно обучиться.
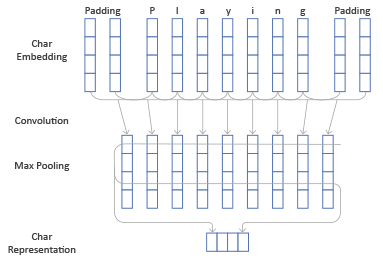
Второй способ превратить символьные эмбеддинги в один вектор – подавать их в двустороннюю рекуррентную нейросеть (BLSTM или BiGRU; что это такое, мы описывали в первой части нашего поста). Обычно символьным признаком токена является просто конкатенация последних состояний прямого и обратного RNN. Итак, пусть нам дан контекстно-независимый вектор признаков токена. По нему мы хотим получить контекстно-зависимый признак.
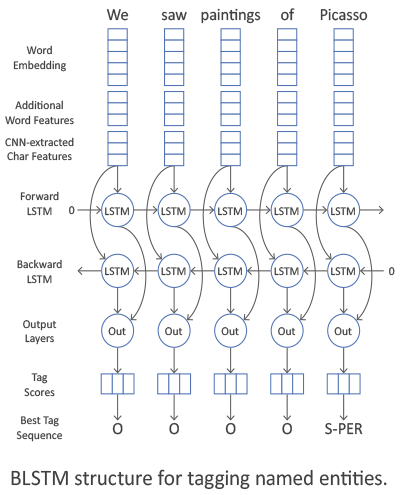
Этот способ работает, однако обладает существенным недостатком — метка токена вычисляется независимо от меток других токенов. Сами соседние токены мы учитываем за счет BiRNN, но метка токена зависит не только от соседних токенов, но и от их меток. Например, вне зависимости от токенов метка I-PER встречается только после B-PER или I-PER.
Стандартный способ учесть взаимодействие между типами меток — использовать CRF (conditional random fields). Мы не будем подробно описывать, что это такое (вот здесь дано хорошее описание), но упомянем, что CRF оптимизирует всю цепочку меток целиком, а не каждый элемент в этой цепочке. Итак, мы описали архитектуру CharCNN-BLSTM-CRF, которая являлась SOTA в задаче NER до появления эмбеддингов на языковых моделях в 2018 году. В заключение поговорим немного о значимости каждого элемента архитектуры. Для английского языка CharCNN дает прирост f-меры приблизительно на 1%, CRF — на 1-1.5%, а дополнительные признаки токена к улучшению качества не приводят (если не использовать более сложные техники типа multi-task learning, как в статье Wu et al (2018)). BiRNN — основа архитектуры, которая, однако, может быть заменена трансформером.
Надеемся, что нам удалось дать читателям некоторое представление о задаче NER. Хотя это задача важная, она достаточно простая, что и позволило нам описать ее решение в рамках одного поста.
Иван Смуров,
руководитель NLP Advanced Research Group
Телеграм: t.me/ainewsline
Источник: habr.com