Data Science — 8 главных библиотек для Python программиста
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2019-05-31 15:32

Data science, или наука о данных, набирает все большую популярность среди самых востребованных профессий современного рынка. Специалист в этой области должен обладать глубокими разносторонними знаниями, как теоретическими, так и практическими. К услугам начинающих аналитиков данных предлагаются инструменты автоматизированного характера с уже заложенным функционалом, как, например, мощное программное обеспечение Weka. Однако, многие data scientist-ы, предпочитая широту и манёвренность действий, создают собственные инструменты и пайплайны. Язык программирования Python как нельзя лучше подходит для этих целей. Возможности Python позволяют написать программу для задач машинного обучения как с чистого листа, так и с использованием различных библиотек и инструментов. О последних мы и поговорим.
Обработка больших данных с помощью библиотек Pandas, CSV и OpenPyXL
Чаще всего в задачах для бизнеса исходные данные предоставляются в формате .xlsx или .xlsm, однако многие предпочитают формат .csv (файлы, в которых каждая строка представлена полями, разделенными каким-либо знаком — обычно запятой или точкой с запятой).
Библиотека Pandas — один из самых популярных инструментов Python для работы с данными, она поддерживает различные текстовые, бинарные и sql форматы файлов, в том числе .xlsx, .xls и .csv. Для работы с файлами Excel Pandas использует модули xlrd и xlwt.
Модуль CSV содержит утилиты для работы исключительно с csv-файлами. Однако, детали нотации создания csv-файлов в разных программах могут различаться (как, например, в Excel), и модуль CSV позволяет корректно читать большинство различных реализаций .csv без необходимости учитывать, какой программой и как был сгенерирован файл.
OpenPyXL — это библиотека для работы исключительно с Excel-файлами, такими как .xlsx, .xlsm, .xltx, .xltm для версий Excel от 2010 года и новее. OpenPyXL содержит инструменты для чтения, записи и обработки данных указанных форматов, а также для построения графиков.
Разберем на примерах базовые возможности этих инструментов. Мы будем использовать данные с портала Kaggle об участниках Олимпийских игр за 120 лет.
Считываем данные
Python
| 1 2 3 | importpandas aspd data=pd.read_excel("athlete_events2.xlsx") |
или
Python
| 1 | data2=pd.read_csv("athlete_events.csv") |
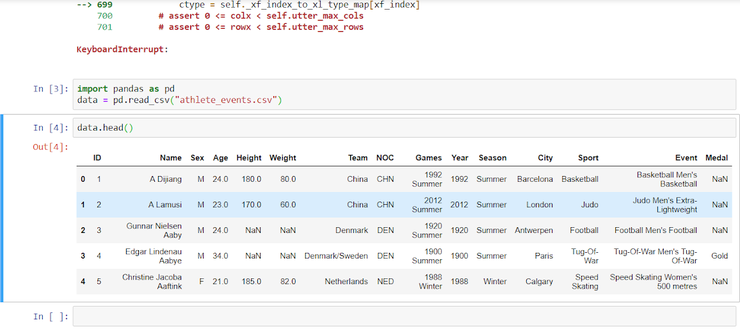
Получим таблицу такого вида:
Python
| 1 | data2.head() |
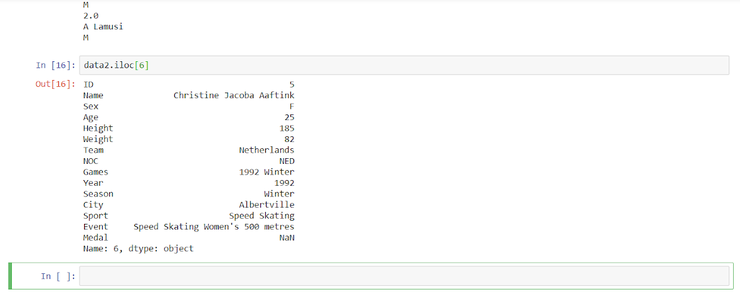
Обращаться к ячейками можно по индексу:
Python
| 1 | data2.iloc[6] |
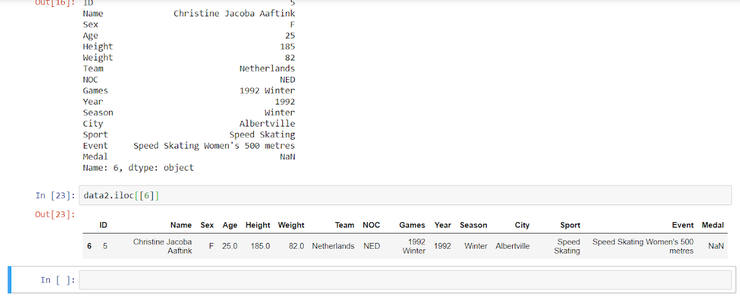
Python
| 1 | data2.iloc[[6]]] |
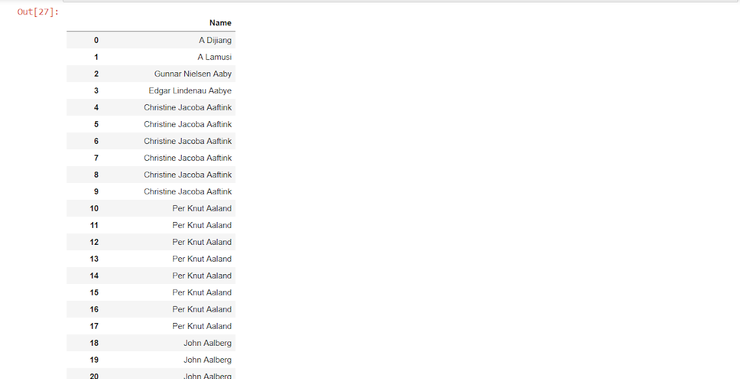
Или по названию столбца:
Python
| 1 | data2[['Name']] |
Несколько строк в Pandas можно выделить через двоеточие:
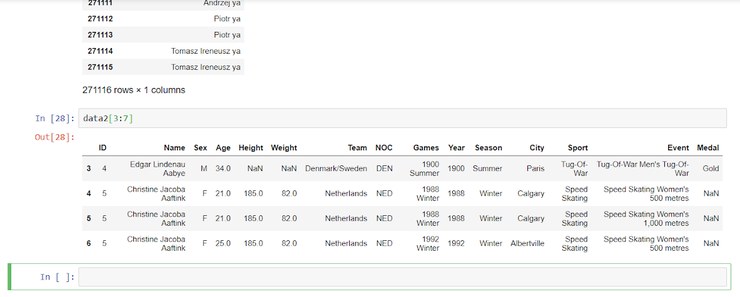
Python
| 1 | data2[3:7] |
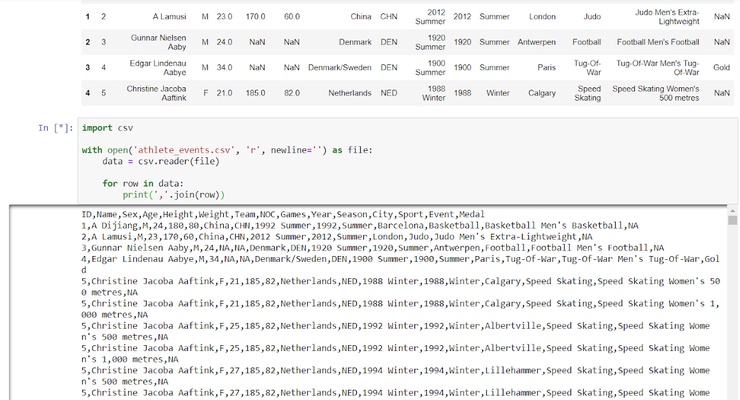
Теперь откроем файлы с помощью библиотек CSV и OpenPyXL:
Python
| 1 2 3 4 | importcsv withopen('athlete_events.csv','r',newline='')asfile: data3=csv.reader(file) |
Однако, вывод при таком считывании придется делать обычным для Python способом, либо, например, подключать структуру data frame из Pandas. В нашем случае получаем длинный текст такого вида:
Python
| 1 2 | forrow indata3: print(','.join(row)) |
Python
| 1 2 | importopenpyxl open_data=openpyxl.load_workbook('athlete_events2.xlsx') |
Переменная open_data содержит объект класса рабочей книги excel со всеми существующими листами. Метод open_data.get_sheet_names() возвращает названия листов, которые можно использовать в дальнейшем для обращения к данным. Наши данные представлены только на одном листе:
Python
| 1 2 | names=open_data.get_sheet_names() print(names) |
Результат:
Python
| 1 | ['Лист1'] |
Python
| 1 | sheet=open_data.get_sheet_by_name('Лист1') |
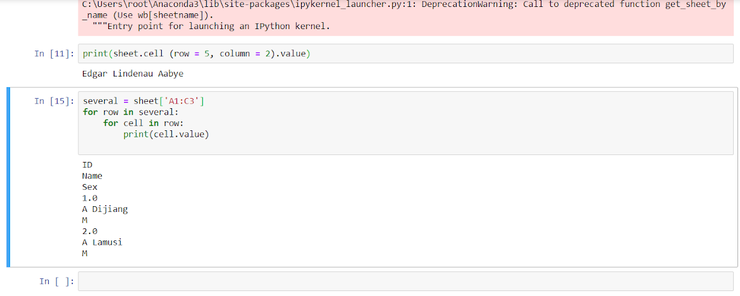
Посмотрим значение ячейки на пересечении 2-ого столбца и 5-ой строки:
Python
| 1 | print(sheet.cell(row=5,column=2).value) |
Результат:
Python
| 1 | Edgar Lindenau Aabye |
Возьмем диапазон ячеек данного листа и отобразим значения:
Python
| 1 2 3 4 | several=sheet[‘A1:C3’] forrow inseveral: forcell inrow: print(cell.value) |
Запишем извлечённые данные в файлы .xlsx и .csv.
Pandas
Python
| 1 2 | data2.to_csv("new_file1.csv",sep=',',index=False,header=False) data2.to_excel("new_file2.xlsx",index=False) |
CVS
Python
| 1 2 3 4 | withopen("new_file3.csv","w",newline='')asfile: writer=csv.writer(file,delimiter=';') forline indata3: writer.writerow(line) |
OpenPyXL
Python
| 1 | open_data.save("new_file4.xlsx") |
Matplotlib и Seaborn — Визуализация данных
Библиотеку Matplotlib написал Джон Хантер для создания различных графиков и работы с изображениями. Seaborn — как бы «надстройка» над Matplotlib, которая при всем функционале библиотеки Matplotlib предоставляет лучшую графику и большее количество возможностей её настройки.
Рассмотрим применение этих библиотек на выборке (8000 образцов) из датасета об участниках олимпиады.
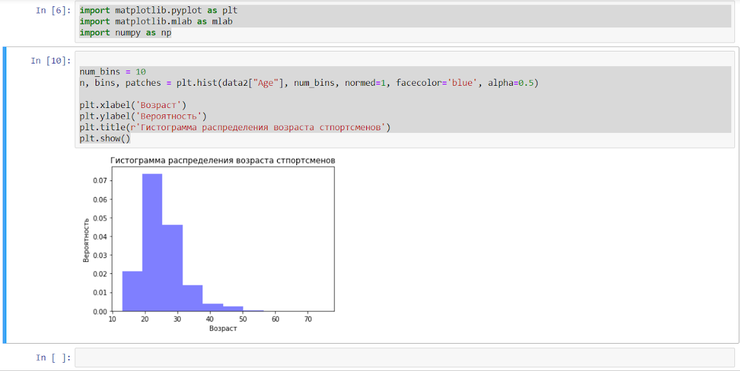
Построим гистограмму распределения возрастов участников олимпиады:
Python
| 1 2 3 4 5 6 7 8 9 10 | importmatplotlib.pyplot asplt importnumpy asnp num_bins=10 n,bins,patches=plt.hist(data2["Age"],num_bins,normed=1,facecolor='blue',alpha=0.5) plt.xlabel('Возраст') plt.ylabel('Вероятность') plt.title(r'Гистограмма распределения возраста спортсменов') plt.show() |
И сделаем это же с помощью библиотеки Seaborn:
Python
| 1 2 3 4 | importseaborn assns data2.Age.values sns.distplot(data2.Age.dropna()) |
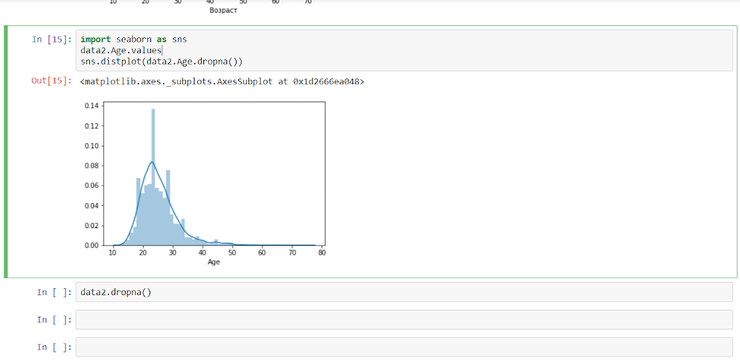
Как видно из этого примера, код при использовании библиотеки Seaborn выглядит намного короче и лаконичнее, к тому же distplot содержит много параметров по умолчанию, один из которых — построение кривой распределения (синяя линия на последнем графике), в то время как в Matplotlib её необходимо задавать отдельно (что требует ещё пары строчек кода и импорта дополнительного модуля из библиотеки).
С другой стороны, Matplotlib дает большую манёвренность в плане стиля и надстроек над базовым графиком, поэтому возможности Matplotlib часто используются в совокупности с функциями модуля Seaborn.
Python
| 1 2 3 4 | plt.figure(figsize=(20,10)) sns.countplot(x=data2.Age,data=data2) plt.xticks(rotation=-45) plt.savefig("plot.png") |
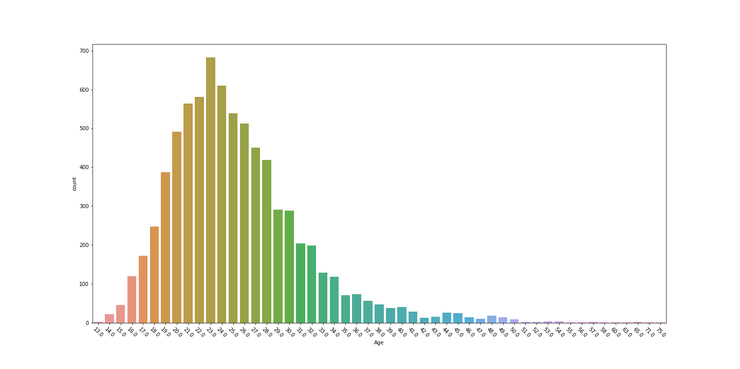
С помощью средств Matplotlib мы сделали график заданного размера (figsize), повернули значение возраста на 45 градусов и сохранили картинку на компьютер.
Машинное обучение в SciKit-Learn
SciKit-Learn — это свободно распространяемая библиотека для работы с методами машинного обучения на Python. Она содержит реализации методов классификации, регрессии и кластеризации, а также нейронных сетей. SciKit предоставляет широкий набор инструментов для решения проблемы размерности данных, сравнения моделей машинного обучения и их производительности и для извлечения важных признаков.
Рассмотрим реализацию линейной регрессии, например, для проверки гипотезы о том, что вес спортсмена и его возраст взаимосвязаны.
Python
| 1 2 | fromsklearn.linear_model importLinearRegression importnumpy asnp |
После импортирования необходимых библиотек избавимся от отсутствующих значений типа NA самым простым (но не самым лучшим) способом: удалим все строки, в которых в каком-либо столбце присутствуют NA:
Python
| 1 | data2=data2.dropna(axis=0) |
Зададим переменные для модели, зависимость которых мы собираемся исследовать:
Python
| 1 2 3 | x=np.array(data2.Age.values) y=np.array(data2.Weight.values) x=x.reshape((-1,1)) |
Построим модель:
Python
| 1 2 3 | model=LinearRegression() model.fit(x,y) model=LinearRegression().fit(x,y) |
И подсчитаем коэффициент линейной регрессии, чтобы оценить эффективность модели:
Python
| 1 2 | r_sq=model.score(x,y) print('coefficient of determination:',r_sq) |
Результат:
Python
| 1 | coefficient of determination:0.024385595989105727 |
Коэффициент детерминации (или R2) очень низкий (для приемлемой модели он должен быть не менее 0,5), а значит, либо предобработка данных не была проведена должным образом (что верно, так как мы не учитывали разброс данных и другие характеристики), либо метод линейной регрессии в этом случае не подходит, и возраст и вес спортсменов никак не связаны (что тоже возможно).
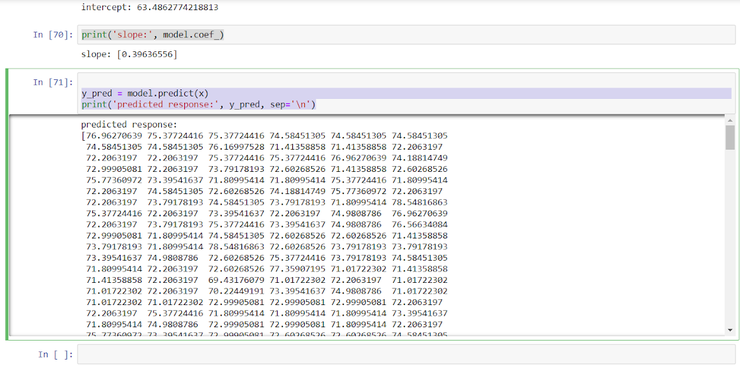
Для наглядности мы можем предсказать значение веса по возрасту, но как мы только что выяснили, доверять этой модели не стоит.
Python
| 1 2 | y_pred=model.predict(x) print('predicted response:',y_pred,sep=' ') |
Генераторы и Lambda-функции — «фишки» языка Python
Запутанные на первый взгляд, два этих инструмента Python полезны в любой из областей программирования, в том числе и в data science. Новички изучают их на курсах программирования на Python, например, на «Курсе по Python для веб-разработки полного цикла» в Skillfactory, но недооценивают лаконичность и эффективность этих методов.
Каждый, кто хоть раз пробовал запрограммировать последовательность действий, знает, что для этого нужно использовать цикл for или while.
Например, привычная реализация заполнения списка символами из строки на Python будет выглядеть так:
Python
| 1 2 3 4 5 6 7 8 | string="123456erert,42,;432EkRRPPEW254" spisok=[] forel instring: y=el*2 spisok.append(y) print(spisok) |
Результат:
Python
| 1 | ['11','22','33','44','55','66','ee','rr','ee','rr','tt',',,','44','22',',,',';;','44','33','22','EE','kk','RR','RR','PP','PP','EE','WW','22','55','44'] |
Генераторы позволяют записать данную операцию в одну строчку:
Python
| 1 2 | spisok=[el*2forel instring] print(spisok) |
Результат:
Python
| 1 | ['11','22','33','44','55','66','ee','rr','ee','rr','tt',',,','44','22',',,',';;','44','33','22','EE','kk','RR','RR','PP','PP','EE','WW','22','55','44'] |
Для более сложных примеров генераторы бывают весьма полезны и удобны.
Lambda-функции применяются с той же целью — сократить код — для функций. В случае, если функция содержит одну операцию или одно общее выражение, lambda-конструкция позволяет создать функцию без создания функции. Выглядит запутанно, поэтому разберём простейший пример. Допустим, мы хотим посчитать количество элементов списка:
Python
| 1 2 3 4 | defelements(list1): returnlen(list1) print(elements(spisok)) |
Результат:
Python
| 1 | 30 |
Теперь сделаем то же самое с помощью lambda:
Python
| 1 2 | elements=lambdax:len(x) print(elements(spisok)) |
Результат:
Python
| 1 | 30 |
Мы рассмотрели только 8 средств языка Python: и профессиональные библиотеки, и инструменты, которые пригодятся любому программисту для работы с данными. Для знакомства с широтой возможностей языка Python вы можете прослушать любой из курсов SkillFactory и углубиться в интересное для вас направление, если что-то покажется особенно интересным.
Телеграм: t.me/ainewsline
Источник: python-scripts.com