Как сократить размер нейросети на 10-20% и не проиграть в точности
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2019-05-22 03:42

На ICLR 2019 исследователи из MIT представили метод, с помощью которого можно уменьшить размер нейросети на 10-20% и не потерять при этом в точности модели. Исследователи вводят “гипотезу о выигрышных билетах”: плотные, случайно инициализированные полносвязные нейросети содержат подсети, которые при обучении отдельно достигают точности, сравнимой с точностью полной сети. Такие сети исследователи называют “выигрышными билетами”.
На текущий момент нейросетевые архитектуры обучаются с избыточным количеством параметров. По окончании обучения модели остается часть параметров, которые вносят минимальный вклад в предсказание целевой переменной. Иногда размер общего количество параметров модели превышает размер обучающей выборки.
Как определять “выигрышные билеты”
Исследователи предлагают, вместо сокращения размерности сети после обучения, метод, который позволяет на этапе обучения модели сокращать ее размер.
Пайплайн поиска тех параметров сети, которые оказывают наибольшее влияние при обучении модели:
- Инициализируйте параметры нейросети случайно;
- Обучите сеть N итераций;
- Обрежьте часть параметров сети (при этом создается маска);
- Оставшуюся часть параметров сети обновите до начального состояния, когда они задавались случайно
Результаты
Для проверки гипотезы исследователи протестировали поиск эффективных подсетей в полносвязных архитектурах на MNIST и в сверточных архитектурах на CIFAR10. При этом были использованы несколько оптимизаторов: SGD, momentum и Adam, — и такие техники, как дропаут, residual connections и нормализация батча. В более сложных сетях техника обрезания части параметров будет более чувствительна к параметру скорости обучения.
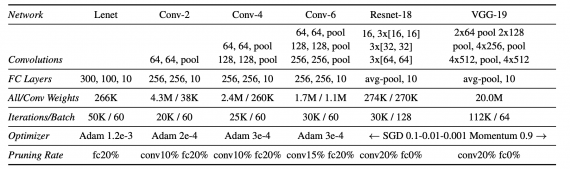
В итоге исследователям удается найти “выигрышные билеты”, которые содержат на 10-20% меньше параметров, чем оригинальная нейросеть.
Будущие направления исследований
Можно выделить три актуальных направления в исследовании оптимизации размера нейросети:
- В работе был предложен грубый подход к определению эффективных подсетей: тренируем и обрезаем параметры оригинальной нейросети на одном датасете, чтобы использовать эффективную подсеть при обучении на другом датасете. Вопрос в том, есть ли более эффективный способ определять эффективную подсеть в самом начале обучения нейросети?
- Есть ли ограничения в обучении на “выигрышных билетах”: будет ли использование эффективной подсети на другой задаче влиять на точность модели?
- Насколько маленьким может быть количество параметров нейросети, чтобы это не влияло на точность модели?
Телеграм: t.me/ainewsline
Источник: neurohive.io